더 이상 Amazon Machine Learning 서비스를 업데이트하거나 새 사용자를 받지 않습니다. 이 설명서는 기존 사용자에 제공되지만 더 이상 업데이트되지 않습니다. 자세한 내용은 머신 러닝이란? 단원을 참조하세요.
기계 번역으로 제공되는 번역입니다. 제공된 번역과 원본 영어의 내용이 상충하는 경우에는 영어 버전이 우선합니다.
데이터 인사이트 정보
Amazon ML은 입력 데이터에 대한 설명 통계를 계산하여 데이터를 이해하는 데 사용할 수 있습니다.
설명 통계
Amazon ML은 다양한 속성 유형에 대해 다음과 같은 설명 통계를 계산합니다.
숫자
-
분포 히스토그램
-
유효하지 않은 값 수
-
최소값, 중앙값, 평균값, 최대값
이진 및 범주형:
-
카운트(범주별 고유 값)
-
가치 분포 히스토그램
-
가장 빈번한 값
-
고유 값 카운트
-
실제 값의 백분율(이진만 해당)
-
가장 눈에 띄는 단어
-
가장 자주 사용하는 단어
텍스트
-
속성의 이름
-
대상과의 상관 관계(대상이 설정된 경우)
-
총 단어 수
-
고유 단어
-
한 줄의 단어 수 범위
-
단어 길이 범위
-
가장 눈에 띄는 단어
Amazon ML 콘솔에서 데이터 인사이트 정보에 액세스
ML 콘솔에서는 데이터 소스의 이름 또는 ID를 선택하면 데이터 인사이트 정보 페이지를 볼 수 있습니다. 이 페이지는 다음 정보를 포함하여 데이터 소스와 관련된 입력 데이터에 대해 알아볼 수 있는 지표와 시각화를 제공합니다.
-
데이터 요약
-
대상 분포
-
누락 값
-
유효하지 않은 값
-
데이터 유형별 변수 요약 통계
-
데이터 유형별 변수 분포
다음에 이어지는 단원에서는 지표와 시각화에 대해 보다 자세히 설명합니다.
데이터 요약
데이터 소스의 데이터 요약 보고서에는 데이터 소스 ID, 이름, 완료 위치, 현재 상태, 대상 속성, 입력 데이터 정보(S3 버킷 위치, 데이터 형식, 처리된 레코드 수, 처리 중 발생한 잘못된 레코드 수), 데이터 유형별 변수 수 등의 요약 정보가 표시됩니다.
대상 분포
대상 분포 보고서는 데이터 소스의 대상 속성 분포를 보여줍니다. 다음 예시에서는 willRespondToCampaign 대상 속성이 0인 39,922개의 관측치가 있습니다. 이것은 이메일 캠페인에 응답하지 않은 고객의 수입니다. 5,289개의 관측 결과가 있으며, willRespondToCampaign은 1입니다. 이것은 이메일 캠페인에 응답한 고객 수입니다.

누락 값
누락 값 보고서에는 입력 데이터에서 누락된 값이 있는 속성이 나열됩니다. 숫자 데이터 유형의 속성에만 누락된 값이 있을 수 있습니다. 누락 값은 ML 모델 학습 품질에 영향을 미칠 수 있으므로 가능하면 누락 값을 제공하는 것이 좋습니다.
ML 모델 학습 중에 대상 속성이 누락된 경우 Amazon ML은 해당 레코드를 거부합니다. 대상 속성이 레코드에 있지만 다른 숫자 속성 값이 누락된 경우 Amazon ML은 누락된 값을 간과합니다. 이 경우 Amazon ML은 대체 속성을 생성하고 이 속성을 1로 설정하여 이 속성이 누락되었음을 나타냅니다. 이를 통해 Amazon ML은 누락된 값의 발생으로부터 패턴을 학습할 수 있습니다.
유효하지 않은 값
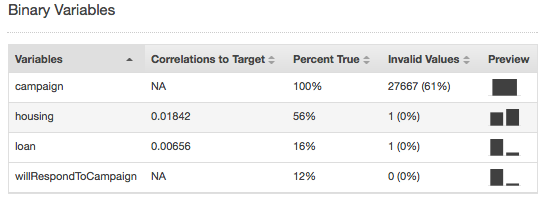
유효하지 않은 값은 숫자 및 이진 데이터 유형에서만 발생할 수 있습니다. 데이터 유형 보고서에서 변수의 요약 통계를 보면 유효하지 않은 값을 찾을 수 있습니다. 다음 예에서는 Duration Number 속성에 유효하지 않은 값이 하나 있고 이진 데이터 유형에는 유효하지 않은 값이 두 개 있습니다(주택 속성과 대출 속성에 하나).

