기계 번역으로 제공되는 번역입니다. 제공된 번역과 원본 영어의 내용이 상충하는 경우에는 영어 버전이 우선합니다.
중앙 집중식 카탈로그
다음 다이어그램은 중앙 집중식 카탈로그가 데이터 레이크의 데이터 생산자와 데이터 소비자를 연결하는 방법을 보여줍니다.
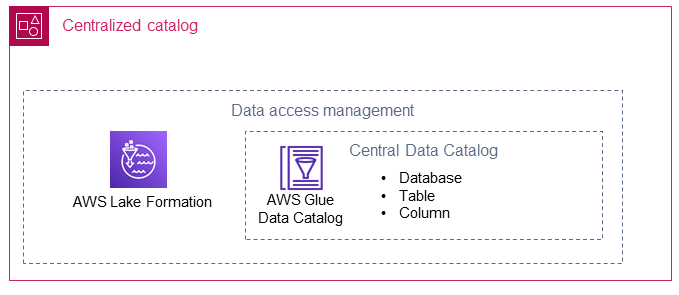
중앙 집중식 카탈로그는 데이터 생산자 계정의 공유 데이터 카탈로그를 저장하고 관리합니다. 또한 중앙 집중식 카탈로그는 공유 데이터의 기술 메타데이터(예: 테이블 이름 및 스키마)를 호스팅하며 데이터 소비자가 데이터에 액세스하기 위해 오는 위치입니다.
데이터 소비자는 중앙 집중식 카탈로그의 여러 데이터 생산자의 데이터에 액세스한 다음 추가 처리를 위해이 데이터를 자체 데이터와 혼합할 수 있습니다. 중앙 집중식 카탈로그를 사용하면 데이터 소비자가 다른 데이터 생산자와 직접 연결할 필요가 없으며 운영 오버헤드가 줄어듭니다.
중앙 집중식 카탈로그는 데이터 생산자와 소비자의 데이터 공유 및 데이터 소비를 파악할 수 있으므로 중앙 집중식 데이터 거버넌스 함수(예: 액세스 감사)를 적용하기에 이상적인 위치일 수 있습니다.
다음 섹션에서는 중앙 집중식 카탈로그가 AWS Lake Formation 및를 사용하는 방법을 설명합니다 AWS Glue.
AWS Lake Formation
AWS Lake Formation는 AWS Glue 데이터 카탈로그에서 데이터 레이크에 있는 여러 데이터 생산자의 위치를 가리키는 데이터베이스를 생성하는 데 도움이 됩니다. 중앙 집중식 카탈로그에서 Lake Formation에 대한 AWS Identity and Access Management (IAM) 역할이 생성됩니다. 중앙 집중식 카탈로그는 Lake Formation을 사용하여 데이터 리소스(예: 데이터베이스, 테이블 또는 열)를 데이터 소비자와 선택적으로 공유할 수 있습니다. Lake Formation 관리형 리소스는 다음 두 가지 방법 중 하나를 사용하여 데이터 소비자와 공유됩니다.
-
명명된 리소스 메서드 -이 메서드는 계정 간에 관리형 리소스를 공유합니다. 데이터베이스, 테이블 또는 열 이름을 지정해야 하며 리소스를 조직, 조직 단위(OU) 또는와 공유할 수 있습니다 AWS 계정. 공유 및 관리 오버헤드를 줄이려면 가능하면 더 높은 수준에서 리소스를 공유하는 것이 좋습니다(예: 대신 조직 또는 OU에서 AWS 계정). 그러나이 접근 방식이 조직의 데이터 보안 제어 요구 사항을 충족하는지 확인해야 합니다.
-
참고:이 방법은 AWS 서비스가 데이터 생산자의 데이터를 사용하는 애플리케이션 유형의 데이터 소비자에게 적합합니다. 이러한 유형의 데이터 소비자의 데이터 액세스 요구 사항은 애플리케이션 기반이고 규범적이며 비교적 정적입니다.
-
-
Lake Formation 태그 기반 액세스 제어(LF-TBAC) 방법 - LF-TBAC는 데이터 서비스 유형의 데이터 소비자에게 특히 유용합니다. 그러나 Lake Formation 태그가 지정된 리소스는 현재 조직 또는 OU AWS 계정 수준이 아닌 수준에서만 공유할 수 있습니다.
AWS Glue
중앙 집중식 카탈로그의 각 데이터 생산자에 AWS Glue 대해에서 데이터베이스를 생성해야 합니다. 중앙 집중식 카탈로그는 AWS Glue 를 사용하여 모든 데이터 생산자의 데이터베이스를 호스팅하므로 데이터베이스 이름이 모든 데이터 생산자에서 고유하고 데이터 생산자와 해당 데이터 유형을 반영하는지 확인해야 합니다. 예를 들어 다음 데이터베이스 이름 지정 구조를 사용할 수 있습니다. <Data_Producer>–<Environment>–<Data_Group>
-
<Data_Producer>- 데이터 생산자의 이름입니다. -
<Environment>-dev개발 환경, 시스템 통합 테스트 환경 또는 프로덕션 환경sit과 같은 데이터 레이크 환경prod입니다. -
<Data_Group>- 데이터 생산자와 데이터를 논리적 그룹으로 구분하는 데 사용되는 데이터 그룹의 이름입니다. 소스 시스템 이름, ID 또는 약어를 이름으로 사용할 수 있습니다. 데이터베이스 설명은 데이터베이스의 내용과 목적을 설명하는 데도 도움이 됩니다.
데이터 생산자의 데이터에 AWS Glue 크롤러를 사용하여 중앙 집중식 카탈로그의 데이터베이스에 스키마를 유지할 수 있습니다. 데이터 생산자가 동일한 빈도로 데이터를 정기적으로 생성하는 경우 단일 AWS Glue 크롤러를 사용할 수 있습니다. 다른 모든 경우에는 여러 AWS Glue 크롤러를 사용하여 서로 다른 크롤링 빈도를 수용해야 합니다. 비즈니스 사용 사례에 따라 크롤러를 사전 정의된 빈도로 예약하거나 이벤트에 의해 시작할 수 있습니다.
AWS Glue API를 호출하여 스키마를 생성하거나 업데이트 AWS Glue 하여에서 테이블 스키마를 유지할 수도 있습니다. 이는 유연성을 제공할 수 있지만 코드 개발 및 유지 관리를 위해서는 추가 노력이 필요합니다. 사용 사례와 비즈니스 가치를 평가한 다음 요구 사항을 충족하고 오버헤드가 가장 적은 옵션을 선택해야 합니다.
