기계 번역으로 제공되는 번역입니다. 제공된 번역과 원본 영어의 내용이 상충하는 경우에는 영어 버전이 우선합니다.
커넥터
커넥터는 데이터 소스의 스트리밍 데이터를 Apache Kafka 클러스터로 지속적으로 복사하거나 클러스터의 데이터를 데이터 싱크로 지속적으로 복사하여 외부 시스템과 Amazon 서비스를 Apache Kafka와 통합합니다. 커넥터는 데이터를 대상에 전달하기 전에 변환, 형식 변환 또는 데이터 필터링과 같은 간단한 로직을 수행할 수도 있습니다. 소스 커넥터는 데이터 소스에서 데이터를 가져와서 해당 데이터를 클러스터로 푸시하고, 싱크 커넥터는 클러스터에서 데이터를 가져와서 해당 데이터를 데이터 싱크로 푸시합니다.
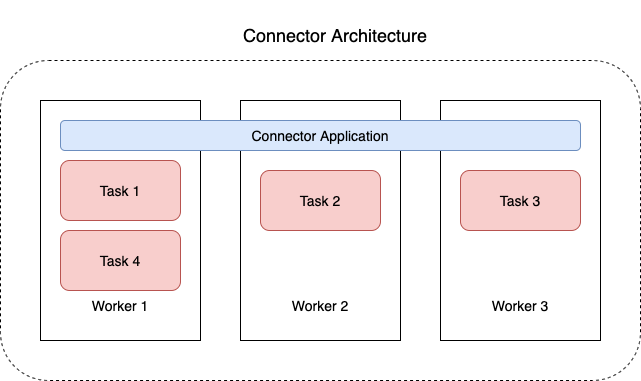
다음 다이어그램은 커넥터의 아키텍처를 보여줍니다. 작업자는 커넥터 로직을 실행하는 Java 가상 머신(JVM) 프로세스입니다. 각 작업자는 병렬 스레드에서 실행되는 일련의 작업을 생성하고 데이터 복사 작업을 수행합니다. 작업은 상태를 저장하지 않으므로 탄력적이고 규모를 조정할 수 있는 데이터 파이프라인을 제공하기 위해 언제든지 시작, 중지 또는 다시 시작할 수 있습니다.
커넥터 용량
커넥터의 총 용량은 커넥터가 보유한 작업자 수와 작업자당 MSK 연결 단위(MCU)의 수에 따라 달라집니다. 각 MCU는 1vCPU의 컴퓨팅과 4기가바이트의 메모리를 나타냅니다. MCU 메모리는 사용 중인 힙 메모리가 아닌 작업자 인스턴스의 전체 메모리와 관련이 있습니다.
MSK Connect 작업자는 고객이 제공한 서브넷의 IP 주소를 사용합니다. 각 작업자는 고객이 제공한 서브넷 중 하나의 IP 주소를 사용합니다. CreateConnector 요청에 제공된 서브넷에 지정된 용량을 고려하도록 서브넷에 사용 가능한 IP 주소가 충분한지 확인해야 합니다. 특히 작업자 수가 변동될 수 있는 커넥터를 자동 확장하는 경우에는 더욱 그렇습니다.
커넥터를 생성하려면 다음 두 가지 용량 모드 중 하나를 선택해야 합니다.
-
프로비저닝 - 커넥터의 용량 요구 사항을 알고 있는 경우 이 모드를 선택합니다. 두 가지 값을 지정합니다.
-
작업자 수
-
작업자당 MCU 수
-
-
자동 크기 조정 - 커넥터의 용량 요구 사항이 가변적이거나 이를 미리 알 수 없는 경우 이 모드를 선택합니다. 자동 규모 조정 모드를 사용하는 경우 Amazon MSK Connect는 커넥터에서 실행 중인 작업자 수와 작업자당 MCU 수에 비례하는 값으로 커넥터의
tasks.max속성을 재정의합니다.세 가지의 값 세트를 지정합니다.
