기계 번역으로 제공되는 번역입니다. 제공된 번역과 원본 영어의 내용이 상충하는 경우에는 영어 버전이 우선합니다.
explain 및 profile을 사용하여 Gremlin 쿼리 조정
Neptune 설명 및 프로필 API에서 가져온 보고서에 있는 정보를 사용하여 Amazon Neptune에서 Gremlin 쿼리를 조정하여 성능을 향상시킬 수 있는 경우가 많습니다. 이를 위해서는 Neptune이 Gremlin 순회를 처리하는 방법을 이해하는 것이 도움이 됩니다.
중요
TinkerPop 버전 3.4.11에서 쿼리 처리 방식의 정확성을 향상시키는 변경 사항이 적용되었지만, 현재로서는 쿼리 성능에 간혹 심각한 영향을 미칠 수 있습니다.
예를 들어 다음과 같은 쿼리는 실행 속도가 상당히 느릴 수 있습니다.
g.V().hasLabel('airport'). order(). by(out().count(),desc). limit(10). out()
이제 TinkerPop 3.4.11의 변경 사항으로 인해 제한 단계 이후의 버텍스를 최적화하지 않은 방식으로 가져옵니다. 이를 방지하려면 order().by() 이후 언제든지 barrier() 단계를 추가하여 쿼리를 수정할 수 있습니다. 예:
g.V().hasLabel('airport'). order(). by(out().count(),desc). limit(10). barrier(). out()
TinkerPop 3.4.11은 Neptune 엔진 버전 1.0.5.0에서 활성화되었습니다.
Neptune의 Gremlin 순회 처리에 대한 이해
Gremlin 순회가 Neptune으로 전송되면 순회를 엔진이 실행할 기본 실행 계획으로 변환하는 3가지 주요 프로세스인 구문 분석, 변환, 최적화를 거치게 됩니다.

순회 구문 분석 프로세스
순회 처리의 첫 번째 단계는 순회를 공통 언어로 구문 분석하는 것입니다. Neptune에서 이러한 공통 언어는 TinkerPop API
Gremlin 순회는 문자열이나 바이트코드로 Neptune에 보낼 수 있습니다. REST 엔드포인트와 Java 클라이언트 드라이버 submit() 메서드는 다음 예제와 같이 순회를 문자열로 전송합니다.
client.submit("g.V()")
Gremlin language variants(GLV)
순회 변환 프로세스
순회 처리의 두 번째 단계는 TinkerPop 단계를 변환된 Neptune 단계와 변환되지 않은 Neptune 단계 세트로 변환하는 것입니다. Apache TinkerPop Gremlin 쿼리 언어의 단계 대부분은 기본 Neptune 엔진에서 실행되도록 최적화된 Neptune 전용 단계로 변환됩니다. 순회 중에 Neptune에 상응하는 단계가 없는 TinkerPop 단계가 발견되면 해당 단계와 순회의 모든 후속 단계가 TinkerPop 쿼리 엔진에 의해 처리됩니다.
어떤 상황에서 어떤 단계를 변환할 수 있는지에 대한 자세한 내용은 Gremlin 단계 지원을 참조하세요.
순회 최적화 프로세스
순회 처리의 마지막 단계는 옵티마이저를 통해 변환된 단계와 변환되지 않은 일련의 단계를 실행하여 최적의 실행 계획을 결정하는 것입니다. 이 최적화의 결과는 Neptune 엔진이 처리하는 실행 계획입니다.
Neptune Gremlin explain API를 사용하여 쿼리 조정
Neptune 설명 API는 Gremlin explain() 단계와 다릅니다. 쿼리를 실행할 때 Neptune 엔진이 처리할 최종 실행 계획을 반환합니다. 처리를 수행하지 않기 때문에 사용된 파라미터에 관계없이 동일한 계획을 반환하며 출력에는 실제 실행에 대한 통계가 포함되지 않습니다.
앵커리지의 모든 공항 버텍스를 찾는 다음과 같은 간단한 순회를 생각해 보세요.
g.V().has('code','ANC')
Neptune explain API를 통해 이 순회를 실행하는 방법에는 2가지가 있습니다. 첫 번째 방법은 다음과 같이 설명 엔드포인트에 REST를 호출하는 것입니다.
curl -X POST https://your-neptune-endpoint:port/gremlin/explain -d '{"gremlin":"g.V().has('code','ANC')"}'
두 번째 방법은 Neptune 워크벤치의 %%gremlin 셀 매직을 explain 파라미터와 함께 사용하는 것입니다. 그러면 셀 본문에 포함된 순회가 Neptune explain API로 전달되고 셀을 실행할 때 결과 출력이 표시됩니다.
