기계 번역으로 제공되는 번역입니다. 제공된 번역과 원본 영어의 내용이 상충하는 경우에는 영어 버전이 우선합니다.
읽기 성능 최적화
이 섹션에서는 엔진과 관계없이 읽기 성능을 최적화하기 위해 조정할 수 있는 테이블 속성에 대해 설명합니다.
분할
Hive 테이블과 마찬가지로 Iceberg는 불필요한 메타데이터 파일 및 데이터 파일을 읽지 않도록 파티션을 인덱싱의 기본 계층으로 사용합니다. 열 통계는 쿼리 계획을 더욱 개선하기 위한 인덱싱의 보조 계층으로도 고려되어 전체 실행 시간을 단축합니다.
데이터 파티셔닝
Iceberg 테이블을 쿼리할 때 스캔되는 데이터의 양을 줄이려면 예상 읽기 패턴에 맞는 균형 잡힌 파티션 전략을 선택하세요.
-
쿼리에 자주 사용되는 열을 식별하세요. 이러한 파티셔닝 후보들은 이상적인 파티셔닝 후보입니다. 예를 들어, 일반적으로 특정 날짜의 데이터를 쿼리하는 경우 파티션 열의 자연스러운 예로 날짜 열을 들 수 있습니다.
-
파티션이 너무 많이 생성되지 않도록 하려면 카디널리티가 낮은 파티션 열을 선택하십시오. 파티션이 너무 많으면 테이블의 파일 수가 증가하여 쿼리 성능에 부정적인 영향을 미칠 수 있습니다. 일반적으로 “너무 많은 파티션”은 대부분의 파티션에 있는 데이터 크기가 에서 설정한 값의 2-5배 미만인 시나리오로 정의할 수 있습니다.
target-file-size-bytes
참고
일반적으로 카디널리티가 높은 열 (예: 수천 개의 값을 포함할 수 있는 id 열) 에서 필터를 사용하여 쿼리하는 경우 다음 섹션에서 설명하는 대로 Iceberg의 숨겨진 파티션 기능을 버킷 변환과 함께 사용하십시오.
숨겨진 파티셔닝 사용하기
쿼리가 일반적으로 테이블 열의 파생 객체를 기준으로 필터링되는 경우 파티션으로 사용할 새 열을 명시적으로 생성하는 대신 숨겨진 파티션을 사용하세요. 이 기능에 대한 자세한 내용은 Iceberg 설명서를 참조하십시오.
예를 들어 타임스탬프 열이 있는 데이터세트 (예:2023-01-01 09:00:00) 에서 파싱된 날짜로 새 열을 만드는 대신 (예:2023-01-01) 파티션 변환을 사용하여 타임스탬프에서 날짜 부분을 추출하고 이러한 파티션을 즉시 생성할 수 있습니다.
숨겨진 파티셔닝의 가장 일반적인 사용 사례는 다음과 같습니다.
-
데이터에 타임스탬프 열이 있는 날짜 또는 시간을 기준으로 파티셔닝합니다. Iceberg는 타임스탬프의 날짜 또는 시간 부분을 추출하기 위한 여러 변환을 제공합니다.
-
열의 해시 함수로 파티셔닝하는 경우, 파티셔닝 열의 카디널리티가 높아 파티션 수가 너무 많아질 수 있습니다. Iceberg의 버킷 변환은 파티션 열에 해시 함수를 사용하여 여러 파티션 값을 더 적은 수의 숨겨진 (버킷) 파티션으로 그룹화합니다.
사용 가능한 모든 파티션 변환에
숨겨진 파티셔닝에 사용되는 열은 및 같은 일반 SQL 함수를 사용하여 쿼리 조건자의 일부가 될 수 있습니다. year() month() 조건자를 및 와 같은 연산자와 조합할 수도 있습니다. BETWEEN AND
참고
Iceberg는 다른 데이터 유형을 생성하는 함수 (예:) 에 대해서는 파티션 프루닝을 수행할 수 없습니다. substring(event_time, 1, 10) =
'2022-01-01'
파티션 진화 사용
기존 파티션 전략이 최적이 아닐 때는 Iceberg의 파티션 진화를
처음에는 테이블에 가장 적합한 파티션 전략이 확실하지 않고 더 많은 통찰력을 얻으면서 파티션 전략을 구체화하고 싶을 때 이 방법을 사용할 수 있습니다. 파티션 진화의 또 다른 효과적인 용도는 데이터 볼륨이 변하고 시간이 지남에 따라 현재의 파티션 전략의 효과가 떨어지는 경우입니다.
