기계 번역으로 제공되는 번역입니다. 제공된 번역과 원본 영어의 내용이 상충하는 경우에는 영어 버전이 우선합니다.
Neptune CloudWatch 지표
참고
Amazon Neptune은 값이 0이 아닌 경우에 한해 지표를 CloudWatch에 전송합니다.
모든 Neptune 지표의 집계 단위는 5분입니다.
Neptune CloudWatch 지표
다음 표에는 Neptune이 지원하는 CloudWatch 지표가 나와 있습니다.
참고
유지 관리, 재부팅 또는 장애 복구 등 서버를 재시작할 때마다 모든 누적 지표가 0으로 재설정됩니다.
| 지표 | 설명 |
|---|---|
|
Neptune DB 클러스터의 백업 보존 기간에서 지원하는 데 사용되는 총 백업 스토리지 양(바이트)입니다. |
|
버퍼 캐시에서 처리하는 요청 비율입니다. 캐시 누락으로 인해 상당한 지연 시간이 발생하기 때문에, 이 지표는 쿼리 지연 시간을 진단하는 데 유용할 수 있습니다. 캐시 적중률이 99.9 미만인 경우 메모리에 더 많은 데이터를 캐시하도록 인스턴스 유형을 업그레이드해 보세요. |
|
읽기 전용 복제본의 경우 기본 인스턴스에서 업데이트를 복제할 때의 지연 시간(밀리초). |
|
기본 인스턴스와 DB 클러스터의 각 Neptune DB 인스턴스 사이에 발생하는 최대 지연 시간(밀리초)입니다. |
|
기본 인스턴스와 DB 클러스터의 각 Neptune DB 인스턴스 사이에 발생하는 최소 지연 시간(밀리초)입니다. |
|
5분 간격으로 보고되는 인스턴스가 누적된 CPU 크레딧 수입니다. 이 지표는 DB 인스턴스가 지정된 속도로 기준 성능 수준을 넘어 얼마나 오래 버스트할 수 있는지 결정하는 데 사용됩니다. |
|
5분 간격으로 보고되는 지정된 기간 동안 소비된 CPU 크레딧 수입니다. 이 지표는 DB 인스턴스에 할당된 가상 CPU에서 처리 명령에 실제 CPU를 사용한 시간을 측정합니다. |
|
|
|
획득한 CPU 크레딧으로 지불되지 않고 추가 요금이 발생하는 소비된 잉여 크레딧 수입니다. |
|
CPU 사용 백분율. |
|
인스턴스 실행 시간(초). |
|
사용 가능한 RAM 크기(바이트). |
|
Neptune 글로벌 데이터베이스의 기본에서 보조 AWS 리전 로 전송된 다시 실행 로그 데이터의 AWS 리전 바이트 수입니다. |
|
글로벌 데이터베이스의 기본 AWS 리전 에서 보조 AWS 리전의 클러스터 볼륨으로 복제된 쓰기 I/O 작업 수입니다. Neptune 글로벌 데이터베이스의 각 DB 클러스터에 대한 청구 계산은 해당 클러스터 내에서 수행되는 쓰기를 설명하기 위해 |
|
사용자 트랜잭션과 시스템 트랜잭션 모두에 있어서 보조 클러스터가 기본 클러스터보다 얼마나 뒤처져 있는지를 나타내는 밀리초 단위입니다. |
|
Gremlin 순회 시 초당 클라이언트 측 오류 수 |
|
Gremlin 순회 시 초당 서버 측 오류 수 |
|
Gremlin 엔진에 대한 초당 요청 수 |
|
Neptune에 대해 열린 WebSocket 연결의 수입니다. |
|
로더 요청에서 나온 초당 클라이언트 측 오류 수 |
|
초당 로더 요청 수 |
|
초당 로더 서버 측 오류 수 |
|
실행 대기 중인 입력 대기열에서 대기 중인 요청 수를 표시합니다. Neptune은 요청이 최대 대기열 용량을 초과할 경우 요청을 제한하기 시작합니다. |
|