%%gremlin explain g.V().has('code','ANC')
결과 explain API 출력은 순회에 대한 Neptune의 실행 계획을 설명합니다. 아래 이미지에서 볼 수 있듯이, 계획에는 처리 파이프라인의 3단계가 각각 포함됩니다.

변환되지 않은 단계 확인을 통해 순회 조정
Neptune explain API 출력에서 가장 먼저 확인해야 할 사항 중 하나는 Neptune 네이티브 단계로 변환되지 않는 Gremlin 단계입니다. 쿼리 계획에서 Neptune 네이티브 단계로 변환할 수 없는 단계가 발견되면 해당 단계와 계획의 모든 후속 단계를 Gremlin 서버에서 처리합니다.
위 예제에서는 순회의 모든 단계가 변환되었습니다. 이 순회에 대한 explain API 출력을 살펴보겠습니다.
g.V().has('code','ANC').out().choose(hasLabel('airport'), values('code'), constant('Not an airport'))
아래 이미지에서 볼 수 있듯이, Neptune은 choose() 단계를 변환할 수 없습니다.

순회 성능을 조정하는 방법에는 여러 가지가 있습니다. 첫 번째는 변환할 수 없는 단계를 제거하는 방식으로 다시 작성하는 것입니다. 또 다른 방법은 다른 모든 단계를 네이티브 단계로 변환할 수 있도록 단계를 순회 종료 시점으로 옮기는 것입니다.
단계가 변환되지 않은 쿼리 계획을 항상 조정할 필요는 없습니다. 변환할 수 없는 단계가 순회 종료 시점이고 그래프가 순회되는 방식보다는 출력 형식이 지정되는 방식과 관련된 경우 성능에 거의 영향을 미치지 않을 수 있습니다.
Neptune explain API의 출력을 검사할 때 확인해야 할 또 다른 사항은 인덱스를 사용하지 않는 단계입니다. 다음 순회는 앵커리지에 도착하는 항공편이 있는 모든 공항을 검색합니다.
g.V().has('code','ANC').in().values('code')
이 순회에 대한 설명 API의 출력은 다음과 같습니다.
******************************************************* Neptune Gremlin Explain ******************************************************* Query String ============ g.V().has('code','ANC').in().values('code') Original Traversal ================== [GraphStep(vertex,[]), HasStep([code.eq(ANC)]), VertexStep(IN,vertex), PropertiesStep([code],value)] Converted Traversal =================== Neptune steps: [ NeptuneGraphQueryStep(PropertyValue) { JoinGroupNode { PatternNode[(?1, <~label>, ?2, <~>) . project distinct ?1 .] PatternNode[(?1, <code>, "ANC", ?) . project ask .] PatternNode[(?3, ?5, ?1, ?6) . project ?1,?3 . IsEdgeIdFilter(?6) .] PatternNode[(?3, <~label>, ?4, <~>) . project ask .] PatternNode[(?3, ?7, ?8, <~>) . project ?3,?8 . ContainsFilter(?7 in (<code>)) .] }, annotations={path=[Vertex(?1):GraphStep, Vertex(?3):VertexStep, PropertyValue(?8):PropertiesStep], maxVarId=9} }, NeptuneTraverserConverterStep ] Optimized Traversal =================== Neptune steps: [ NeptuneGraphQueryStep(PropertyValue) { JoinGroupNode { PatternNode[(?1, <code>, "ANC", ?) . project ?1 .], {estimatedCardinality=1} PatternNode[(?3, ?5, ?1, ?6) . project ?1,?3 . IsEdgeIdFilter(?6) .], {estimatedCardinality=INFINITY} PatternNode[(?3, ?7=<code>, ?8, <~>) . project ?3,?8 .], {estimatedCardinality=7564} }, annotations={path=[Vertex(?1):GraphStep, Vertex(?3):VertexStep, PropertyValue(?8):PropertiesStep], maxVarId=9} }, NeptuneTraverserConverterStep ] Predicates ========== # of predicates: 26 WARNING: reverse traversal with no edge label(s) - .in() / .both() may impact query performance
출력 하단에 있는 WARNING 메시지는 Neptune이 유지 관리하는 3개의 인덱스 중 하나를 사용하여 순회의 in() 단계를 처리할 수 없기 때문에 발생합니다(Neptune에서 문을 인덱싱하는 방식 및 Neptune의 Gremlin 문참조). 이 in() 단계에는 엣지 필터가 없어 SPOG, POGS 또는 GPSO 인덱스를 사용하여 해결할 수 없습니다. 대신 Neptune은 요청된 버텍스를 찾기 위해 통합 스캔을 수행해야 하는데, 이렇게 하면 효율성이 훨씬 떨어집니다.