-
최소 및 최대 작업자 수
-
CpuUtilization지표에 의해 결정되는 CPU 사용률에 대한 스케일 인 및 스케일 아웃 비율로, 커넥터에 대한CpuUtilization지표가 스케일 아웃 비율을 초과하면 MSK Connect는 커넥터에서 실행 중인 작업자 수를 늘립니다.CpuUtilization지표가 스케일 인 비율 아래로 떨어지면 MSK Connect는 작업자 수를 줄입니다. 작업자 수는 항상 커넥터를 만들 때 지정한 최소 및 최대 수 이내로 유지됩니다. -
작업자당 MCU 수
-
작업자에 대한 자세한 내용은 작업자 섹션을 참조하세요. MSK Connect 지표에 대한 자세한 내용은 MSK Connect 모니터링를 참조하세요.
커넥터 생성
를 사용하여 커넥터 만들기 AWS Management Console
https://console.aws.amazon.com/msk/
에서 Amazon MSK 콘솔을 엽니다. 왼쪽 창의 MSK Connect에서 커넥터를 선택합니다.
[커넥터 생성(Create connector)]을 선택합니다.
기존 사용자 지정 플러그인을 사용하여 커넥터를 생성하거나 새 사용자 지정 플러그인을 먼저 생성하는 것 중에서 선택할 수 있습니다. 사용자 정의 플러그인 및 플러그인 생성 방법에 대한 자세한 내용은 플러그인 섹션을 참조하세요. 이 절차에서는 사용하려는 사용자 지정 플러그인이 있다고 가정해 보겠습니다. 사용자 지정 플러그인 목록에서 사용하려는 플러그인을 찾아 왼쪽에 있는 상자를 선택한 후 다음을 선택합니다.
-
이름과 설명(선택 사항)을 입력합니다.
-
연결하려는 클러스터를 선택합니다.
-
커넥터 구성을 지정합니다. 지정해야 하는 구성 파라미터는 생성하려는 커넥터 유형에 따라 달라집니다. 그러나 일부 파라미터(예:
connector.class및tasks.max파라미터)는 모든 커넥터에 공통으로 적용됩니다. 다음은 Confluent Amazon S3 Sink Connector구성의 예제입니다. connector.class=io.confluent.connect.s3.S3SinkConnector tasks.max=2 topics=my-example-topic s3.region=us-east-1 s3.bucket.name=my-destination-bucket flush.size=1 storage.class=io.confluent.connect.s3.storage.S3Storage format.class=io.confluent.connect.s3.format.json.JsonFormat partitioner.class=io.confluent.connect.storage.partitioner.DefaultPartitioner key.converter=org.apache.kafka.connect.storage.StringConverter value.converter=org.apache.kafka.connect.storage.StringConverter schema.compatibility=NONE -
그런 다음 커넥터 용량을 구성합니다. 프로비저닝과 자동 규모 조정이라는 두 가지 용량 모드 중에서 선택할 수 있습니다. 이러한 두 가지 옵션에 대한 자세한 내용은 커넥터 용량 단원을 참조하십시오.
-
기본 작업자 구성 또는 사용자 지정 작업자 구성 중 하나를 선택합니다. 사용자 지정 작업자 구성 생성에 대한 자세한 내용은 작업자 섹션을 참조하세요.
-
그런 다음 서비스 실행 역할을 지정합니다. 이는 MSK Connect가 위임할 수 있는 IAM 역할이어야 하며, 커넥터에 필요한 리소스에 액세스하는 데 필요한 AWS 모든 권한을 부여하는 IAM 역할이어야 합니다. 이러한 권한은 커넥터의 로직에 따라 달라집니다. 이 역할 생성 방법에 대한 자세한 내용은 서비스 실행 역할 단원을 참조하십시오.
-
다음을 선택하고 보안 정보를 검토한 후 다음을 다시 선택합니다.
-
원하는 로깅 옵션을 지정한 후 다음을 선택합니다. 로깅에 대한 자세한 내용은 MSK Connect 로깅 단원을 참조하세요.
-
[커넥터 생성(Create connector)]을 선택합니다.
MSK Connect API를 사용하여 커넥터를 만들려면 을 참조하십시오 CreateConnector.