Neptune Serverless DB 인스턴스 또는 DB 클러스터에만 적용됩니다. 인스턴스 수준에서 해당 인스턴스에 현재 사용 중인 Neptune 용량 단위(NCU) 수를 클러스터의 최대 NCU 용량 설정으로 나누어 계산한 백분율을 보고합니다. Neptune 용량 단위(NCU)는 2GiB(기비바이트)의 메모리(RAM)와 관련 가상 프로세서 용량(vCPU) 및 네트워킹으로 구성됩니다. 클러스터 수준에서 |
|
Neptune DB 클러스터의 인스턴스 하나가 클라이언트에서 수신하고 클라이언트로 전송하는 네트워크 처리량(bps)입니다. 이 처리량에서 DB 클러스터의 인스턴스와 클러스터 볼륨 간 네트워크 트래픽은 제외됩니다. |
|
Neptune DB 클러스터의 인스턴스 하나가 클라이언트로 전송하는 송신 네트워크 처리량(bps)입니다. 이 처리량에서 DB 클러스터의 인스턴스와 클러스터 볼륨 간 네트워크 트래픽은 제외됩니다. |
NumIndexDeletesPerSec |
개별 인덱스에서 삭제된 횟수입니다. 각 인덱스의 삭제는 개별적으로 계산됩니다. 여기에는 쿼리에 오류가 발생할 경우 롤백될 수 있는 삭제가 포함됩니다. |
NumIndexInsertsPerSec |
개별 인덱스에 대한 삽입 수입니다. 각 인덱스에 대한 삽입은 별도로 계산됩니다. 여기에는 쿼리에 오류가 발생할 경우 롤백될 수 있는 삽입이 포함됩니다. |
NumIndexReadsPerSec |
인덱스에서 스캔한 문 수입니다. 모든 액세스 패턴은 인덱스 검색으로 시작하고 일치하는 모든 문을 읽습니다. 이 지표가 증가하면 쿼리 지연 시간 또는 CPU 사용률이 증가할 수 있습니다. |
|
초당 OpenCypher 클라이언트 오류 수입니다. |
|
초당 OpenCypher 요청 수입니다. |
|
초당 OpenCypher 서버 오류 수입니다. |
|
초당 대기 중인 요청 수입니다. |
|
Gremlin 결과 캐시 적중 횟수입니다. |
|
Gremlin 결과 캐시 누락 횟수입니다. |
|
성공적으로 커밋된 초당 트랜잭션의 수 |
|
서버에서 열린 초당 트랜잭션의 수 |
|
쓰기 쿼리의 경우 오류로 인해 서버에서 롤백된 초당 트랜잭션 수입니다. 읽기 전용 쿼리의 경우 이 지표는 초당 완료된 읽기 전용 트랜잭션 수와 같습니다. |
NumUndoPagesPurged |
이 지표는 제거된 배치 수를 나타냅니다. 이 지표는 제거 진행 상황을 나타냅니다. 값은 리더 인스턴스0용이며 지표는 라이터 인스턴스에만 적용됩니다. |
|
openCypher 엔진에 대한 초당 요청 수(HTTPS 및 Bolt 모두)입니다. |
|
Neptune에 대한 열린 Bolt 연결 수입니다. |
|
Gremlin 결과 캐시에 있는 모든 캐시 항목의 총 예상 크기(바이트)입니다. |
|
Gremlin 결과 캐시의 항목 수입니다. |
|
Gremlin 결과 캐시에 캐시된 가장 오래된 항목의 타임스탬프입니다. |
|
Gremlin 결과 캐시에 캐시된 최신 항목의 타임스탬프입니다. |
|
인스턴스 수준 지표로서, 클러스터 수준에서 |
|
Neptune DB 클러스터에 대해 백업 보존 기간 경과 후 모든 스냅샷에 사용된 총 백업 스토리지 양(바이트)입니다. |
|
SPARQL 쿼리 시 초당 클라이언트 측 오류 수 |
|
SPARQL 엔진에 대한 초당 요청 수. |
|
