기계 번역으로 제공되는 번역입니다. 제공된 번역과 원본 영어의 내용이 상충하는 경우에는 영어 버전이 우선합니다.
지원되는 SSML 태그
Amazon Polly는 다음과 같은 SSML 태그를 지원합니다.
| 작업 | SSML 태그 | 뉴럴 보이스 사용 가능 여부 | 긴 형식의 음성을 사용할 수 있음 | 제너레이티브 보이스를 통한 가용성 |
|---|---|---|---|---|
|
<break> |
완전히 사용 가능 |
완전히 사용 가능 |
완전히 사용 가능 |
|
| <emphasis> |
사용할 수 없음 |
사용할 수 없음 |
사용할 수 없음 |
|
| <lang> |
완전히 사용 가능 |
완전히 사용 가능 |
완전히 사용 가능 |
|
| <mark> |
완전히 사용 가능 |
완전히 사용 가능 |
완전히 사용 가능 |
|
|
<p> |
완전히 사용 가능 |
완전히 사용 가능 |
완전히 사용 가능 |
|
|
<phoneme> |
완전히 사용 가능 |
완전히 사용 가능 |
사용할 수 없음 |
|
|
<prosody> |
부분 사용 가능 |
부분 사용 가능 |
사용할 수 없음 |
|
|
<prosody amazon:max-duration> |
사용할 수 없음 |
사용할 수 없음 |
사용할 수 없음 |
|
|
<s> |
완전히 사용 가능 |
완전히 사용 가능 |
완전히 사용 가능 |
|
|
<say-as> |
부분 사용 가능 |
부분 사용 가능 |
부분 사용 가능 |
|
|
<speak> |
완전히 사용 가능 |
완전히 사용 가능 |
완전히 사용 가능 |
|
|
<sub> |
완전히 사용 가능 |
완전히 사용 가능 |
완전히 사용 가능 |
|
|
<w> |
완전히 사용 가능 |
완전히 사용 가능 |
완전히 사용 가능 |
|
|
<amazon:auto-breaths> |
사용할 수 없음 |
사용할 수 없음 |
사용할 수 없음 |
|
| <amazon:domain name="news"> |
신경 음성만 선택 |
사용할 수 없음 |
사용할 수 없음 |
|
|
<amazon:effect name="drc"> |
완전히 사용 가능 |
완전히 사용 가능 |
사용할 수 없음 |
|
|
<amazon:effect phonation="soft"> |
사용할 수 없음 |
사용할 수 없음 |
사용할 수 없음 |
|
|
vocal-tract-length<아마존:이펙트 > |
사용할 수 없음 |
사용할 수 없음 |
사용할 수 없음 |
|
|
<amazon:effect name="whispered"> |
사용할 수 없음 |
사용할 수 없음 |
사용할 수 없음 |
참고
지원되지 않는 SSML 태그를 표준, 신경 또는 롱폼 형식으로 사용할 경우 오류가 발생합니다.
SSML로 확장된 텍스트 식별
<speak>
이 태그는 생성형, 장형, 신경망 및 표준 TTS 형식에서 지원됩니다.
<speak> 태그는 모든 Amazon Polly SSML 텍스트의 루트 요소입니다. SSML로 확장된 모든 텍스트는 한 쌍의 <speak> 태그로 묶여야 합니다.
<speak>Mary had a little lamb.</speak>일시 중지 추가
<break>
이 태그는 제너레이티브, 롱폼, 뉴럴 및 표준 TTS 형식에서 지원됩니다.
텍스트에 일시 중지를 추가하려면 <break> 태그를 사용합니다. 강도를 기준으로 일시 중지를 설정하거나(쉼표, 문장 또는 단락 다음에 오는 일시 중지에 해당), 특정 시간 길이(초 또는 밀리초)로 설정할 수 있습니다. 일시 중지 길이를 결정할 속성을 지정하지 않을 경우, Amazon Polly는 기본값인 <break
strength="medium"/>을 사용합니다. 이는 쉼표 다음에 일시 중지를 추가합니다.
strength 속성 값
-
none: 일시 중지가 존재하지 않습니다.none을 사용하여 마침표 뒤와 같이 일반적으로 발생하는 일시 중지를 제거합니다. -
x-weak:none과 동일한 강도를 지니며 일시 중지가 없습니다. -
weak: 쉼표 다음에 오는 일시 중지와 동일한 지속 시간의 일시 중지를 설정합니다. -
medium:weak와 동일한 강도를 지닙니다. -
strong: 문장 다음에 오는 일시 중지와 동일한 지속 시간의 일시 중지를 설정합니다. -
x-strong: 단락 다음에 오는 일시 중지와 동일한 지속 시간의 일시 중지를 설정합니다.
time 속성 값
-
[number]s10s입니다. -
[number]ms10000ms입니다.
예:
<speak>
Mary had a little lamb <break time="3s"/>Whose fleece was white as snow.
</speak>속성을 break 태그와 함께 사용하지 않는 경우, 결과는 텍스트에 따라 달라집니다.
-
break태그 옆에 다른 문장 부호가 없는 경우,<break strength="medium"/>(쉼표 길이 일시 중지)이 생성됩니다. -
태그가 쉼표 옆에 있는 경우, 태그가
<break strength="strong"/>(문장 길이 일시 중지)으로 업그레이드됩니다. -
태그가 마침표 옆에 있는 경우, 태그가
<break strength="x-strong"/>(단락 길이 일시 중지)으로 업그레이드됩니다.
단어 강조
<emphasis>
표준 TTS 형식만 이 태그를 지원합니다.
단어를 강조하려면 <emphasis> 태그를 사용합니다. 단어를 강조하면 말하기 속도와 볼륨이 변경됩니다. 더 강조하면 Amazon Polly가 텍스트를 더 크고 느리게 읽습니다. 덜 강조하면 더 작고 빠르게 읽습니다. 강조 수준을 지정하려면 level 속성을 사용합니다.
level 속성 값
-
Strong: 스피치가 더 크고 느려지도록 볼륨을 높이고 말하기 속도를 늦춥니다. -
Moderate: 볼륨을 높이고 말하기 속도가 느려지지만strong일 때보다는 덜합니다. 기본값은Moderate입니다. -
Reduced: 볼륨을 낮추고 말하기 속도를 높입니다. 스피치가 부드럽고 빨라집니다.
참고
음성의 일반적인 말하기 속도 및 볼륨은 moderate 수준과 reduced 수준 사이입니다.
예:
<speak> I already told you I <emphasis level="strong">really like</emphasis> that person. </speak>
특정 단어에 대하여 다른 언어 지정
<lang>
이 태그는 제너레이티브, 롱폼, 뉴럴 및 표준 TTS 형식에서 지원됩니다.
