기계 번역으로 제공되는 번역입니다. 제공된 번역과 원본 영어의 내용이 상충하는 경우에는 영어 버전이 우선합니다.
외부 메타스토어를 사용하는 데이터세트에 대한 권한 관리
AWS Glue Data Catalog 메타데이터 페더레이션(데이터 카탈로그 페더레이션)을 사용하면 Amazon S3 데이터에 대한 메타데이터를 저장하는 외부 메타스토어에 데이터 카탈로그를 연결하고를 사용하여 데이터 액세스 권한을 안전하게 관리할 수 있습니다 AWS Lake Formation. 외부 메타스토어의 메타데이터를 데이터 카탈로그로 마이그레이션할 필요는 없습니다.
데이터 카탈로그는 서로 다른 시스템에서 데이터를 더 쉽게 관리하고 검색할 수 있도록 중앙 집중식 메타데이터 리포지토리를 제공합니다. 조직에서 데이터 카탈로그의 데이터를 관리할 때 AWS Lake Formation 를 사용하여 Amazon S3의 데이터 세트에 대한 액세스를 제어할 수 있습니다.
참고
현재는 Apache Hive(버전 3 이상) 메타스토어 페더레이션만 지원합니다.
데이터 카탈로그 페더레이션을 설정하기 위해에서 GlueDataCatalogFederation-HiveMetastore
참조 구현은 AWS Glue Data Catalog 페더레이션 - Hive 메타스토어
AWS SAM 애플리케이션은 데이터 카탈로그를 Hive 메타스토어에 연결하는 데 필요한 다음 리소스를 생성하고 배포합니다.
AWS Lambda 함수 - 데이터 카탈로그와 Hive 메타스토어 간에 통신하는 페더레이션 서비스의 구현을 호스팅합니다.는이 Lambda 함수를 AWS Glue 호출하여 Hive 메타스토어에서 메타데이터 객체를 검색합니다.
Amazon API Gateway - 모든 호출을 Lambda 함수로 라우팅하는 프록시 역할을 하는 Hive 메타스토어의 연결 엔드포인트입니다.
IAM 역할 - 데이터 카탈로그와 Hive 메타스토어 간의 연결을 생성하는 데 필요한 권한이 있는 역할입니다.
AWS Glue 연결 - Amazon API Gateway 엔드포인트와 엔드포인트를 호출할 IAM 역할을 저장하는 AWS Glue 연결 Amazon API Gateway 유형입니다.
테이블을 쿼리할 때 AWS Glue 서비스는 Hive 메타스토어를 런타임 호출하고 메타데이터를 가져옵니다. Lambda 함수는 Hive 메타스토어와 데이터 카탈로그 간의 변환기 역할을 합니다.
연결을 설정한 후 Hive 메타스토어의 메타데이터를 데이터 카탈로그와 동기화하려면, Hive 메타스토어 연결 세부 정보를 사용하여 데이터 카탈로그에 페더레이션형 데이터베이스를 생성하고 이 데이터베이스를 Hive 데이터베이스에 매핑해야 합니다. 데이터베이스가 데이터 카탈로그 외부의 항목을 가리키는 경우 이러한 데이터베이스를 페더레이션형 데이터베이스라고 합니다.
페더레이션 데이터베이스에서 태그 기반 액세스 제어 및 명명된 리소스 방법을 사용하여 Lake Formation 권한을 적용하고 AWS 계정여러, AWS Organizations및 조직 단위(OUs. 페더레이션형 데이터베이스를 다른 계정의 IAM 보안 주체와 직접 공유할 수도 있습니다.
외부 Hive 테이블의 Lake Formation 데이터 필터를 사용하여 열 수준, 행 수준 및 셀 수준에서 세분화된 권한을 정의할 수 있습니다. Amazon Athena, Amazon Redshift 또는 Amazon EMR을 사용하여 Lake Formation 관리형 외부 Hive 테이블을 쿼리할 수 있습니다.
교차 계정 데이터 공유 및 데이터 필터링에 대한 자세한 내용은 다음을 참조하세요.
데이터 카탈로그 메타데이터 페더레이션 상위 단계
-
AWS SAM 애플리케이션을 배포하고 페더레이션형 데이터베이스를 생성할 수 있는 적절한 권한이 있는 IAM 사용자 및 역할을 생성합니다.
-
외부 Hive 메타스토어를 사용하는 데이터세트에 대한
Enable Data Catalog federation옵션을 선택하여 Lake Formation에 Amazon S3 데이터 위치를 등록합니다. AWS SAM 애플리케이션 설정(AWS Glue 연결 이름, Hive 메타스토어에 대한 URL 및 Lambda 함수 파라미터)을 구성하고 AWS SAM 애플리케이션을 배포합니다.
-
AWS SAM 애플리케이션은 외부 Hive 메타스토어를 데이터 카탈로그와 연결하는 데 필요한 리소스를 배포합니다.