초당 SPARQL 서버 오류 수입니다. |
|
서버 시작 이후 DFE 통계를 위해 스캔한 총 문 수입니다. 통계 계산이 트리거될 때마다 이 수치는 증가하며 계산이 수행되지 않을 때는 정적으로 유지됩니다. 따라서 시간 경과에 따라 그래프를 작성하여 계산이 발생한 시기와 수행되지 않은 시기를 알 수 있습니다. 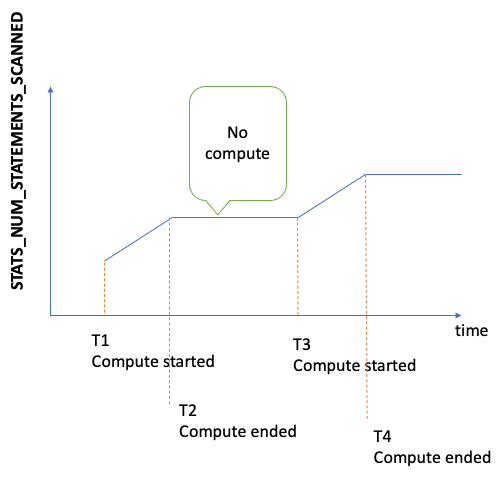
지표가 증가하는 기간의 그래프 기울기를 보면 계산 속도도 알 수 있습니다. 이러한 지표가 없다면 DB 클러스터에서 통계 기능이 비활성화되어 있거나 실행 중인 엔진 버전에 통계 기능이 없다는 의미입니다. 지표 값이 0이면 통계 계산이 수행되지 않은 것입니다. |
|
Neptune DB 클러스터의 각 인스턴스가 스토리지 하위 시스템에서 수신한 네트워크 처리량입니다. |
StorageNetworkThroughput |
Neptune DB 클러스터의 각 인스턴스가 스토리지 하위 시스템에서 수신하고 전송한 네트워크 처리량입니다. |
|
Neptune DB 클러스터의 각 인스턴스가 스토리지 하위 시스템으로 전송하는 네트워크 처리량입니다. |
|
사용되는 스왑 공간 크기입니다. |
|
Neptune DB 인스턴스에 연결된 로컬 스토리지의 읽기 및 쓰기 모두에 대한 IOPS 수입니다. 이 지표는 개수를 나타내며 초당 한 번 측정됩니다. |
|
Neptune DB 인스턴스와 연결된 로컬 스토리지에서 송수신되는 데이터의 양입니다. 이 지표는 개수를 나타내며 초당 한 번 측정됩니다. |
|
특정 Neptune DB 클러스터에 대한 총 백업 스토리지 양(바이트)입니다. 이 양에 대해 요금이 청구됩니다. |
|
모든 소스에서 서버로의 초당 총 요청 수 |
|
클라이언트 측 문제로 인해 오류가 발생한 초당 요청의 총 수 |
|
내부 장애로 인해 서버에서 오류가 발생한 초당 요청의 총 수 |
|
실행 취소 로그 목록에 있는 실행 취소 로그 수입니다. 실행 취소 로그에는 모든 활성 트랜잭션이 커밋 시간보다 더 최신일 때 만료되는 커밋된 트랜잭션 레코드가 포함됩니다. 만료된 레코드는 정기적으로 삭제됩니다. 삭제 작업을 위한 레코드는 다른 유형의 트랜잭션에 대한 레코드보다 제거하는 데 시간이 더 오래 걸릴 수 있습니다. 제거는 DB 클러스터의 라이터 인스턴스에서만 수행되므로, 삭제 속도는 라이터 인스턴스 유형에 따라 달라집니다. 또한 |
|
Neptune DB 클러스터에 할당된 총 스토리지 용량(바이트)입니다. 요금이 청구되는 스토리지 용량입니다. 현재 사용 중인 용량이 아니라 특정 시점에 DB 클러스터에 할당된 최대 스토리지 용량입니다(Neptune 스토리지 요금 참조). |
|
클러스터 볼륨에서 청구된 총 읽기 I/O 작업 수는 5분 간격을 보고했습니다. 요금이 청구된 읽기 작업은 클러스터 볼륨 수준에서 계산되며, Neptune DB 클러스터의 모든 인스턴스에 대해 집계된 후 5분 간격으로 보고됩니다. |
VolumeWriteIOPs |
클러스터 볼륨에 대한 총 쓰기 디스크 I/O 작업 수로, 5분 간격으로 보고됩니다. |
현재 Neptune에서 더 이상 사용되지 않는 CloudWatch 지표
이제는 이러한 Neptune 지표가 사용되지 않습니다. 이러한 지표는 여전히 지원되지만, 새롭고 더 개선된 지표가 사용 가능하게 되면 향후 제거될 수 있습니다.