<lang> 태그를 사용하여 특정 단어, 문구 또는 문장에 대해 다른 언어를 지정합니다. 일반적으로 외국어(단어 및 구)를 한 쌍의 <lang> 태그로 묶으면 더 잘 읽혀집니다. 언어를 지정하려면 xml:lang 속성을 사용합니다. 사용 가능한 언어에 대한 전체 목록은 Amazon Polly의 언어를 참조하세요.
<lang> 태그를 적용하지 않으면 입력 텍스트 안의 모든 단어를 voice-id에 지정한 음성의 언어로 읽습니다. <lang> 태그를 적용하면 단어를 해당 언어로 읽습니다.
예를 들어 voice-id이(가) (미국 영어 원어민인) Joanna인 경우 Amazon Polly는 다음 문장을 프랑스어 억양을 사용하지 않고 Joanna 음성으로 읽습니다.
<speak>
Je ne parle pas français.
</speak><lang> 태그와 함께 Joanna 음성을 사용하면 Amazon Polly는 그 문장을 Joanna 음성을 통해 미국식 억양의 불어로 읽습니다.
<speak>
<lang xml:lang="fr-FR">Je ne parle pas français.</lang>.
</speak>Joanna의 음성은 원어민 프랑스어가 아니기 때문에 발음은 그녀의 모국인 미국 영어를 따릅니다. 예를 들면, 완벽한 프랑스어 발음에서는 단어 français에 목젖 울림 /R/이 있지만, Joanna의 미국식 영어 음성은 이 음소를 그에 해당하는 /r/ 소리로 발음합니다.
다음 텍스트에 이탈리아어 원어민인 Giorgio의 voice-id를 사용하면 Amazon Polly는 해당 문장을 Giorgio 음성을 통해 이탈리아어식으로 발음합니다.
<speak>
Mi piace Bruce Springsteen.
</speak>동일한 음성을 다음 <lang> 태그와 함께 사용하면 Amazon Polly는 Bruce Springsteen을 이탈리아식 억양의 영어로 발음합니다.
<speak>
Mi piace <lang xml:lang="en-US">Bruce Springsteen.</lang>
</speak>이 태그는 음성을 합성할 때 옵션 DefaultLangCode옵션 대신 사용할 수도 있습니다. 그러나, 이렇게 하려면 SSML을 사용하여 텍스트 서식을 지정해야 합니다.
텍스트에 사용자 지정 태그 배치
<mark>
이 태그는 제너레이티브, 롱폼, 뉴럴 및 표준 TTS 포맷에서 지원됩니다.
텍스트 내에 사용자 지정 태그를 넣으려면 <mark> 태그를 사용합니다. Amazon Polly는 태그에 대해 아무 조치도 취하지 않지만 SSML 메타데이터에서 태그의 위치를 반환합니다. 이 태그의 이름은 다음 형식에 따른 것이라면 어떤 것이든 가능합니다.
<mark name="tag_name"/>예를 들어, 태그 이름이 "animal"인 경우 입력 텍스트는 다음과 같습니다.
<speak>
Mary had a little <mark name="animal"/>lamb.
</speak>Amazon Polly는 다음 SSML 메타데이터를 반환할 수 있습니다.
{"time":767,"type":"ssml","start":25,"end":46,"value":"animal"}단락 사이에 일시 중지 추가
<p>
이 태그는 제너레이티브, 롱폼, 뉴럴 및 표준 TTS 형식에서 지원됩니다.
텍스트의 단락 사이에 일시 중지를 추가하려면 <p> 태그를 사용합니다. 이 태그를 사용하면 쉼표가 있는 자리나 문장 끝에 원어민이 대체로 사용하는 것보다 긴 일시 중지가 적용됩니다. <p> 태그를 사용해 단락을 묶습니다.
<speak>
<p>This is the first paragraph. There should be a pause after this text is spoken.</p>
<p>This is the second paragraph.</p>
</speak>이는 <break strength="x-strong"/>를 사용해 일시 중지를 지정하는 것과 동일합니다.
철자대로의 발음 사용
<phoneme>
이 태그는 롱폼, 신경 및 표준 TTS 형식으로 지원됩니다.
Amazon Polly에서 특정 텍스트에 대해 철자대로의 발음을 사용하게 하려면 <phoneme> 태그를 사용합니다.
두 속성에는 <phoneme> 태그가 필요합니다. 이러한 태그는 Amazon Polly에서 사용되는 음성 기호와 정확한 발음을 위한 발음 기호를 나타냅니다.
-
alphabet-
ipa- IPA(International Phonetic Alphabet)가 사용되어야 함을 나타냅니다. -
x-sampa- X-SAMPA(Extended Speech Assessment Methods Phonetic Alphabet)가 사용되어야 함을 나타냅니다.
-
-
ph-
발음에 사용될 발음 기호를 지정합니다. 자세한 정보는 지원되는 언어의 음소 및 Viseme 표을(를) 참조하세요.
-
<phoneme> 태그를 사용하면, Amazon Polly는 선택된 음성이 사용하는 언어와 기본값으로써 연결되는 표준 발음 대신 ph 속성이 지정한 발음을 사용합니다.
예를 들어, 단어 "pecan"은 두 가지 방식으로 발음될 수 있습니다. 다음 예제에서는 “pecan”에 각 줄마다 다른 발음이 할당됩니다. Amazon Polly는 기본 발음을 사용하는 대신 ph 속성에 지정된 대로 pecan을 발음합니다.
IPA(International Phonetic Alphabet)
<speak> You say, <phoneme alphabet="ipa" ph="pɪˈkɑːn">pecan</phoneme>. I say, <phoneme alphabet="ipa" ph="ˈpi.kæn">pecan</phoneme>. </speak>
X-SAMPA(Extended Speech Assessment Methods Phonetic Alphabet)
<speak> You say, <phoneme alphabet='x-sampa' ph='pI"kA:n'>pecan</phoneme>. I say, <phoneme alphabet='x-sampa' ph='"pi.k{n'>pecan</phoneme>. </speak>
또한 표준 중국어는 음운 발음에 병음을 사용합니다.
병음
<speak> 你说 <phoneme alphabet="x-amazon-pinyin" ph="bo2">薄</phoneme>。 我说 <phoneme alphabet="x-amazon-pinyin" ph="bao2">薄</phoneme>。 </speak>
일본어는 요미가나와 가나 발음을 사용합니다.
