신중한 고려 끝에 Amazon Kinesis Data Analytics for SQL 애플리케이션을 중단하기로 결정했습니다.
1. 2025년 9월 1일부터 Amazon Kinesis Data Analytics for SQL 애플리케이션에 대한 버그 수정은 제공되지 않습니다. 향후 중단될 예정이므로 지원이 제한되어 있기 때문입니다.
2. 2025년 10월 15일부터 새 Kinesis Data Analytics for SQL 애플리케이션을 생성할 수 없습니다.
3. 2026년 1월 27일부터 애플리케이션이 삭제됩니다. Amazon Kinesis Data Analytics for SQL 애플리케이션을 시작하거나 작동할 수 없게 됩니다. 그 시점부터 Amazon Kinesis Data Analytics for SQL에 대한 지원을 더 이상 이용할 수 없습니다. 자세한 내용은 Amazon Kinesis Data Analytics for SQL 애플리케이션 단종 단원을 참조하십시오.
기계 번역으로 제공되는 번역입니다. 제공된 번역과 원본 영어의 내용이 상충하는 경우에는 영어 버전이 우선합니다.
Amazon Kinesis Data Analytics for SQL 애플리케이션: 작동 방식
참고
2023년 9월 12일 이후에는 Kinesis Data Analytics for SQL의 기존 사용자가 아닌 경우, Kinesis Data Firehose를 소스로 사용하여 새 애플리케이션을 생성할 수 없습니다. 자세한 설명은 한도를 참조하십시오.
Amazon Kinesis Data Analytics에서 애플리케이션은 사용자 계정에서 생성할 수 있는 기본 리소스입니다. AWS Management Console 또는 Kinesis Data Analytics API를 사용하여 애플리케이션을 생성하고 관리할 수 있습니다. Kinesis Data Analytics는 애플리케이션 관리용 API 작업을 제공합니다. API 작업 목록은 작업 섹션을 참조하십시오.
Kinesis Data Analytics 애플리케이션은 실시간으로 스트리밍 데이터를 연속적으로 읽고 처리합니다. 수신 스트리밍 데이터를 처리하고 출력을 생성하도록 사용자가 SQL을 사용하여 애플리케이션 코드를 작성합니다. 그러면, Kinesis Data Analytics가 출력을 구성 목적지에 작성합니다. 다음 다이어그램은 일반적인 애플리케이션 아키텍처를 보여 줍니다.
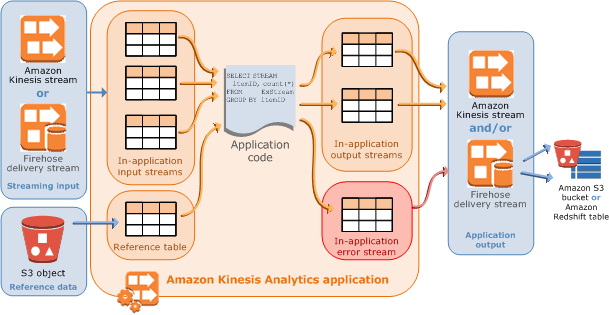
각 애플리케이션은 명칭, 설명, 버전 ID 및 상태를 갖습니다. 애플리케이션을 처음 생성하면 Amazon Kinesis Data Analytics가 버전 ID를 할당합니다. 임의의 애플리케이션 구성을 업데이트하면 이 버전 ID도 업데이트됩니다. 예를 들어 입력 구성을 추가하거나, 참조 데이터 소스를 추가 또는 삭제하거나, 출력 구성을 추가 또는 삭제하거나, 애플리케이션 코드를 업데이트하면 Kinesis Data Analytics 가 현재 애플리케이션 버전 ID를 업데이트합니다. 또한 Kinesis Data Analytics는 애플리케이션이 생성되고 마지막으로 업데이트된 시기에 대한 타임스탬프를 유지합니다.
이러한 기본 속성에 더해, 각 애플리케이션은 다음으로 구성됩니다:
-
입력 – 애플리케이션의 스트리밍 소스입니다. Kinesis 데이터 스트림 또는 Firehose 데이터 전송 스트림을 스트리밍 소스로 선택할 수 있습니다. 입력 구성에서 스트리밍 소스를 애플리케이션 내 입력 스트림에 매핑합니다. 애플리케이션 내 스트림은 지속적으로 업데이트되는 표와 같습니다. 이 표에서
SELECT및INSERT SQL작업을 수행할 수 있습니다. 중간 쿼리 결과를 저장하도록 애플리케이션 코드에서 애플리케이션 내 스트림을 추가로 생성할 수 있습니다.선택적으로 스트리밍 소스를 복수의 애플리케이션 내 스트림에 분할하여 처리량을 향상시킬 수 있습니다. 자세한 정보는 한도 및 애플리케이션 입력 구성 섹션을 참조하십시오.