이 상황에서 순회를 조정하는 방법은 2가지입니다. 첫 번째 방법은 인덱싱된 조회를 사용하여 쿼리를 해결할 수 있도록 in() 단계에 필터링 기준을 하나 이상 추가하는 것입니다. 위 예제의 경우 다음과 같을 수 있습니다.
g.V().has('code','ANC').in('route').values('code')
수정된 순회에 대한 Neptune explain API 출력에는 더 이상 다음 WARNING 메시지가 포함되지 않습니다.
******************************************************* Neptune Gremlin Explain ******************************************************* Query String ============ g.V().has('code','ANC').in('route').values('code') Original Traversal ================== [GraphStep(vertex,[]), HasStep([code.eq(ANC)]), VertexStep(IN,[route],vertex), PropertiesStep([code],value)] Converted Traversal =================== Neptune steps: [ NeptuneGraphQueryStep(PropertyValue) { JoinGroupNode { PatternNode[(?1, <~label>, ?2, <~>) . project distinct ?1 .] PatternNode[(?1, <code>, "ANC", ?) . project ask .] PatternNode[(?3, ?5, ?1, ?6) . project ?1,?3 . IsEdgeIdFilter(?6) . ContainsFilter(?5 in (<route>)) .] PatternNode[(?3, <~label>, ?4, <~>) . project ask .] PatternNode[(?3, ?7, ?8, <~>) . project ?3,?8 . ContainsFilter(?7 in (<code>)) .] }, annotations={path=[Vertex(?1):GraphStep, Vertex(?3):VertexStep, PropertyValue(?8):PropertiesStep], maxVarId=9} }, NeptuneTraverserConverterStep ] Optimized Traversal =================== Neptune steps: [ NeptuneGraphQueryStep(PropertyValue) { JoinGroupNode { PatternNode[(?1, <code>, "ANC", ?) . project ?1 .], {estimatedCardinality=1} PatternNode[(?3, ?5=<route>, ?1, ?6) . project ?1,?3 . IsEdgeIdFilter(?6) .], {estimatedCardinality=32042} PatternNode[(?3, ?7=<code>, ?8, <~>) . project ?3,?8 .], {estimatedCardinality=7564} }, annotations={path=[Vertex(?1):GraphStep, Vertex(?3):VertexStep, PropertyValue(?8):PropertiesStep], maxVarId=9} }, NeptuneTraverserConverterStep ] Predicates ========== # of predicates: 26
이런 종류의 순회를 많이 실행하는 경우 선택 사항인 OSGP 인덱스가 활성화된 Neptune DB 클러스터에서 순회를 실행하는 방법도 있습니다(OSGP 인덱스 활성화 참조). OSGP 인덱스를 활성화하면 단점이 뒤따릅니다.
데이터를 로드하기 전에 DB 클러스터에서 활성화해야 합니다.
버텍스와 엣지의 삽입 속도가 최대 23%까지 느려질 수 있습니다.
스토리지 사용량이 약 20% 증가하게 됩니다.
모든 인덱스에 요청을 분산시키는 읽기 쿼리로 인해 지연 시간이 길어질 수 있습니다.
제한된 쿼리 패턴 세트에는 OSGP 인덱스를 사용하는 것이 좋습니다. 하지만 이러한 패턴을 자주 실행하지 않는다면 일반적으로 3가지 기본 인덱스를 사용하여 작성한 순회 문제를 해결할 수 있도록 하는 것이 좋습니다.
많은 수의 조건자 사용
Neptune은 그래프의 각 엣지 레이블과 각각의 고유한 버텍스 또는 엣지 속성 이름을 조건자로 취급하며, 상대적으로 적은 수의 고유 조건자와 함께 작동하도록 기본적으로 설계되었습니다. 그래프 데이터에 조건자가 수천 개가 넘으면 성능이 저하될 수 있습니다.
다음과 같은 경우 Neptune explain 출력에서 경고를 표시합니다.