변수-대상 상관 관계
데이터 소스를 생성한 후 Amazon ML은 데이터 소스를 평가하고 변수와 대상 간의 상관 관계 또는 영향을 확인할 수 있습니다. 예를 들어 제품 가격은 베스트셀러 여부에 큰 영향을 미칠 수 있지만 제품의 크기는 예측력이 거의 없을 수 있습니다.
일반적으로 학습 데이터에 최대한 많은 변수를 포함시키는 것이 가장 좋습니다. 그러나 예측력이 거의 없는 변수를 많이 포함시킴으로써 발생하는 노이즈는 ML 모델의 품질과 정확성에 부정적인 영향을 미칠 수 있습니다.
모델을 학습할 때 영향이 거의 없는 변수를 제거하면 모델의 예측 성능을 개선할 수 있습니다. ML의 변환 메커니즘인 레시피로 기계 학습 프로세스에 사용할 수 있는 변수를 정의할 수 있습니다. 레시피에 대해 자세히 알아보려면 기계 학습을 위한 데이터 변환 단원을 참조하세요.
데이터 유형별 속성의 요약 통계
데이터 인사이트 보고서에서 다음 데이터 유형별로 속성 요약 통계를 볼 수 있습니다.
-
이진
-
범주형
-
Numeric
-
텍스트
이진 데이터 유형에 대한 요약 통계는 모든 이진 속성을 보여줍니다. 대상과의 상관 관계 열에는 대상 열과 속성 열 간에 공유되는 정보가 표시됩니다. 실제 백분율 열에는 값이 1인 관측치의 백분율이 표시됩니다. 유효하지 않은 값 열에는 유효하지 않은 값의 수와 각 속성에 대한 유효하지 않은 값의 백분율이 표시됩니다. 미리 보기 열에는 각 속성의 그래픽 분포에 대한 링크가 제공됩니다.
범주형 데이터 유형에 대한 요약 통계는 모든 범주형 속성을 고유 값 수, 가장 빈번한 값 및 최소 빈도 값과 함께 표시합니다. 미리 보기 열에는 각 속성의 그래픽 분포에 대한 링크가 제공됩니다.

숫자 데이터 유형의 요약 통계에는 누락된 값 수, 유효하지 않은 값, 값 범위, 평균 및 중앙값이 포함된 모든 숫자 속성이 표시됩니다. 미리 보기 열에는 각 속성의 그래픽 분포에 대한 링크가 제공됩니다.
텍스트 데이터 유형에 대한 요약 통계에는 모든 텍스트 속성, 해당 속성의 총 단어 수, 해당 속성의 고유 단어 수, 속성의 단어 범위, 단어 길이 범위, 가장 눈에 띄는 단어 등이 표시됩니다. 미리 보기 열에는 각 속성의 그래픽 분포에 대한 링크가 제공됩니다.

