기계 번역으로 제공되는 번역입니다. 제공된 번역과 원본 영어의 내용이 상충하는 경우에는 영어 버전이 우선합니다.
벡터 검색 기능 및 제한
벡터 검색 가능 여부
벡터 검색이 활성화된 MemoryDB 구성은 R6g, R7g 및 T4g 노드 유형에서 지원되며 MemoryDB를 사용할 수 있는 모든 AWS 리전에서 사용할 수 있습니다.
검색을 활성화하기 위해 기존 클러스터를 수정할 수 없습니다. 그러나 검색이 비활성화된 클러스터의 스냅샷에서 검색이 활성화된 클러스터를 생성할 수 있습니다.
파라미터 제한 사항
다음 표는 다양한 벡터 검색 항목에 대한 제한 사항을 보여줍니다.
| Item | 최대값 |
|---|---|
| 벡터의 차원 수 | 32768 |
| 만들 수 있는 인덱스 수 | 10 |
| 인덱스의 필드 수 | 50 |
| FT.SEARCH 및 FT.AGGREGATE TIMEOUT 절(밀리초) | 10000 |
| FT.AGGREGATE 명령의 파이프라인 단계 수 | 32 |
| FT.AGGREGATE LOAD 절의 필드 수 | 1024 |
| FT.AGGREGATE GROUPBY 절의 필드 수 | 16 |
| FT.AGGREGATE SORTBY 절의 필드 수 | 16 |
| FT.AGGREGATE PARAM 절의 파라미터 수 | 32 |
| HNSW M 파라미터 | 512 |
| HNSW EF_CONSTRUCTION 파라미터 | 4096 |
| HNSW EF_RUNTIME 파라미터 | 4096 |
규모 조정 제한
MemoryDB에 대한 벡터 검색은 현재 단일 샤드로 제한되며 수평적 크기 조정은 지원되지 않습니다. 벡터 검색은 수직 및 복제 크기 조정을 지원합니다.
운영상의 제한 사항
인덱스 지속성 및 채우기
벡터 검색 기능은 인덱스의 정의와 인덱스의 콘텐츠를 유지합니다. 즉, 노드를 시작하거나 다시 시작하게 하는 모든 운영 요청 또는 이벤트 중에 인덱스 정의 및 콘텐츠가 최신 스냅샷에서 복원되고 보류 중인 모든 트랜잭션이 저널에서 재생됩니다. 이를 시작하는 데는 사용자 작업이 필요하지 않습니다. 재구축은 데이터가 복원되는 즉시 채우기 작업으로 수행됩니다. 이는 시스템이 정의된 각 인덱스에 대해 FT.CREATE 명령을 자동으로 실행하는 것과 기능적으로 동일합니다. 데이터가 복원되자마자 노드를 애플리케이션 작업에 사용할 수 있지만 인덱스 채우기가 완료되지 않았을 가능성이 높습니다. 즉, 채우기가 애플리케이션에 다시 표시될 수 있으며, 예를 들어 인덱스 채우기를 사용한 검색 명령은 거부될 수 있습니다. 채우기에 대한 자세한 내용은 벡터 검색 개요을(를) 참조하세요.
인덱스 채우기 완료는 원본과 복제본 간에 동기화되지 않습니다. 불완전한 동기화가 애플리케이션에 예기치 않게 나타날 수 있으므로 애플리케이션에서 검색 작업을 시작하기 전에 원본과 모든 복제본에서 채우기가 완료되었는지 확인하는 것이 좋습니다.
스냅샷 가져오기/내보내기 및 실시간 마이그레이션
RDB 파일에 검색 인덱스가 있으면 해당 데이터 전송의 호환성이 제한됩니다. MemoryDB 벡터 검색 기능에 의해 정의된 벡터 인덱스의 형식은 다른 MemoryDB 벡터 활성화 클러스터에서만 인식됩니다. 또한 MemoryDB 클러스터의 GA 버전에서 평가판 클러스터의 RDB 파일을 가져올 수 있습니다. 그러면 RDB 파일을 로드할 때 인덱스 콘텐츠가 재구축됩니다.
그러나 인덱스가 포함되지 않은 RDB 파일에는 이러한 제한이 적용되지 않습니다. 따라서 내보내기 전에 인덱스를 삭제하여 평가판 클러스터 내의 데이터를 미리 보기가 아닌 클러스터로 내보낼 수 있습니다.
메모리 사용
메모리 소비는 벡터 수, 차원 수, M-값, 벡터가 아닌 데이터(예: 벡터에 연결된 메타데이터 또는 인스턴스에 저장된 기타 데이터)의 양을 기반으로 합니다.
필요한 총 메모리는 실제 벡터 데이터에 필요한 공간과 벡터 인덱스에 필요한 공간의 조합입니다. 벡터 데이터에 필요한 공간은 최적의 메모리 할당을 위해 HASH 또는 JSON 데이터 구조 내에 벡터를 저장하는 데 필요한 실제 용량과 가장 가까운 메모리 슬래브에 대한 오버헤드를 측정하여 계산됩니다. 각 벡터 인덱스는 이러한 데이터 구조에 저장된 벡터 데이터에 대한 참조를 사용하며 효율적인 메모리 최적화를 사용하여 인덱스에 있는 벡터 데이터의 중복 사본을 제거합니다.