Predicates ========== # of predicates: 9549 WARNING: high predicate count (# of distinct property names and edge labels)
레이블과 속성의 개수, 즉 조건자 수를 줄이기 위해 데이터 모델을 재작업하기가 어려운 경우, 위에서 설명한 것처럼 OSGP 인덱스가 활성화된 DB 클러스터에서 실행하여 순회를 조정하는 것이 가장 좋습니다.
Neptune Gremlin profile API를 사용하여 순회 조정
Neptune profile API는 Gremlin profile() 단계와 상당히 다릅니다. explain API와 마찬가지로 출력에는 Neptune 엔진이 순회를 실행할 때 사용하는 쿼리 계획이 포함됩니다. 또한 profile 출력에는 파라미터 설정 방식에 따른 순회의 실제 실행 통계도 포함됩니다.
앵커리지의 모든 공항 버텍스를 찾는 단순 순회를 다시 예로 들어 보겠습니다.
g.V().has('code','ANC')
explain API와 마찬가지로 REST 호출을 사용하여 profile API를 간접적으로 호출할 수 있습니다.
curl -X POST https://your-neptune-endpoint:port/gremlin/profile -d '{"gremlin":"g.V().has('code','ANC')"}'
Neptune 워크벤치의 %%gremlin 셀 매직도 profile 파라미터와 함께 사용할 수 있습니다. 그러면 셀 본문에 포함된 순회가 Neptune profile API로 전달되고 셀을 실행할 때 결과 출력이 표시됩니다.
%%gremlin profile g.V().has('code','ANC')
결과 profile API 출력에는 다음 이미지에서 볼 수 있듯이 순회에 대한 Neptune의 실행 계획과 계획 실행에 대한 통계가 모두 포함됩니다.
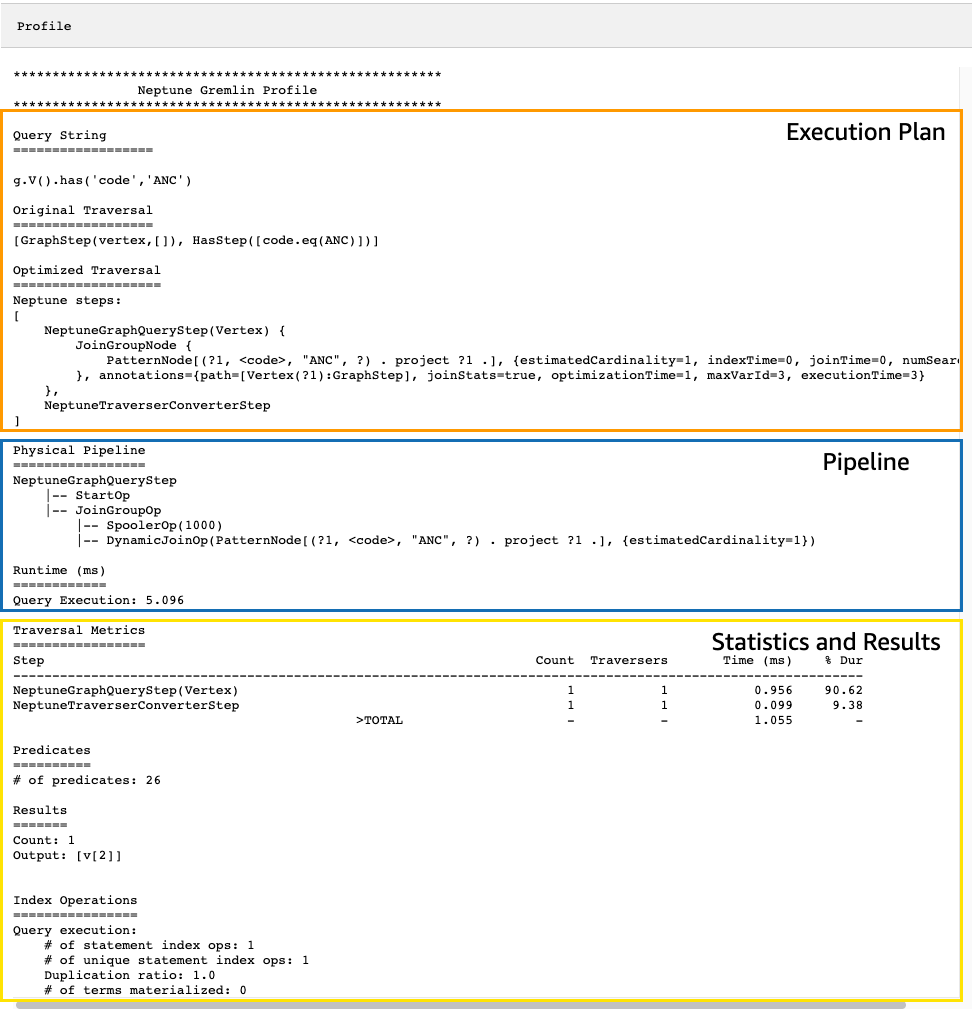
profile 출력에서 실행 계획 섹션에는 순회에 대한 최종 실행 계획만 포함되며, 중간 단계는 포함되지 않습니다. 파이프라인 섹션에는 수행된 물리적 파이프라인 작업과 순회 실행에 걸린 실제 시간(밀리초)이 포함됩니다. 런타임 지표는 서로 다른 두 버전의 순회를 최적화하기 위해 걸리는 시간을 비교하는 데 매우 유용합니다.