다음 예제에서는 4개의 레코드가 포함된 review라는 텍스트 변수에 대한 텍스트 데이터 유형 통계를 보여줍니다.
1. The fox jumped over the fence. 2. This movie is intriguing. 3. 4. Fascinating movie.
이 예제의 열에는 다음 정보가 표시됩니다.
-
속성 열에는 변수 이름이 표시됩니다. 이 예제에서 이 열에는 “review”라고 표시됩니다.
-
대상과의 상관 관계 열은 대상이 지정된 경우에만 존재합니다. 상관 관계는 이 속성이 대상에 대해 제공하는 정보의 양을 측정합니다. 상관 관계가 높을수록 이 속성을 통해 대상에 대해 더 많은 정보를 얻을 수 있습니다. 상관 관계는 텍스트 속성의 단순화된 표현과 대상 간의 상호 정보 측면에서 측정됩니다.
-
전체 단어 열에는 각 레코드를 토큰화하여 생성된 단어 수가 표시되며 단어를 공백으로 구분합니다. 이 예제에서 이 열의 이름은 “12”입니다.
-
고유 단어 열에는 속성의 고유 단어 수가 표시됩니다. 이 예제에서 이 열의 이름은 “10”입니다.
-
속성(범위) 내 단어 수 열에는 속성의 단일 행에 있는 단어 수가 표시됩니다. 이 예제에서 이 열은 “0-6”입니다.
-
단어 길이(범위) 열에는 단어의 문자 수 범위가 표시됩니다. 이 예제에서 이 열은 “2-11”로 표시됩니다.
-
가장 눈에 띄는 단어 열에는 속성에 나타나는 단어의 순위 목록이 표시됩니다. 대상 속성이 있는 경우 대상과의 상관 관계를 기준으로 단어의 순위가 매겨집니다. 즉, 상관 관계가 가장 높은 단어가 먼저 나열됩니다. 데이터에 대상이 없는 경우 단어의 엔트로피를 기준으로 순위가 매겨집니다.
범주형 및 이진 속성의 분포 이해
범주형 또는 바이너리 속성과 관련된 미리 보기 링크를 클릭하면 해당 속성의 분포 뿐만 아니라 속성의 각 범주형 값에 대한 입력 파일의 샘플 데이터를 볼 수 있습니다.
예를 들어 다음 스크린샷에서는 범주형 속성 JoBid에 대한 분포를 보여줍니다. 분포에는 상위 10개 범주형 값이 표시되며 다른 모든 값은 “기타”로 그룹화됩니다. 입력 파일에서 해당 값을 포함하는 입력 파일의 관측치 수와 입력 데이터 파일의 샘플 관측치를 볼 수 있는 링크를 사용하여 상위 10개 범주형 값 각각의 순위를 매깁니다.

숫자 속성의 분포에 대한 이해
숫자 속성의 분포를 보려면 속성의 미리 보기 링크를 클릭합니다. 숫자 속성의 분포를 볼 때 빈 크기를 500, 200, 100, 50 또는 20 중에서 선택할 수 있습니다. 빈 크기가 클수록 표시되는 막대 그래프 수가 줄어듭니다. 또한 빈 크기가 크면 분포의 분해능이 약해집니다. 반대로 버킷 크기를 20으로 설정하면 표시된 분포의 해상도가 높아집니다.
다음 스크린샷과 같이 최소값, 평균값 및 최대값도 표시됩니다.

텍스트 속성 분포에 대한 이해
텍스트 속성의 분포를 보려면 속성의 미리 보기 링크를 클릭합니다. 텍스트 속성의 분포를 볼 때 다음 정보가 표시됩니다.

- 순위 결정
-
텍스트 토큰은 전달하는 정보의 양(정보가 가장 많은 것부터 가장 적은 것까지)을 기준으로 순위가 매겨집니다.
- 토큰
-
토큰은 입력 텍스트에서 통계 행과 관련된 단어를 표시합니다.
- 단어 돌출
-
대상 속성이 있는 경우 대상과의 상관 관계를 기준으로 단어의 순위가 매겨지므로 상관 관계가 가장 높은 단어를 먼저 나열합니다. 데이터에 대상이 없는 경우 단어의 엔트로피, 즉 전달할 수 있는 정보의 양을 기준으로 단어의 순위가 매겨집니다.
- 카운트 수
-
카운트 수는 해당 토큰이 나타난 입력 레코드 수를 나타냅니다.
- 카운트 백분율
-
카운트 백분율은 토큰이 나타난 입력 데이터 행의 백분율을 나타냅니다.