파티션을 발전시키는 방법에 대한 지침은 Iceberg 설명서의 ALTER TABLE SQL 확장을
파일 크기 조정
쿼리 성능을 최적화하려면 테이블에 있는 작은 파일 수를 최소화해야 합니다. 쿼리 성능을 높이려면 일반적으로 Parquet 및 ORC 파일을 100MB 이상으로 유지하는 것이 좋습니다.
파일 크기는 Iceberg 테이블의 쿼리 계획에도 영향을 줍니다. 테이블의 파일 수가 늘어날수록 메타데이터 파일의 크기도 커집니다. 메타데이터 파일이 크면 쿼리 계획 속도가 느려질 수 있습니다. 따라서 테이블 크기가 커지면 파일 크기를 늘려 메타데이터가 기하급수적으로 확장되는 것을 방지하십시오.
다음 모범 사례를 사용하여 Iceberg 테이블에서 적절한 크기의 파일을 생성하십시오.
대상 파일 및 행 그룹 크기를 설정합니다.
Iceberg는 데이터 파일 레이아웃 조정을 위한 다음과 같은 주요 구성 매개변수를 제공합니다. 이 파라미터를 사용하여 대상 파일 크기와 행 그룹 또는 스트라이크 크기를 설정하는 것이 좋습니다.
파라미터 |
기본값 |
Comment |
|---|---|---|
|
512MB |
이 매개변수는 Iceberg가 생성할 최대 파일 크기를 지정합니다. 하지만 특정 파일은 이 제한보다 작은 크기로 기록될 수 있습니다. |
|
128MB |
Parquet과 ORC 모두 데이터를 청크 단위로 저장하므로 일부 작업에서는 엔진이 전체 파일을 읽지 않아도 됩니다. |
|
64메가바이트 |
|
|
없음, 아이스버그 버전 1.1 이하인 경우 해시, 아이스버그 버전 1.2부터 시작 |
Iceberg는 Spark에 스토리지에 쓰기 전에 작업 간에 데이터를 정렬하도록 요청합니다. |
-
예상 테이블 크기에 따라 다음 일반 가이드라인을 따르세요.
-
소형 테이블 (최대 몇 기가바이트) - 대상 파일 크기를 128MB로 줄이십시오. 또한 행 그룹 또는 스트라이프 크기를 줄이십시오 (예: 8MB 또는 16MB).
-
중대형 테이블 (몇 기가바이트에서 수백 기가바이트까지) — 이러한 테이블은 기본값을 사용하는 것이 좋습니다. 매우 선별적인 쿼리인 경우 행 그룹 또는 스트라이프 크기를 조정하십시오 (예: 16MB).
-
매우 큰 테이블 (수백 기가바이트 또는 테라바이트) - 대상 파일 크기를 1024MB 이상으로 늘리고 쿼리에서 일반적으로 많은 양의 데이터를 가져오는 경우 행 그룹이나 스트라이프 크기를 늘리는 것이 좋습니다.
-
-
Iceberg 테이블에 쓰는 Spark 애플리케이션이 적절한 크기의 파일을 생성하도록 하려면 속성을 또는 로 설정하십시오.
write.distribution-modehashrange이러한 모드 간의 차이점에 대한 자세한 설명은 Iceberg 설명서의 분산 모드 작성을참조하십시오.
다음은 일반적인 지침입니다. 테스트를 실행하여 특정 테이블 및 워크로드에 가장 적합한 값을 식별하는 것이 좋습니다.
정기적으로 압축을 실행하세요.
위 표의 구성은 쓰기 작업에서 생성할 수 있는 최대 파일 크기를 설정하지만 파일이 해당 크기를 가질 것이라고 보장하지는 않습니다. 파일 크기가 적절한지 확인하려면 정기적으로 압축을 실행하여 작은 파일을 큰 파일로 합치십시오. 압축 실행에 대한 자세한 지침은 이 가이드 뒷부분에 있는 Iceberg 압축을 참조하십시오.
컬럼 통계 최적화
Iceberg는 열 통계를 사용하여 파일 프루닝을 수행하는데, 이는 쿼리로 스캔되는 데이터의 양을 줄임으로써 쿼리 성능을 향상시킵니다. 열 통계를 활용하려면 Iceberg가 쿼리 필터에서 자주 사용되는 모든 열에 대한 통계를 수집하도록 하세요.