요미가나
<speak> 名前は<phoneme alphabet="x-amazon-yomigana" ph="ひろかず">浩一</phoneme>です。 名前は<phoneme alphabet="x-amazon-yomigana" ph="ヒロカズ">浩一</phoneme>です。 名前は<phoneme alphabet="x-amazon-yomigana" ph="Hirokazu">浩一</phoneme>です。 </speak>
발음: 가나
<speak> 名前は<phoneme alphabet="x-amazon-pron-kana" ph="ヒロ'カズ">浩一</phoneme>です。 </speak>
볼륨, 말하기 속도 및 피치 제어
<prosody>
Prosody 태그 속성은 표준 TTS 음성으로 완벽하게 지원됩니다. 신경 및 롱폼 음성은 volume 및 rate 속성을 지원하지만 pitch 속성은 지원하지 않습니다.
선택된 음성의 볼륨, 속도 또는 피치를 제어하려면 prosody 태그를 사용합니다.
볼륨, 스피치 속도 및 피치는 선택된 특정 음성에 따라 다릅니다. 서로 다른 언어를 사용하는 음성 간의 차이 외에도 동일한 언어를 사용하는 각 개인의 음성 간에도 차이가 존재합니다. 따라서 속성은 모든 언어에 걸쳐 유사하지만 각 언어들 사이에 분명한 차이가 존재하며 절대값이란 있을 수 없습니다.
prosody 태그에는 세 개의 속성이 있으며 각 속성에는 해당 속성을 설정하는 데 사용 가능한 몇 가지 값이 있습니다. 각 속성은 동일한 구문을 사용합니다.
<prosody attribute="value"></prosody>-
volume-
default: 볼륨을 현재 음성의 기본 수준으로 재설정합니다. -
silent,x-soft,soft,medium,loud,x-loud: 볼륨을 현재 음성에 사전 정의된 값으로 설정합니다. -
+ndB,-ndB: 볼륨을 현재 볼륨 레벨으로부터 가감합니다.+0dB값은 변경 없음,+6dB값은 현재 볼륨의 약 2배,-6dB값은 현재 볼륨의 약 절반을 의미합니다.
예를 들어, 특정 구절의 볼륨을 다음과 같은 방식으로 설정할 수 있습니다.
<speak> Sometimes it can be useful to <prosody volume="loud">increase the volume for a specific speech.</prosody> </speak>또는 다음과 같은 방식으로 설정할 수 있습니다.
<speak> And sometimes a lower volume <prosody volume="-6dB">is a more effective way of interacting with your audience.</prosody> </speak> -
-
rate-
x-slow,slow,medium,fast,x-fast. 선택된 음성에 대해 피치를 사전 정의된 값으로 설정합니다. -
n%: 말하기 속도의 백분율 가감 예를 들어 100%의 값은 말하기 속도를 변경하지 않는 것이고, 200%의 값은 기본 속도의 2배에 해당하는 말하기 속도를 의미하며 50%의 값은 기본 속도의 절반에 해당하는 말하기 속도를 의미합니다. 이 값의 범위는 20%~200%입니다.
예를 들어, 특정 구절의 스피치 속도를 다음과 같은 방식으로 설정할 수 있습니다.
<speak> For dramatic purposes, you might wish to <prosody rate="slow">slow up the speaking rate of your text.</prosody> </speak>또는 다음과 같은 방식으로 설정할 수 있습니다.
<speak> Although in some cases, it might help your audience to <prosody rate="85%">slow the speaking rate slightly to aid in comprehension.</prosody> </speak> -
-
pitch-
default: 현재 음성의 음색을 기본 수준으로 재설정합니다. -
x-low,low,medium,high,x-high: 현재 음성의 음색을 사전 정의된 값으로 설정합니다. -
+n%또는-n%: 상대적 백분율로 음색을 조절합니다. 예를 들어 값+0%는 기준 음색 변경이 없음을 의미하고,+5%는 약간 더 높은 기준 음색을 제공하며,-5%는 약간 더 낮은 기준 음색을 가져옵니다.
예를 들어, 특정 구절의 피치를 다음과 같은 방식으로 설정할 수 있습니다.
<speak> Do you like sythesized speech <prosody pitch="high">with a pitch that is higher than normal?</prosody> </speak>또는 다음과 같은 방식으로 설정할 수 있습니다.
<speak> Or do you prefer your speech <prosody pitch="-10%">with a somewhat lower pitch?</prosody> </speak> -
<prosody> 태그는 최소 1개의 속성을 포함해야 하나, 동일한 태그 안에 여러 개를 포함할 수도 있습니다.
<speak> Each morning when I wake up, <prosody volume="loud" rate="x-slow">I speak quite slowly and deliberately until I have my coffee.</prosody> </speak>
또한 다음과 같은 방식으로 중첩된 태그와 조합할 수 있습니다.
<speak> <prosody rate="85%">Sometimes combining attributes <prosody pitch="-10%">can change the impression your audience has of a voice</prosody> as well.</prosody> </speak>
합성된 스피치의 최대 기간 설정
<prosody amazon:max-duration>
현재 TTS 형식만 이 태그를 지원합니다.
합성될 때 스피치에 걸리는 시간을 제어하려면 <prosody> 태그를 amazon:max-duration 속성과 함께 사용합니다.
합성된 스피치의 기간은 선택한 음성에 따라 조금 다릅니다. 이로 인해 합성된 스피치를 정확한 시간이 필요한 시각 자료 또는 기타 활동과 일치시킬 수 없을 수 있습니다. 이 문제는 특정 구가 다른 언어와 크게 다를 수 있다고 말하는 데 걸리는 시간 때문에 번역 애플리케이션의 경우 더 확대됩니다.
<prosody amazon:max-duration> 태그는 합성된 스피치를 원하는 시간(기간)과 일치시킵니다.
이 태그는 다음 구문을 사용합니다.
<prosody amazon:max-duration="time duration"><prosody amazon:max-duration> 태그를 사용하면 기간을 초 또는 밀리초 단위로 지정할 수 있습니다.
-
ns -
nms
예를 들어, 다음 말한 텍스트의 최대 기간은 2초입니다.
<speak>
<prosody amazon:max-duration="2s">
Human speech is a powerful way to communicate.
</prosody>
</speak>태그 안에 배치된 텍스트는 지정된 기간을 초과하지 않습니다. 선택한 음성 또는 언어가 일반적으로 기간보다 더 오래 걸리는 경우 Amazon Polly에서는 지정된 기간과 맞도록 스피치 속도를 높입니다.
지정된 기간이 일반 속도로 텍스트를 읽는 데 걸리는 시간보다 긴 경우 Amazon Polly에서는 스피치를 일반적으로 읽습니다. 스피치 속도를 줄이거나 무음을 추가하지 않으므로 결과 오디오가 요청된 사항보다 더 짧습니다.