참고
첫 번째 실행으로 인해 관련 데이터가 캐싱되기 때문에 순회의 초기 런타임은 일반적으로 후속 런타임보다 깁니다.
profile 출력의 세 번째 섹션에는 실행 통계와 순회 결과가 포함됩니다. 이 정보가 순회 조정에 얼마나 유용한지 알아보려면 이름이 'Anchora'로 시작하는 모든 공항과 해당 공항에서 두 번의 홉으로 도달할 수 있는 모든 공항을 찾아 공항 코드, 비행 경로 및 거리를 반환하는 다음 순회 방법을 고려해 보세요.
%%gremlin profile g.withSideEffect("Neptune#fts.endpoint", "{your-OpenSearch-endpoint-URL"). V().has("city", "Neptune#fts Anchora~"). repeat(outE('route').inV().simplePath()).times(2). project('Destination', 'Route'). by('code'). by(path().by('code').by('dist'))
Neptune profile API 출력의 순회 지표
모든 profile 출력에서 사용할 수 있는 첫 번째 지표 세트는 순회 지표입니다. 이러한 지표는 Gremlin profile() 단계 지표와 비슷하지만, 몇 가지 차이점이 있습니다.
Traversal Metrics ================= Step Count Traversers Time (ms) % Dur ------------------------------------------------------------------------------------------------------------- NeptuneGraphQueryStep(Vertex) 3856 3856 91.701 9.09 NeptuneTraverserConverterStep 3856 3856 38.787 3.84 ProjectStep([Destination, Route],[value(code), ... 3856 3856 878.786 87.07 PathStep([value(code), value(dist)]) 3856 3856 601.359 >TOTAL - - 1009.274 -
순회-지표 표의 첫 번째 열에는 순회에서 실행되는 단계가 나열됩니다. 처음 두 단계는 일반적으로 Neptune 관련 단계 NeptuneGraphQueryStep 및 NeptuneTraverserConverterStep입니다.
NeptuneGraphQueryStep은 Neptune 엔진에서 기본적으로 변환 및 실행할 수 있는 전체 순회 부분의 실행 시간을 나타냅니다.
NeptuneTraverserConverterStep은 변환된 단계의 출력을 TinkerPop Traverser로 변환하는 프로세스를 나타냅니다. TinkerPop Traverser는 변환할 수 없는 단계가 있는 경우, 이를 처리하거나 결과를 TinkerPop 호환 형식으로 반환할 수 있습니다.
위의 예에는 변환되지 않은 단계가 여러 개 있으므로, 각 TinkerPop 단계(ProjectStep, PathStep)가 표에 행으로 표시되는 것을 볼 수 있습니다.
표의 두 번째 열인 Count는 단계를 통과한 표현된 순회 수를 보고하고, 세 번째 열인 Traversers는 TinkerPop 프로필 단계 설명서
이 예제에서는 NeptuneGraphQueryStep에서 3,856개의 버텍스와 3,856개의 Traverser가 반환되며, 이 수치는 나머지 처리 과정에서 동일하게 유지됩니다. ProjectStep 및 PathStep은 결과를 필터링하는 것이 아니라 형식을 지정하기 때문입니다.