지표 |
설명 |
|---|---|
|
Gremlin 엔드포인트에 대한 HTTP 1xx 초당 응답 횟수 그 대신 새로 |
|
Gremlin 엔드포인트에 대한 HTTP 2xx 초당 응답 횟수 그 대신 새로 |
|
Gremlin 엔드포인트에 대한 HTTP 4xx 초당 오류 횟수 그 대신 새로 |
|
Gremlin 엔드포인트에 대한 HTTP 5xx 초당 오류 횟수 그 대신 새로 |
|
Gremlin 순회에서의 오류 수 |
|
Gremlin 엔진에 대한 요청 수 |
|
Gremlin 엔드포인트에 대한 성공적인 WebSocket 초당 연결 수 |
|
Gremlin 엔드포인트에 대한 WebSocket 클라이언트 초당 오류 횟수 |
|
Gremlin 엔드포인트에 대한 WebSocket 서버 초당 오류 횟수 |
|
현재 사용 가능한 잠재적인 WebSocket 연결 수입니다. |
|
엔드포인트에 대한 HTTP 100 초당 응답 횟수입니다. 그 대신 새로 |
|
엔드포인트에 대한 HTTP 101 초당 응답 횟수입니다. 그 대신 새로 |
|
엔드포인트에 대한 HTTP 1xx 초당 응답 횟수 |
|
엔드포인트에 대한 HTTP 200 초당 응답 횟수입니다. 그 대신 새로 |
|
엔드포인트에 대한 HTTP 2xx 초당 응답 횟수 |
|
엔드포인트에 대한 HTTP 400 초당 오류 횟수 그 대신 새로 |
|
엔드포인트에 대한 HTTP 403 초당 오류 횟수 그 대신 새로 |
|
엔드포인트에 대한 HTTP 405 초당 오류 횟수 그 대신 새로 |
|
엔드포인트에 대한 HTTP 413 초당 오류 횟수 그 대신 새로 |
|
엔드포인트에 대한 HTTP 429 초당 오류 횟수 그 대신 새로 |
|
엔드포인트에 대한 HTTP 4xx 초당 오류 횟수 |
|
엔드포인트에 대한 HTTP 500 초당 오류 횟수 그 대신 새로 |
|
엔드포인트에 대한 HTTP 501 초당 오류 횟수 그 대신 새로 |
|
엔드포인트에 대한 HTTP 5xx 초당 오류 횟수 |
|
로더 요청으로부터의 오류 수. |
|
로더 요청 수 |
|
SPARQL 엔드포인트에 대한 HTTP 1xx 초당 응답 횟수 그 대신 새로 |
|
SPARQL 엔드포인트에 대한 HTTP 2xx 초당 응답 횟수 그 대신 새로 |
|
SPARQL 엔드포인트에 대한 HTTP 4xx 초당 오류 횟수 그 대신 새로 |
|
SPARQL 엔드포인트에 대한 HTTP 5xx 초당 오류 횟수 그 대신 새로 |
|
SPARQL 쿼리에서의 오류 수. |
|
SPARQL 엔진에 대한 요청 수. |
|
상태 엔드포인트로부터의 오류 수. |
|
상태 엔드포인트에 대한 요청 수. |