참고
Amazon Polly에서는 일반 속도의 5배 이상으로 속도를 올리지 않습니다. 이 속도보다 빠르게 텍스트를 읽는 경우는 일반적으로 성립되지 않습니다. 스피치 속도를 최대로 올리는 경우에도 지정된 기간에 스피치를 맞출 수 없는 경우 오디오 속도가 높아지지만 지정된 기간보다 오래 지속됩니다.
<prosody amazon:max-duration> 태그에 한 문장 또는 여러 문장을 포함할 수 있으며, 텍스트 내에 여러 <prosody amazon:max-duration> 태그를 사용할 수 있습니다.
예:
<speak> <prosody amazon:max-duration="2400ms"> Human speech is a powerful way to communicate. </prosody> <break strength="strong"/> <prosody amazon:max-duration="5100ms"> Even a simple ‘Hello’ can convey a lot of information depending on the pitch, intonation, and tempo. </prosody> <break strength="strong"/> <prosody amazon:max-duration="8900ms"> We naturally understand this information, which is why speech is ideal for creating applications where a screen isn’t practical or possible, or simply isn’t convenient. </prosody> </speak>
<prosody amazon:max-duration> 태그를 사용하면 Amazon Polly에서 합성된 스피치가 반환될 때 지연 시간이 늘어날 수 있습니다. 지연의 정도는 특정 구절 및 구절의 길이에 따라 다릅니다. 비교적 짧은 텍스트 구절로 구성된 텍스트를 사용하는 것이 좋습니다.
제한 사항
<prosody
amazon:max-duration> 태그 사용 방법과 이 태그가 다른 SSML 태그와 함께 작동하는 방법 모두에 제한이 있습니다.
-
<prosody amazon:max-duration>태그 내에 있는 텍스트는 1500자를 초과할 수 없습니다. -
<prosody amazon:max-duration>태그를 중첩할 수 없습니다. 다른 태그 내에<prosody amazon:max-duration>태그 하나를 배치하는 경우 Amazon Polly에서는 내부 태그를 무시합니다.예를 들어, 다음의 경우
<prosody amazon:max-duration="5s">태그가 무시됩니다.<speak> <prosody amazon:max-duration="16s"> Human speech is a powerful way to communicate. <prosody amazon:max-duration="5s"> Even a simple ‘Hello’ can convey a lot of information depending on the pitch, intonation, and tempo. </prosody> We naturally understand this information, which is why speech is ideal for creating applications where a screen isn’t practical or possible, or simply isn’t convenient. </prosody> </speak> -
<prosody>태그를rate태그 내의<prosody amazon:max-duration>속성과 함께 사용할 수 없습니다. 이는 텍스트를 말할 때 해당 태그와 속성이 모두 속도에 영향을 주기 때문입니다.다음 예에서 Amazon Polly는
<prosody rate="2">태그를 무시합니다.<speak> <prosody amazon:max-duration="7500ms"> Human speech is a powerful way to communicate. <prosody rate="2"> Even a simple ‘Hello’ can convey a lot of information depending on the pitch, intonation, and tempo. </prosody> </prosody> </speak>
일시 중지 및 max-duration
max-duration 태그를 사용하면 텍스트 내에 일시 중지를 계속 삽입할 수 있습니다. 그러나 Amazon Polly에서는 스피치의 최대 기간을 계산할 때 일시 중지의 길이를 포함합니다. 또한 Amazon Polly에서는 쉼표와 마침표가 구절 내에 배치되어 있는 경우 발생하는 짧은 일시 중지를 유지하며, 이를 최대 기간에 포함합니다.
예를 들어, 다음 블록에서 600밀리초의 브레이크와 쉼표 및 마침표로 인해 발생한 브레이크는 8초 스피치 내에서 발생합니다.
<speak> <prosody amazon:max-duration="8s"> Human speech is a powerful way to communicate. <break time="600ms"/> Even a simple ‘Hello’ can convey a lot of information depending on the pitch, intonation, and tempo. </prosody> </speak>
문장 사이에 일시 중지 추가
<s>
이 태그는 제너레이티브, 롱폼, 뉴럴 및 표준 TTS 형식에서 지원됩니다.
텍스트의 행 또는 문장 사이에 일시 중지를 추가하려면 <s>p> 태그를 사용합니다. 이 태그를 사용하면 다음과 동일한 효과가 나옵니다.
-
마침표(.)로 끝나는 문장
-
<break strength="strong"/>으로 일시 중지 지정
<break> 태그와 달리, <s> 태그로 문장을 묶습니다. 이러한 방식은 시(詩)처럼 문장보다는 행으로 이루어진 스피치를 합성하는 데 유용합니다.
다음 예에서는 <s> 태그로 첫 번째 문장과 두 번째 문장 다음에 모두 일시 중지를 짧게 생성합니다. 최종 문장에는 <s> 태그가 없지만 문장 끝에 마침표가 있으므로 문장 뒤에 짧은 일시 중지가 생기게 됩니다.
<speak> <s>Mary had a little lamb</s> <s>Whose fleece was white as snow</s> And everywhere that Mary went, the lamb was sure to go. </speak>
특별한 유형의 단어를 말하는 방식 제어
<say-as>
characters옵션을 제외한 <say-as> 태그는 제너레이티브, 롱폼, 뉴럴 및 표준 TTS 포맷에서 지원됩니다. Amazon Polly가 신경 음성을 사용 중이고 런타임에 characters 옵션이 포함된 <say-as> 태그가 발견되는 경우 영향을 받는 문장이 관련 표준 음성을 사용하여 합성된다는 점에 유의하세요. 하지만 영향을 받은 문장에는 여전히 신경망 음성을 사용하는 것처럼 요금이 청구됩니다.
<say-as> 태그에서 interpret-as 속성을 사용하여 Amazon Polly에게 특정 문자, 단어 또는 숫자를 읽는 방식을 알려줍니다. 이 태그를 사용하면 추가 컨텍스트를 제공하여 Amazon Polly가 텍스트를 렌더링하는 방법에 대한 모든 불확실성을 제거할 수 있습니다.
<say-as> 태그는 1개의 속성, interpret-as를 사용하는데 이 속성은 여러 개의 사용 가능한 값을 사용합니다. 각각은 동일한 구문을 사용합니다.
<say-as interpret-as="value">[text to be interpreted]</say-as>interpret-as에는 다음과 같은 값을 사용할 수 있습니다.