기본적으로 Iceberg는 테이블 속성에 정의된 대로 각 테이블의 처음 100개 열에write.metadata.metrics.max-inferred-column-defaults 테이블에 100개가 넘는 열이 있고 쿼리가 처음 100개 열을 제외한 열을 자주 참조하는 경우 (예: 132열을 필터링하는 쿼리가 있을 수 있음) Iceberg가 해당 열에 대한 통계를 수집하는지 확인하세요. 이를 위한 두 가지 옵션이 있습니다.
-
Iceberg 테이블을 생성할 때는 쿼리에 필요한 열이 에서 설정한 열 범위
write.metadata.metrics.max-inferred-column-defaults(기본값 100) 에 속하도록 열을 재정렬하십시오.참고: 100개 열에 대한 통계가 필요하지 않은 경우
write.metadata.metrics.max-inferred-column-defaults구성을 원하는 값 (예: 20) 으로 조정하고 쿼리를 읽고 쓰는 데 필요한 열이 데이터세트 왼쪽의 처음 20개 열에 포함되도록 열을 재정렬할 수 있습니다. -
쿼리 필터에 몇 개의 열만 사용하는 경우 다음 예와 같이 지표 수집을 위한 전체 속성을 비활성화하고 통계를 수집할 개별 열을 선택적으로 선택할 수 있습니다.
.tableProperty("write.metadata.metrics.default", "none") .tableProperty("write.metadata.metrics.column.my_col_a", "full") .tableProperty("write.metadata.metrics.column.my_col_b", "full")
참고: 열 통계는 해당 열을 기준으로 데이터를 정렬할 때 가장 효과적입니다. 자세한 내용은 이 가이드 뒷부분에 있는 정렬 순서 설정 섹션을 참조하십시오.
적절한 업데이트 전략을 선택하세요.
사용 사례에 따라 느린 쓰기 작업이 허용되는 경우 copy-on-write 전략을 사용하여 읽기 성능을 최적화하십시오. 이는 Iceberg에서 사용하는 기본 전략입니다.
C는 opy-on-write 파일을 읽기 최적화된 방식으로 스토리지에 직접 쓰기 때문에 읽기 성능이 향상됩니다. 그러나 에 비해 각 쓰기 작업은 시간이 더 오래 걸리고 더 많은 컴퓨팅 리소스를 소비합니다. merge-on-read 따라서 일반적으로 읽기 지연 시간과 쓰기 지연 시간 간의 균형을 맞출 수 있습니다. 일반적으로 대부분의 업데이트가 동일한 테이블 파티션에 배치되는 사용 사례 (예: 일일 배치 로드) 에 적합합니다. copy-on-write
C opy-on-write 구성 (write.update.mode,write.delete.mode, 및write.merge.mode) 은 테이블 수준에서 설정하거나 애플리케이션 측에서 독립적으로 설정할 수 있습니다.
ZSTD 압축 사용
table 속성을 사용하여 Iceberg에서 사용하는 압축 코덱을 수정할 수 있습니다. write.<file_type>.compression-codec 테이블의 전반적인 성능을 향상시키려면 ZSTD 압축 코덱을 사용하는 것이 좋습니다.
기본적으로 Iceberg 버전 1.3 및 이전 버전에서는 ZSTD에 비해 읽기/쓰기 성능이 느린 GZIP 압축을 사용합니다.
참고: 일부 엔진은 다른 기본값을 사용할 수 있습니다. Athena 또는 Amazon EMR 버전 7.x로 만든 아이스버그 테이블의 경우가 이에 해당합니다.
정렬 순서를 설정합니다.
Iceberg 테이블의 읽기 성능을 개선하려면 쿼리 필터에서 자주 사용되는 하나 이상의 열을 기준으로 테이블을 정렬하는 것이 좋습니다. 정렬을 Iceberg의 열 통계와 결합하면 파일 프루닝의 효율성이 크게 향상되어 읽기 작업 속도가 빨라질 수 있습니다. 또한 정렬은 쿼리 필터의 정렬 열을 사용하는 쿼리에 대한 Amazon S3 요청 수를 줄입니다.
Spark로 데이터 정의 언어 (DDL) 문을 실행하여 테이블 수준에서 계층적 정렬 순서를 설정할 수 있습니다. 사용 가능한 옵션은 Iceberg 설명서를 참조하십시오.
예를 들어, 대부분의 쿼리가 필터링 기준인 날짜 (yyyy-mm-dd) 로 분할된 테이블에서 DDL 옵션을 사용하여 Spark가 범위가 겹치지 않는 파일을 Write Distributed By Partition Locally Ordered 쓰도록 할 수 있습니다. uuid
다음 다이어그램은 테이블을 정렬할 때 열 통계의 효율성이 어떻게 향상되는지를 보여줍니다. 이 예제에서 정렬된 테이블은 단일 파일만 열면 되므로 Iceberg의 파티션과 파일을 최대한 활용할 수 있습니다. 정렬되지 않은 테이블에서는 임의의 데이터 파일에 임의의 데이터가 uuid 존재할 수 있으므로 쿼리는 모든 데이터 파일을 열어야 합니다.