Amazon Kinesis Data Analytics는 각 애플리케이션 스트림 내에 타임스탬프와 ROWTIME 열이라는 타임스탬프 열을 제공합니다. 시간 기반 윈도우 쿼리에서 이 열을 사용할 수 있습니다. 자세한 설명은 윈도우 모드 쿼리 섹션을 참조하십시오.
선택적으로 참조 데이터 소스를 구성하여 애플리케이션 내에서의 입력 데이터 스트림을 보강할 수 있습니다. 그 결과물이 애플리케이션 내 참조 표입니다. 참조 데이터는 S3 버킷에 객체로 저장해야 합니다. 애플리케이션이 시작하면 Amazon Kinesis Data Analytics이 Amazon S3 객체를 읽고 애플리케이션 내 표를 생성합니다. 자세한 설명은 애플리케이션 입력 구성 섹션을 참조하십시오.
-
애플리케이션 코드 – 입력을 처리하고 출력을 생산하는 일련의 SQL 문입니다. 애플리케이션 내 스트림과 참조 표에 대해 SQL 문을 작성할 수 있습니다. JOIN 쿼리를 작성하여 이 두 소스의 데이터를 결합할 수도 있습니다.
Kinesis Data Analytics에서 지원되는 SQL 언어 요소에 대한 자세한 설명은 Amazon Kinesis Data Analytics SQL 참조를 참고하십시오.
가장 간단한 형태의 애플리케이션 코드는 스트리밍 입력에서 선택하여 결과를 스트리밍 출력에 삽입하는 단일 SQL 문이 될 수 있습니다. 또한, 하나의 출력이 다음 SQL 문의 입력으로 공급되는 일련의 SQL 문이 될 수도 있습니다. 뿐만 아니라 입력 스트림을 여러 스트림으로 분할하는 애플리케이션 코드를 작성할 수 있습니다. 그런 다음 추가 쿼리를 적용하여 이러한 스트림을 처리할 수 있습니다. 자세한 설명은 애플리케이션 코드 섹션을 참조하십시오.
-
출력 – 애플리케이션 내 코드에서 쿼리 결과가 애플리케이션 내 스트림으로 향합니다. 중간 결과를 보관하도록 애플리케이션 코드에서 하나 이상의 애플리케이션 내 스트림을 추가로 생성할 수 있습니다. 그런 다음 애플리케이션 출력(애플리케이션 내 출력 스트림이라고도 함)을 외부 대상에 보관하는 애플리케이션 내 스트림에 데이터를 유지하도록 애플리케이션 출력을 선택적으로 구성할 수 있습니다. 외부 대상은 Kinesis 데이터 스트림 또는 Firehose 전송 스트림이 될 수 있습니다. 이러한 목적지에 대해 다음을 참조하십시오:
-
Amazon S3, Amazon Redshift 또는 Amazon OpenSearch Service (OpenSearch Service)에 결과를 작성하도록 Firehose 전송 스트림을 구성할 수 있습니다.
-
애플리케이션 출력을 Amazon S3 또는 Amazon Redshift로 맞춤 목적지로 할 수도 있습니다. 이렇게 하려면 출력 구성에서 Kinesis 데이터 스트림을 목적지로 지정해야 합니다. 그런 다음 스트림을 폴링하고 Lambda 함수를 호출 AWS Lambda 하도록를 구성합니다. 사용자의 Lambda 함수 코드는 스트림 데이터를 입력으로 수신합니다. Lambda 함수 코드에서 수신 데이터를 맞춤 대상에 작성할 수 있습니다. 자세한 내용은 Amazon Kinesis Data Analytics AWS Lambda 에서 사용을 참조하세요.
자세한 내용은 애플리케이션 출력 구성 단원을 참조하십시오.
-
또한 다음 사항에 유의하십시오:
-
Amazon Kinesis Data Analytics는 스트리밍 소스로부터 오는 레코드를 읽고 애플리케이션 출력을 외부 대상에 작성할 수 있는 권한이 필요합니다. IAM 역할을 사용하여 그와 같은 권한을 부여합니다.
-
Kinesis Data Analytics는 각 애플리케이션의애플리케이션 내 오류 스트림을 자동으로 제공합니다. 애플리케이션이 특정 레코드를 처리하는 동안 문제가 발생할 경우(예: 유형 불일치 또는 지연 도착) 해당 레코드는 오류 스트림에 작성됩니다. 추가 평가를 위해 오류 스트림 데이터가 외부 목적지 향하도록 애플리케이션 출력을 Kinesis Data Analytics로 가도록 구성할 수 있습니다. 자세한 설명은 오류 처리 섹션을 참조하십시오.
-
Amazon Kinesis Data Analytics는 애플리케이션 출력 레코드가 구성 목적지에 작성되도록 합니다. 애플리케이션 중단을 경험하더라도 '최소 1회' 처리 및 전송 모델을 사용합니다. 자세한 설명은 애플리케이션 출력을 외부 대상에 유지하기 위한 전송 모델 섹션을 참조하십시오.