-
characters또는spell-out: 에서와 같이 텍스트의 각 글자를 입력합니다. a-b-c참고
신경 음성의 경우 현재 이 옵션이 지원되지 않습니다. 신경망 음성을 사용 중이고 런타임 시 Amazon Polly에서 이 SSML 코드를 발견하면 영향을 받는 문장이 관련 표준 음성을 사용하여 합성됩니다. 하지만 신경 음성을 사용하는 것처럼 이 문장에 요금이 부과된다는 점에 유의하세요.
-
cardinal또는number: 숫자로 된 텍스트를 1,234와 같이 값을 기수로 해석합니다. -
ordinal: 숫자로 된 텍스트를 1,234번째와 같이 서수로 해석합니다. -
digits: 1-2-3-4와 같이 각 자릿수를 개별적으로 발음합니다. -
fraction: 숫자로 된 텍스트를 분수로 해석합니다. 이 태그는 3/20과 같은 일반 분수와 2 ½과 같은 혼합 분수 모두에 적용됩니다. 자세한 내용은 아래를 참조하세요. -
unit: 숫자로 된 텍스트를 측정값으로 해석합니다. 값은1/2inch와 같이 숫자 또는 분수 다음에, 사이의 공백이 없이, 단위 1가지가 뒤따르거나.1meter와 같이 오직 1단위만 있어야 합니다. -
date: 텍스트를 날짜로 해석합니다. 날짜의 형식은 형식 속성과 함께 지정되어야 합니다(아래 참조). 자세한 내용은 아래를 참조하세요. -
time:1'21"과 같이 숫자로 된 텍스트를 기간(분과 초)으로 해석합니다. -
address: 텍스트를 거리 주소의 일부분으로 해석합니다. -
expletive: 태그 내에 포함된 콘텐츠에 "삐" 소리를 냅니다. -
telephone:2025551212과 같이 숫자로 된 텍스트를 7자리 또는 10자리의 전화 번호로 해석합니다. 또한2025551212x345와 같이 이 값을 전화 번호에 구내 번호를 추가하는 데 사용할 수도 있습니다. 자세한 내용은 아래를 참조하세요.참고
현재 모든 언어에서
telephone옵션을 사용할 수 있는 것은 아닙니다. 그러나 영어 변종(en-AU, en-GB, en-IN, en-US 및 en-GB-WLS), 스페인어 변종(es-ES, es-MX 및 es-US), 프랑스어 변종(fr-FR 및 fr-CA), 포르투갈어 변종(pt-BR 및 pt-PT), 독일어(de-DE), 이탈리아어(it-IT), 일본어(ja-JP), 러시아어(ru-RU)에서는 사용할 수 있습니다. 또한 아랍어 (arb) 와 같은 언어에서는 설정된 번호를 전화 번호로 자동 처리하므로 실제로 SSML 태그를 구현하지 않는 경우도 있다는 점도 유의해야 합니다.telephone
분수
Amazon Polly는 interpret-as="fraction" 속성을 갖는 say-as 태그 안의 값을 일반적인 분수로 해석합니다. 다음은 분수에 대한 구문입니다.
-
분수
구문:
기수/기수예: 2/9.예를 들어
<say-as interpret-as="fraction">2/9</say-as>는 "9분의 2"로 발음됩니다. -
음수가 아닌 혼수
구문:
기수+기수/기수예: 3+1/2.예를 들어
<say-as interpret-as="fraction">3+1/2</say-as>은 "삼과 이분의 일"로 발음됩니다.참고
“3"과 “1/2" 사이에는 반드시
+가 있어야 합니다. Amazon Polly는 “3 1/2"와 같이+가 없는 혼합 숫자를 지원하지 않습니다.
날짜
interpret-as가 date로 설정된 경우 날짜 형식도 나타내야 합니다.
이 방식은 다음 구문을 사용합니다.
<say-as interpret-as="date" format="format">[date]</say-as>
예:
<speak> I was born on <say-as interpret-as="date" format="mdy">12-31-1900</say-as>. </speak>
다음 형식은 date 속성과 함께 사용할 수 있습니다.
-
mdy: M. onth-day-year -
dmy: Day-month-year. -
ymd: 와이ear-month-day. -
md: 월-일 -
dm: 월-일 -
ym: 년-월 -
my: 년-월 -
d: 일. -
m: Month. -
y: Year. -
yyyymmdd: 와이ear-month-day. 이 형식을 사용하는 경우 Amazon Polly가 물음표를 사용하여 날짜의 일부분을 건너뛰도록 할 수 있습니다.예를 들어, Amazon Polly는 다음 항목을 "9월 22일"로 렌더링합니다.
<say-as interpret-as="date">????0922</say-as>Format은 필요하지 않기 때문입니다.
전화번호
Amazon Polly는 <say-as> 태그가 없어도 텍스트의 형식에 따라 올바르게 제공된 텍스트를 해석하려고 시도합니다. 예를 들어, 텍스트에 "202-555-1212"가 포함된 경우 Amazon Polly는 10자리 전화 번호로 해석한 다음 각 대시를 짧게 일시 중지하면서 각 개별 숫자를 따로따로 읽습니다. 이 경우 <say-as interpret-as="telephone">을 사용하지 않아도 됩니다. 그러나 텍스트 "2025551212"를 제공하고 Amazon Polly가 전화 번호로 말하기를 원하는 경우 <say-as
interpret-as="telephone">을 지정해야 합니다.
각 요소의 해석에 사용되는 논리는 언어별로 다릅니다. 예를 들어, 미국 및 영국 영어는 전화 번호를 발음하는 방법이 다릅니다. 영국 영어는 동일한 숫자가 이어서 나오면 "double five" 또는 "triple four"처럼 그룹으로 묶어서 말합니다. 그 차이점을 확인하려면 다음의 예를 미국 음성과 영국 음성으로 테스트해봅니다.
<speak> Richard's number is <say-as interpret-as="telephone">2122241555</say-as> </speak>
두문자어 및 약어 발음
<sub>
이 태그는 제너레이티브, 롱폼, 뉴럴 및 표준 TTS 형식에서 지원됩니다.
<sub> 태그를 alias 속성과 함께 사용하여 두문자어나 약어 등 선택된 텍스트를 다른 단어(또는 발음)로 대체합니다.
이때 다음 구문을 사용합니다.
<sub alias="new word">abbreviation</sub>다음 예에서는 오디오 콘텐츠의 의미를 더 선명히 하기 위해 해당 원소 기호를 "Mercury"란 통명으로 대체합니다.
<speak> My favorite chemical element is <sub alias="Mercury">Hg</sub>, because it looks so shiny. </speak>
스피치의 일부를 구체적으로 지정함으로써 발음 개선
<w>
이 태그는 제너레이티브, 롱폼, 뉴럴 및 표준 TTS 형식에서 지원됩니다.
