더 이상 Amazon Machine Learning 서비스를 업데이트하거나 새 사용자를 받지 않습니다. 이 설명서는 기존 사용자에 제공되지만 더 이상 업데이트되지 않습니다. 자세한 내용은 머신 러닝이란? 단원을 참조하세요.
기계 번역으로 제공되는 번역입니다. 제공된 번역과 원본 영어의 내용이 상충하는 경우에는 영어 버전이 우선합니다.
회귀 모델 인사이트 정보
예측 해석
회귀 ML 모델의 출력은 대상의 모델 예측에 대한 숫자 값입니다. 예를 들어 주택 가격을 예측하는 경우 모델의 예측은 254,013과 같은 값이 될 수 있습니다.
참고
예측 범위가 학습 데이터의 대상 범위와 다를 수 있습니다. 예를 들어 주택 가격을 예측하고 있는데 학습 데이터의 대상이 0 ~ 450,000 범위의 값을 갖고 있다고 가정해 보겠습니다. 예측되는 대상이 같은 범위에 있을 필요는 없으며 양수 값(450,000 초과) 또는 음수 값(0 미만)을 취할 수 있습니다. 사용 중인 애플리케이션에 적합한 범위를 벗어나는 예측 값을 처리하는 방법을 계획하는 것이 중요합니다.
ML 모델 정확도 측정
회귀 작업의 경우 Amazon ML은 업계 표준 제곱 평균 제곱 오차(RMSE) 지표를 사용합니다. 이러한 지표는 예측 수치 대상과 실제 수치 대답(실측 정보) 간의 거리 측정에 해당됩니다. RMSE 값이 작을수록 모델의 예측 정확도가 높아집니다. 예측이 완벽하게 정확한 모델의 RMSE는 0입니다. 다음 예제에서는 N개의 레코드가 포함된 평가 데이터를 보여줍니다.

기본 RMSE
Amazon ML은 회귀 모델을 위한 기준 지표를 제공합니다. 이는 항상 대상의 평균을 예측하여 답을 제시하는 가상 회귀 모델용 RMSE입니다. 예를 들어, 주택 구매자의 연령을 예측하고 학습 데이터에 포함된 관측치의 평균 연령이 35세인 경우 기준 모델은 항상 답을 35세로 예측합니다. ML 모델을 이 기준과 비교하여 ML 모델이 이 상수 답을 예측하는 ML 모델보다 나은지 검증할 수 있습니다.
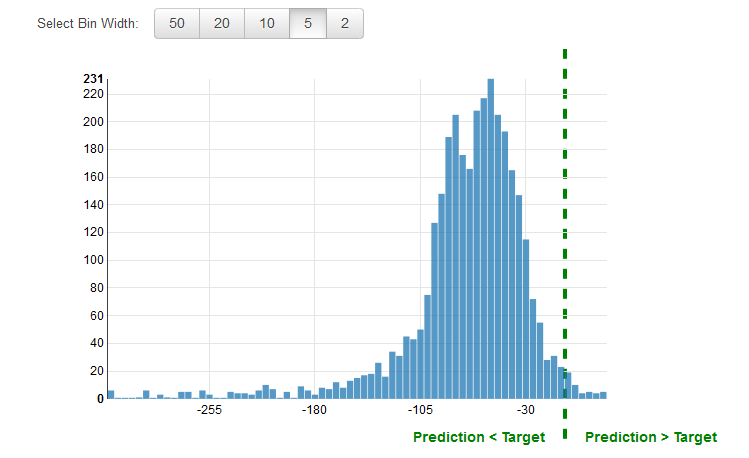
성능 시각화 사용
회귀 문제에 대해 잔차를 검토하는 것이 일반적입니다. 평가 데이터에서 관측치에 대한 잔차는 실제 대상과 예측된 대상 간의 차이입니다. 잔차는 대상 중 모델이 예측할 수 없는 부분을 나타냅니다. 긍정 잔차는 모델이 대상을 과소평가하고 있다는 것을 나타냅니다(실제 대상이 예측된 대상보다 큼). 부정 잔차는 모델이 과대평가하고 있다는 것을 나타냅니다(실제 대상이 예측된 대상보다 작음). 종 모양으로 분포되고 0에 중심을 둔, 평가 데이터에 대한 잔차 히스토그램은 모델이 임의의 방식으로 오류를 만들고 대상 값의 특정 범위를 체계적으로 예측할 수 없다는 것을 나타냅니다. 잔차가 0에 중심을 둔 종 모양을 형성하지 않는다면 몇 가지 구조가 모델의 예측 오차에 포함된 것입니다. 모델에 변수를 더 추가하면 모델이 현재 모델이 캡처하지 않은 패턴을 캡처하는 데 도움이 될 수 있습니다. 다음 그림에서는 중심이 0이 아닌 잔차를 보여줍니다.