참고
TinkerPop과 달리 Neptune 엔진은 NeptuneGraphQueryStep 및 NeptuneTraverserConverterStep 단계를 대량 확장해서 성능을 최적화하지 않습니다. 대량 확장은 TinkerPop 연산으로 동일한 버텍스에 Traverser를 결합하여 운영 오버헤드를 줄이는 것으로, 이 때문에 Count 및 Traversers 숫자가 달라집니다. 대량 확장은 Neptune이 TinkerPop에 위임한 단계에서만 발생하고 Neptune이 기본적으로 처리하는 단계에서는 발생하지 않기 때문에 Count 및 Traverser 열이 흡사합니다.
시간 열에는 해당 단계에 걸린 시간(밀리초)이 표시되고, % Dur 열에는 해당 단계에 소요된 총 처리 시간의 백분율이 표시됩니다. 이는 가장 많은 시간이 소요된 단계를 표시하여 조정 작업을 어디에 집중해야 하는지를 알려주는 지표입니다.
Neptune profile API 출력의 인덱스 작업 지표
Neptune 프로필 API 출력의 또 다른 지표 세트는 인덱스 작업입니다.
Index Operations ================ Query execution: # of statement index ops: 23191 # of unique statement index ops: 5960 Duplication ratio: 3.89 # of terms materialized: 0
이 지표는 다음을 보고합니다.
인덱스 총 조회 수.
수행된 고유 인덱스 조회 수.
전체 인덱스 조회와 고유 인덱스 조회의 비율. (비율이 낮을수록 중복성 감소)
용어 딕셔너리에서 구체화된 용어 수.
Neptune profile API 출력의 반복 지표
순회에 위 예와 같은 repeat() 단계를 사용하는 경우 반복 지표가 포함된 섹션이 profile 출력에 나타납니다.
Repeat Metrics ============== Iteration Visited Output Until Emit Next ------------------------------------------------------ 0 2 0 0 0 2 1 53 0 0 0 53 2 3856 3856 3856 0 0 ------------------------------------------------------ 3911 3856 3856 0 55
이 지표는 다음을 보고합니다.
행의 루프 수(
Iteration열).루프가 방문한 요소 수(
Visited열).루프가 출력하는 요소 수(
Output열).루프가 출력하는 마지막 요소(
Until열).루프에서 내보내는 요소 수(
Emit열).루프에서 다음 루프로 전달된 요소 수(
Next열).
이러한 반복 지표는 순회의 분기 요인을 이해하고 데이터베이스에서 수행되고 있는 작업의 양을 파악하는 데 매우 유용합니다. 이 수치를 사용하여 성능 문제를 진단할 수 있습니다. 특히 동일한 순회라도 파라미터에 따라 성능이 크게 달라질 경우 더욱 그렇습니다.
Neptune profile API 출력의 전체 텍스트 검색 지표
위의 예와 같이 순회에서 전체 텍스트 검색 조회를 사용하는 경우 전체 텍스트 검색(FTS) 지표가 포함된 섹션이 profile 출력에 나타납니다.
FTS Metrics ============== SearchNode[(idVar=?1, query=Anchora~, field=city) . project ?1 .], {endpoint=your-OpenSearch-endpoint-URL, incomingSolutionsThreshold=1000, estimatedCardinality=INFINITY, remoteCallTimeSummary=[total=65, avg=32.500000, max=37, min=28], remoteCallTime=65, remoteCalls=2, joinTime=0, indexTime=0, remoteResults=2} 2 result(s) produced from SearchNode above
이는 ElasticSearch(ES) 클러스터로 전송된 쿼리를 보여주고, 전체 텍스트 검색과 관련된 성능 문제를 정확히 찾아내는 데 도움이 될 수 있는 ElasticSearch와의 상호 작용에 대한 몇 가지 지표를 보고합니다.
-
ElasticSearch 인덱스 호출에 대한 요약 정보:
모든 remoteCall이 쿼리를 충족하는 데 필요한 밀리초 단위의 총 시간(
total).remoteCall에 소요된 밀리초 단위의 평균 시간(
avg).remoteCall에 소요된 밀리초 단위의 최소 시간(
min).remoteCall에 소요된 밀리초 단위의 최대 시간(
max).
ElasticSearch에 대한 remoteCall에 소요된 총 시간(
remoteCallTime).ElasticSearch에 대한 remoteCall 수(
remoteCalls).ElasticSearch 결과의 조인에 소요된 밀리초 단위의 시간(
joinTime).인덱스 조회에 소요된 밀리초 단위의 시간(
indexTime).ElasticSearch에서 반환한 총 결과 수(
remoteResults).