<w> 태그를 사용해 해당 단어가 스피치 안에 위치하는 부분 또는 대체 의미를 구체적으로 지정하여 단어의 발음을 사용자 지정할 수 있습니다. role 속성을 사용하여 이를 수행합니다.
이 태그는 다음 구문을 사용합니다.
<w role="attribute">text</w>다음 값은 role 속성에 사용할 수 있습니다.
스피치의 일부를 지정하려면:
-
amazon:VB: 단어를 동사(단순 현재)로 해석합니다. -
amazon:VBD: 단어를 과거형 동사로 해석합니다. -
amazon:DT: 단어를 한정사로 해석합니다. -
amazon:IN: 단어를 전치사로 해석합니다. -
amazon:JJ: 단어를 형용사로 해석합니다. -
amazon:NN: 단어를 명사로 해석합니다.
예를 들어, "read" 단어의 미국식 영어 발음의 경우 이 단어가 스피치 안에 위치하는 부분에 따라 태그를 사용하여 다른 결과를 낼 수 있습니다.
<speak> The word <say-as interpret-as="characters">read</say-as> may be interpreted as either the present simple form <w role="amazon:VB">read</w>, or the past participle form <w role="amazon:VBD">read</w>. </speak>
특정 의미를 지정하려면
-
amazon:DEFAULT: 단어의 기본 의미를 사용합니다. -
amazon:SENSE_1: 있는 경우 단어의 기본이 아닌 의미를 사용합니다. 예를 들어 단어 "bass"는 의미에 따라 다르게 발음됩니다. 기본 의미는 화음에서 가장 낮은 부분입니다. 대체 의미는 민물고기의 한 종으로, 역시 "bass"라고 하지만 다르게 발음됩니다.<w role="amazon:SENSE_1">bass</w>을(를) 사용하면 해당 오디오 텍스트를 기본이 아닌 발음(민물고기)으로 렌더링합니다.
다음을 합성하면 발음과 의미의 차이를 들을 수 있습니다.
<speak> Depending on your meaning, the word <say-as interpret-as="characters">bass</say-as> may be interpreted as either a musical element: bass, or as its alternative meaning, a freshwater fish <w role="amazon:SENSE_1">bass</w>. </speak>
참고
일부 언어의 경우 지원되는 다른 스피치 부분을 선택할 수 있습니다.
숨소리 추가
<amazon:breath> 및 <amazon:auto-breaths>
표준 TTS 형식만 이 태그를 지원합니다.
자연스럽게 들리는 스피치에는 올바르게 말하는 단어와 숨소리가 모두 포함됩니다. 스피치 합성에 숨소리를 추가하면 더 자연스럽게 들리는 스피치를 만들 수 있습니다. <amazon:breath> 및 <amazon:auto-breaths> 태그는 숨소리를 제공합니다. 다음과 같은 옵션이 있습니다:
-
수동 모드: 사용자가 텍스트 내에 있는 숨소리의 위치, 길이, 볼륨을 설정합니다.
-
자동화 모드: Amazon Polly에서 숨소리를 스피치 출력에 자동으로 삽입합니다.
-
혼합 모드: 사용자와 Amazon Polly가 모두 숨소리를 추가합니다.
수동 모드
수동 모드에서는 숨소리를 배치할 입력 텍스트에 <amazon:breath/> 태그를 지정합니다. duration 및 volume 속성을 각각 사용하여 숨소리의 길이와 볼륨을 사용자 지정할 수 있습니다.
-
duration: 숨소리의 길이를 제어합니다. 유효한 값은default,x-short,short,medium,long,x-long입니다. 기본 값은medium입니다. -
volume: 숨소리가 얼마나 크게 들리는지를 제어합니다. 유효한 값은default,x-soft,soft,medium,loud,x-loud입니다. 기본 값은medium입니다.
참고
각 속성 값의 정확한 길이와 볼륨은 사용되는 특정 Amazon Polly 음성에 따라 다릅니다.
기본값을 사용하여 숨소리를 설정하려면 속성 없이 <amazon:breath/>을(를) 사용합니다.
예를 들어, 속성을 사용하여 숨소리의 기간과 볼륨을 중간으로 설정하려면 속성을 다음과 같이 설정합니다.
<speak> Sometimes you want to insert only <amazon:breath duration="medium" volume="x-loud"/>a single breath. </speak>
기본값을 사용하려면 태그만 사용합니다.
<speak> Sometimes you need <amazon:breath/>to insert one or more average breaths <amazon:breath/> so that the text sounds correct. </speak>
다음과 같이 구절 내에 개별 숨소리를 추가할 수 있습니다.
<speak> <amazon:breath duration="long" volume="x-loud"/> <prosody rate="120%"> <prosody volume="loud"> Wow! <amazon:breath duration="long" volume="loud"/> </prosody> That was quite fast. <amazon:breath duration="medium" volume="x-loud"/> I almost beat my personal best time on this track. </prosody> </speak>
자동화 모드
자동화 모드에서는 <amazon:auto-breaths> 태그를 사용하여 Amazon Polly에서 적절한 간격으로 숨소리 잡음을 자동으로 생성하도록 지정합니다. 간격의 빈도, 볼륨 및 기간을 설정할 수 있습니다. 자동화된 숨소리를 적용할 텍스트의 시작 부분에 </amazon:auto-breaths> 태그를 지정하고 끝 부분에 닫는 태그를 지정합니다.
참고
수동 모드 태그인 <amazon:breath/>와는 달리, <amazon:auto-breaths> 태그에는 닫는 태그(</amazon:auto-breaths>)가 필요합니다.
다음과 같은 옵션 속성을 <amazon:auto-breaths> 태그와 함께 사용할 수 있습니다.
-
volume: 숨소리가 얼마나 크게 들리는지를 제어합니다. 유효한 값은default,x-soft,soft,medium,loud,x-loud입니다. 기본 값은medium입니다. -
frequency: 텍스트에서 숨소리가 얼마나 자주 들리는지를 제어합니다. 유효한 값은default,x-low,low,medium,high,x-high입니다. 기본 값은medium입니다. -
duration: 숨소리의 길이를 제어합니다. 유효한 값은default,x-short,short,medium,long,x-long입니다. 기본 값은medium입니다.
기본적으로 숨소리의 빈도는 입력 텍스트에 따라 다릅니다. 하지만 주로 쉼표와 마침표 뒤에 숨소리가 들립니다.