정렬 순서를 변경해도 기존 데이터 파일에는 영향을 주지 않습니다. Iceberg 압축을 사용하여 해당 항목에 정렬 순서를 적용할 수 있습니다.
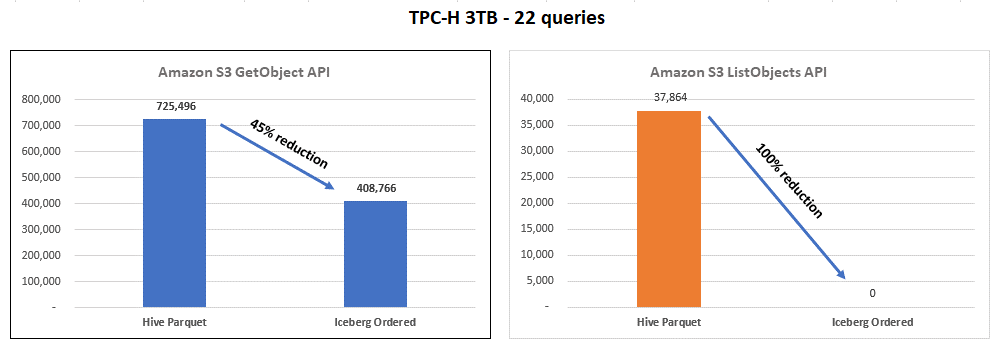
다음 그래프에서 볼 수 있듯이 Iceberg 정렬 테이블을 사용하면 워크로드 비용을 줄일 수 있습니다.
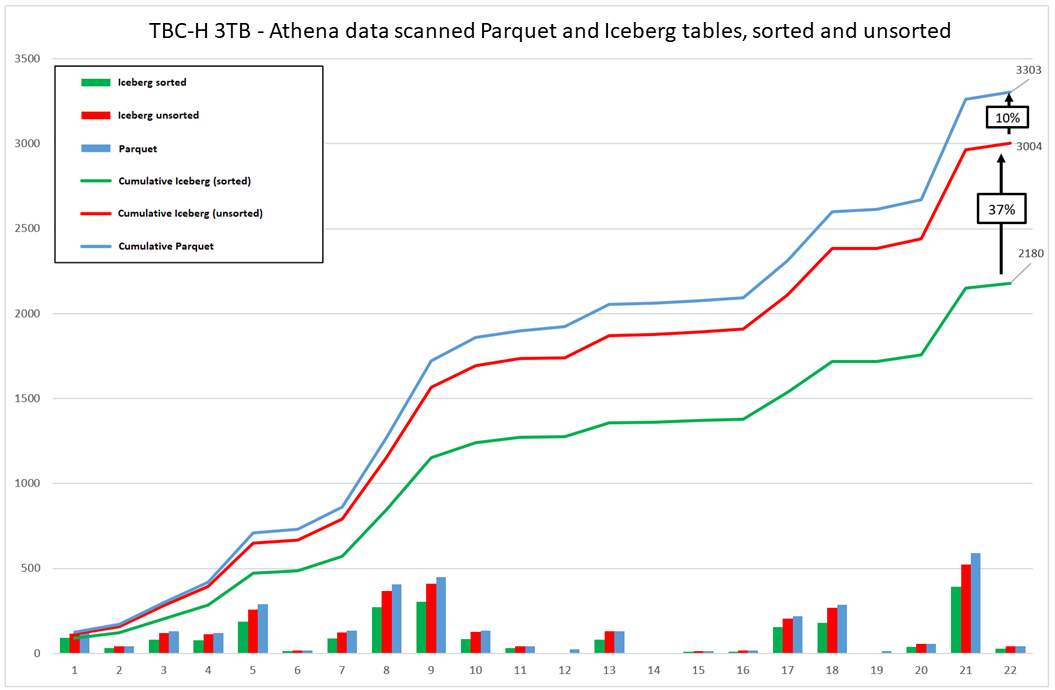
이 그래프는 Hive (Parquet) 테이블에 대한 TPC-H 벤치마크를 실행한 결과를 Iceberg의 정렬 테이블과 비교하여 요약합니다. 하지만 다른 데이터셋이나 워크로드에서는 결과가 다를 수 있습니다.