-
Hive 데이터베이스 및 테이블에 Lake Formation 권한을 적용하려면 Hive 메타스토어 연결 세부 정보를 사용하여 데이터 카탈로그에서 데이터베이스를 생성하고 이 데이터베이스를 Hive 데이터베이스에 매핑합니다.
사용자 계정 또는 다른 계정의 보안 주체에 페더레이션형 데이터베이스에 대한 권한을 부여합니다.
참고
Lake Formation 권한을 적용하지 않고도 데이터 카탈로그를 외부 Hive 메스타스토어에 연결하고, 페더레이션형 데이터베이스를 생성하고, Hive 데이터베이스 및 테이블에서 쿼리 및 ETL 스크립트를 실행할 수 있습니다. Lake Formation에 등록되지 않은 Amazon S3의 소스 데이터의 경우 액세스는 Amazon S3 및 AWS Glue 작업에 대한 IAM 권한 정책에 따라 결정됩니다.
제한 사항은 Hive 메타데이터 스토어 데이터 공유 고려 사항 및 제한 사항 섹션을 참조하세요.
워크플로
다음 다이어그램은를 외부 Hive 메타스토어에 연결하는 워크플로 AWS Glue Data Catalog 를 보여줍니다.
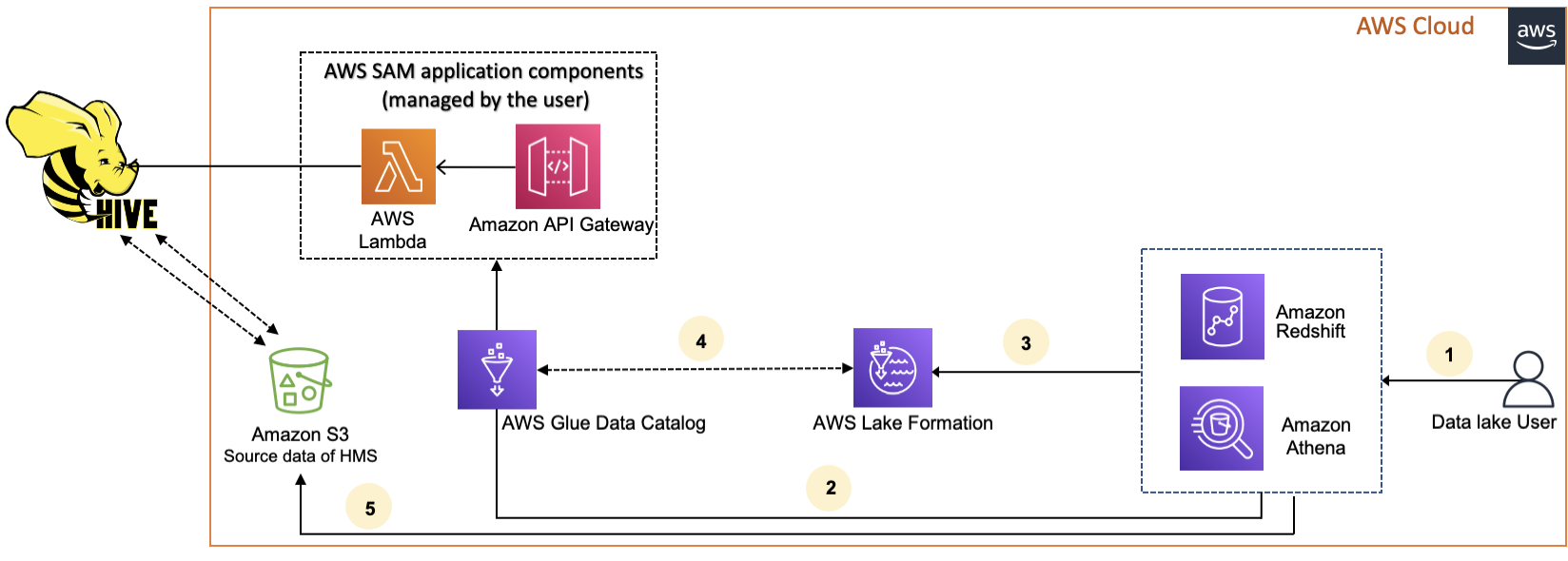
-
보안 주체는 Athena 또는 Redshift Spectrum과 같은 통합 서비스를 사용하여 쿼리를 제출합니다.
통합 서비스는 메타데이터에 대해 데이터 카탈로그를 호출하고, 그러면 뒤에 있는 Hive 메타스토어 엔드포인트를 호출 Amazon API Gateway하고 메타데이터 요청에 대한 응답을 수신합니다.
-
통합 서비스는 Lake Formation에 요청을 전송하여 테이블에 액세스하기 위한 테이블 정보와 자격 증명을 확인합니다.
-
Lake Formation은 요청을 승인하고 통합 애플리케이션에 임시 자격 증명을 벤딩하여 데이터 액세스를 허용합니다.
통합 서비스는 Lake Formation에서 받은 임시 자격 증명을 사용하여 Amazon S3에서 데이터를 읽고 결과를 보안 주체와 공유합니다.