다음 예제에서는 <amazon:auto-breaths> 태그를 사용하는 방법을 보여줍니다. 콘텐츠에 어떤 옵션을 사용할지 결정하려면 적용 가능한 예제를 Amazon Polly 콘솔에 복사하고 차이를 들어 봅니다.
-
옵션 파라미터 없이 자동화 모드를 사용합니다.
<speak> <amazon:auto-breaths>Amazon Polly is a service that turns text into lifelike speech, allowing you to create applications that talk and build entirely new categories of speech- enabled products. Amazon Polly is a text-to-speech service that uses advanced deep learning technologies to synthesize speech that sounds like a human voice. With dozens of lifelike voices across a variety of languages, you can select the ideal voice and build speech- enabled applications that work in many different countries.</amazon:auto-breaths> </speak> -
볼륨 제어와 함께 자동화 모드를 사용합니다. 비지정 파라미터(
duration및frequency)는 기본값(medium)으로 설정됩니다.<speak> <amazon:auto-breaths volume="x-soft">Amazon Polly is a service that turns text into lifelike speech, allowing you to create applications that talk and build entirely new categories of speech-enabled products. Amazon Polly is a text-to-speech service, that uses advanced deep learning technologies to synthesize speech that sounds like a human voice. With dozens of lifelike voices across a variety of languages, you can select the ideal voice and build speech- enabled applications that work in many different countries.</amazon:auto-breaths> </speak> -
빈도 제어와 함께 자동화 모드를 사용합니다. 비지정 파라미터(
duration및volume)는 기본값(medium)으로 설정됩니다.<speak> <amazon:auto-breaths frequency="x-low">Amazon Polly is a service that turns text into lifelike speech, allowing you to create applications that talk and build entirely new categories of speech-enabled products. Amazon Polly is a text-to-speech service, that uses advanced deep learning technologies to synthesize speech that sounds like a human voice. With dozens of lifelike voices across a variety of languages, you can select the ideal voice and build speech- enabled applications that work in many different countries.</amazon:auto-breaths> </speak> -
다중 파라미터와 함께 자동화 모드를 사용합니다. 비지정
Duration파라미터의 경우 Amazon Polly에서 기본값(medium)을 사용합니다.<speak> <amazon:auto-breaths volume="x-loud" frequency="x-low">Amazon Polly is a service that turns text into lifelike speech, allowing you to create applications that talk and build entirely new categories of speech-enabled products. Amazon Polly is a text-to-speech service, that uses advanced deep learning technologies to synthesize speech that sounds like a human voice. With dozens of lifelike voices across a variety of languages, you can select the ideal voice and build speech-enabled applications that work in many different countries.</amazon:auto-breaths> </speak>
뉴스 진행자 말투
<amazon:domain name="news">
뉴스 진행자 말투는 미국 영어(en-US) Matthew 및 Joanna 음성과 미국 스페인어(es-US) Lupe 음성, 영국 영어(en-GB) Amy 음성으로만 제공됩니다. Neural 형식을 사용할 때만 지원됩니다.
뉴스 진행자 스타일을 사용하려면 SSML 태그와 다음 구문을 사용합니다.
<amazon:domain name="news">text</amazon:domain>
예를 들어 다음과 같이 Amy 음성으로 뉴스 진행자 말투를 사용할 수 있습니다.
<speak> <amazon:domain name="news"> From the Tuesday, April 16th, 1912 edition of The Guardian newspaper: The maiden voyage of the White Star liner Titanic, the largest ship ever launched, has ended in disaster. The Titanic started her trip from Southampton for New York on Wednesday. Late on Sunday night she struck an iceberg off the Grand Banks of Newfoundland. By wireless telegraphy she sent out signals of distress, and several liners were near enough to catch and respond to the call. </amazon:domain> </speak>
동적 범위 압축 추가
<amazon:effect name="drc">
이 태그는 롱폼, 신경 및 표준 TTS 형식으로 지원됩니다.
오디오 파일에 사용된 텍스트, 언어, 음성에 따라 소리 크기는 작은 소리부터 큰 소리까지 다를 수 있습니다. 자동차 소리 같은 주변 소리로 인해 작은 소리가 가려져서 오디오 트랙을 정확히 듣기 어려울 수 있습니다. 오디오 파일의 특정 사운드 볼륨을 높이려면 동적 범위 압축(drc) 태그를 사용하세요.
drc 태그는 오디오에 중간 "크기" 임계값을 설정하고, 해당 임계값 주변의 사운드 볼륨(게인)을 높입니다. 즉, 경계값에 가장 가까우면 최대 게인이 적용되고, 경계값에서 멀수록 게인이 감소합니다.
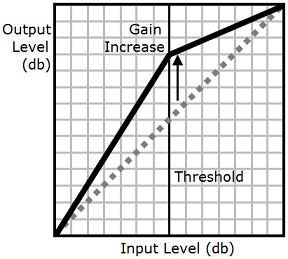
따라서 소음이 많은 환경에서 중간 크기 사운드를 쉽게 들을 수 있으며 오디오 파일을 전체적으로 듣기 쉽게 만듭니다.
drc 태그는 부울 파라미터입니다(참 또는 거짓). 이 태그는 <amazon:effect name="drc"> 구문을 사용하며 </amazon:effect>로 닫습니다.
drc 태그는 Amazon Polly에서 지원하는 모든 음성이나 언어에 사용할 수 있습니다. 녹음 전체 섹션에 적용하거나 몇 단에만 적용할 수 있습니다. 예:
<speak> Some audio is difficult to hear in a moving vehicle, but <amazon:effect name="drc"> this audio is less difficult to hear in a moving vehicle.</amazon:effect> </speak>
참고
구문에 "drc"를 사용하면 대소문자를 구별합니다.amazon:effect
drc 태그에 prosody
volume 사용
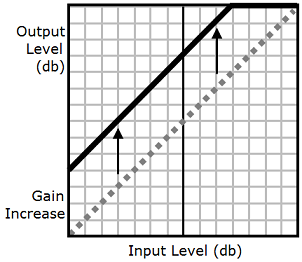
다음 그림에서 보는 것처럼, prosody
volume 태그는 전체 오디오 파일의 볼륨을 원래 수준(점선)에서 조정된 수준(실선)으로 균일하게 올립니다. 파일의 특정 부분 볼륨을 더 높이려면 drc 태그와 prosody
volume 태그를 함께 사용하세요. 조합 태그는 prosody volume 태그 설정에는 영향을 주지 않습니다.
drc 태그와 prosody
volume 태그를 함께 사용하면 Amazon Polly는 drc 태그를 먼저 적용하여 중간 크기 사운드(경계값에 가까운 사운드)를 강화합니다. 그런 다음 prosody volume 태그를 적용하여 전체 오디오 트랙의 볼륨을 균일하게 더 높입니다.