벡터 수는 데이터를 벡터로 표현하는 방법에 따라 달라집니다. 예를 들어 단일 문서를 여러 청크로 나타내도록 선택할 수 있습니다. 여기서 각 청크는 벡터를 나타냅니다. 또는 전체 문서를 단일 벡터로 나타내도록 선택할 수 있습니다.
벡터의 차원 수는 선택한 임베딩 모델에 따라 달라집니다. 예를 들어 AWS Titan
M 파라미터는 인덱스 구성 중에 모든 새 요소에 대해 생성된 양방향 링크 수를 나타냅니다. MemoryDB는 이 값을 16으로 기본 설정합니다. 하지만 이를 재정의할 수 있습니다. M 파라미터가 높으면 높은 차원성 및/또는 높은 재현율 요구 사항에 더 적합하고, M 파라미터가 낮으면 낮은 차원성 및/또는 낮은 재현율 요구 사항에 더 적합합니다. M 값은 인덱스가 커질수록 메모리 소비가 증가합니다.
MemoryDB 콘솔 환경에서 클러스터 설정의 벡터 검색 활성화를 선택하면 벡터 워크로드의 특성에 따라 올바른 인스턴스 유형을 쉽게 선택할 수 있습니다.
샘플 워크로드
고객이 내부 재무 문서를 기반으로 시맨틱 검색 엔진을 구축하려고 합니다. 고객은 현재 1536개 차원을 갖는 titan 임베딩 모델을 사용하여 문서당 10개의 벡터로 청크된 100만 개 재무 문서를 보유하고 있으며 벡터가 아닌 데이터는 없습니다. 고객은 기본값인 16을 M 파라미터로 사용하기로 결정합니다.
벡터: 100만 * 10 청크 = 1000만 벡터
차원: 1536
벡터가 아닌 데이터(GB): 0GB
M 파라미터: 16
고객은 이 데이터를 사용하고 콘솔에서 벡터 계산기 사용 버튼을 클릭하여 파라미터를 기반으로 권장 인스턴스 유형을 가져올 수 있습니다.
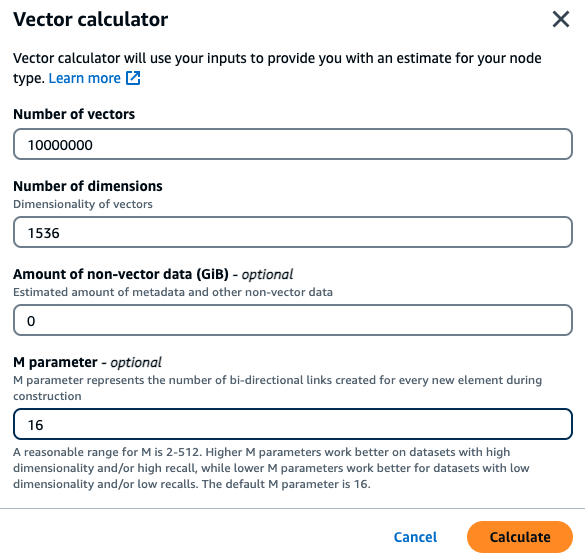

이 예제에서 벡터 계산기는 제공된 파라미터를 기반으로 벡터를 저장하는 데 필요한 메모리를 보유할 수 있는 가장 작은 MemoryDB r7g 노드 유형
위의 계산 방법과 샘플 워크로드의 파라미터에 따라 이 벡터 데이터는 데이터와 단일 인덱스를 저장하는 데 104.9GB가 필요합니다. 이 경우 사용 가능한 메모리가 105.81GB인 db.r7g.4xlarge 인스턴스 유형이 권장됩니다. 다음으로 가장 작은 노드 유형은 너무 작아서 벡터 워크로드를 보유할 수 없습니다.
각 벡터 인덱스는 저장된 벡터 데이터에 대한 참조를 사용하고 벡터 인덱스에 벡터 데이터의 추가 사본을 생성하지 않으므로 인덱스는 비교적 적은 공간을 소비합니다. 이는 여러 인덱스를 만드는 경우뿐만 아니라, 벡터 데이터의 일부가 삭제되어 고품질 벡터 검색 결과를 위한 최적의 노드 연결을 만들도록 HNSW 그래프를 재구성하는 경우에도 매우 유용합니다.
채우기 중 메모리 부족
Valkey 및 Redis OSS 쓰기 작업과 마찬가지로 인덱스 채우기에는 메모리 부족 제한이 적용됩니다. 채우기가 진행되는 동안 엔진 메모리가 가득 차면 모든 채우기가 일시 중지됩니다. 메모리를 사용할 수 있게 되면 채우기가 다시 시작됩니다. 메모리 부족으로 인해 채우기가 일시 중지된 경우 삭제하고 인덱싱할 수도 있습니다.
트랜잭션
FT.CREATE, FT.DROPINDEX, FT.ALIASADD, FT.ALIASDEL, 및 FT.ALIASUPDATE 명령은 트랜잭션 컨텍스트에서 실행할 수 없습니다. 즉, MULTI/EXEC 블록, LUA 또는 FUNCTION 스크립트 내에서는 실행할 수 없습니다.