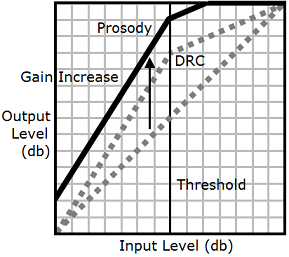
태그를 함께 사용하려면 한 태그를 다른 태그 내에 넣으세요. 예:
<speak> <prosody volume="loud">This text needs to be understandable and loud. <amazon:effect name="drc"> This text also needs to be more understandable in a moving car.</amazon:effect></prosody> </speak>
이 텍스트에서 prosody volume 태그는 전체 구절의 볼륨을 "크게" 높입니다. drc 태그는 둘째 문장에서 중간 크기 값의 볼륨을 강화합니다.
참고
drc 태그와 prosody
volume 태그를 함께 사용할 경우 중첩 태그에 대한 표준 XML 규칙을 사용하세요.
부드러운 어투
<amazon:effect phonation="soft">
현재 TTS 형식만 이 태그를 지원합니다.
<amazon:effect phonation="soft">입력 텍스트를 softer-than-normal 음성으로 말하도록 지정하려면 태그를 사용하세요.
이때 다음 구문을 사용합니다.
<amazon:effect phonation="soft">text</amazon:effect>예를 들어, 이 태그에서 Matthew 음성을 다음과 같은 방식으로 사용할 수 있습니다.
<speak> This is Matthew speaking in my normal voice. <amazon:effect phonation="soft">This is Matthew speaking in my softer voice.</amazon:effect> </speak>
음색 제어
vocal-tract-length<아마존:이펙트 >
현재 TTS 형식만 이 태그를 지원합니다.
음색은 음의 고저가 같을 때도 음성 간의 차이를 알 수 있는 특징입니다. 음색을 내는 가장 중요한 생리적 특성 중 하나는 성대의 길이이며, 성대주름에서 입술 가장자리까지의 공기 통로입니다.
Amazon Polly에서 스피치의 음색을 조절하려면 vocal-tract-length 태그를 사용합니다. 이 태그는 말하는 사람의 성도 길이를 변경하여 다르게 들리게 합니다. vocal-tract-length을(를) 늘리면 말하는 사람의 음성이 더 커집니다. 반대로 줄이면 음성이 작아집니다. 이 태그는 Amazon Polly Text-to-Speech 포트폴리오에 있는 모든 음성에 사용할 수 있습니다.
음색을 변경하려면 다음 값을 사용합니다.
-
+n%또는-n%: 현재 음성의 현재 음색 레벨을 상대적 백분율로 변경하여 성도 길이를 조정합니다. 예를 들어 +4% 또는 -2% 등으로 지정할 수 있습니다. 유효한 값은 +100%부터 -50%까지입니다. 이 범위를 벗어나는 값은 잘립니다. 예를 들어 +111%는 +100%와 동일하게 적용되고 -60%은 -50%와 동일하게 적용됩니다. -
n%: 현재 음성 성도 길이의 절대 백분율로 성도 길이를 변경합니다. 예를 들어 110% 또는 75% 등으로 지정합니다. 절대값 110%는 상대값 +10%와 동일합니다. 절대값 100%는 현재 음성의 기본값과 동일합니다.
다음 예는 성도 길이를 변경하여 음색을 변경하는 방법을 보여줍니다.
<speak> This is my original voice, without any modifications. <amazon:effect vocal-tract-length="+15%"> Now, imagine that I am much bigger. </amazon:effect> <amazon:effect vocal-tract-length="-15%"> Or, perhaps you prefer my voice when I'm very small. </amazon:effect> You can also control the timbre of my voice by making minor adjustments. <amazon:effect vocal-tract-length="+10%"> For example, by making me sound just a little bigger. </amazon:effect><amazon:effect vocal-tract-length="-10%"> Or, making me sound only somewhat smaller. </amazon:effect> </speak>
여러 태그 결합
vocal-tract-length 태그와 Amazon Polly에서 지원하는 다른 SSML 태그를 결합할 수 있습니다. 음색(성도 길이)와 음의 고저는 서로 밀접하기 연결되기 때문에 vocal-tract-length 태그와 <prosody
pitch> 태그를 함께 사용하여 최적의 결과를 얻을 수 있습니다. 가장 사실적인 음성을 만들어 내기 위해 두 태그의 변경 백분율을 다르게 사용하는 것이 좋습니다. 원하는 결과를 얻기 위해 다양한 조합을 사용해 보세요.
다음 예제는 태그를 결합하는 방법을 보여줍니다.
<speak> The pitch and timbre of a person's voice are connected in human speech. <amazon:effect vocal-tract-length="-15%"> If you are going to reduce the vocal tract length, </amazon:effect><amazon:effect vocal-tract-length="-15%"> <prosody pitch="+20%"> you might consider increasing the pitch, too. </prosody></amazon:effect> <amazon:effect vocal-tract-length="+15%"> If you choose to lengthen the vocal tract, </amazon:effect> <amazon:effect vocal-tract-length="+15%"> <prosody pitch="-10%"> you might also want to lower the pitch. </prosody></amazon:effect> </speak>
속삭임 기능
<amazon:effect name="whispered">
현재 TTS 형식만 이 태그를 지원합니다.
이 태그는 입력 텍스트를 일반 스피치보다 속삭이는 음성으로 말해야 함을 나타냅니다. 이 태그는 Amazon Polly Text-to-Speech 포트폴리오에 있는 모든 음성과 함께 사용할 수 있습니다.
이 방식은 다음 구문을 사용합니다.
<amazon:effect name="whispered">text</amazon:effect>예:
<speak> <amazon:effect name="whispered">If you make any noise, </amazon:effect> she said, <amazon:effect name="whispered">they will hear us.</amazon:effect> </speak>
이 경우 캐릭터가 말하는 합성된 스피치는 속삭이는 음성이 되고, "she said" 구는 선택한 Amazon Polly 음성의 합성된 일반 스피치로 읽혀집니다.
원하는 효과에 따라 운율 속도를 최대 10%까지 느리게 하여 "속삭임" 효과를 향상시킬 수 있습니다.
예:
<speak> When any voice is made to whisper, <amazon:effect name="whispered"> <prosody rate="-10%">the sound is slower and quieter than normal speech </prosody></amazon:effect> </speak>
속삭이는 음성에 대한 스피치 마크를 생성하는 경우 오디오 스트림은 속삭이는 음성도 포함하여 스피치 마크가 오디오 스트림과 일치하도록 해야 합니다.
