기계 번역으로 제공되는 번역입니다. 제공된 번역과 원본 영어의 내용이 상충하는 경우에는 영어 버전이 우선합니다.
일반적인 조정 문제
데이터 레이크는 초기 배포 후 데이터가 증가할 때 여러 단계를 거칩니다. 확장 가능한 아키텍처를 사용하여 데이터 레이크를 설계하지 않은 경우 조직에서 문제가 발생할 수 있으며 데이터 레이크의 성장으로 인해 불이익을 받을 수 있습니다.
다음 섹션에서는 일반적인 데이터 레이크의 성장으로 인해 규모 조정 문제가 어떻게 발생할 수 있는지 설명합니다.
초기 데이터 레이크 배포
다음 다이어그램은 사업부 A가 처음 배포한 후의 데이터 레이크의 아키텍처를 보여줍니다.
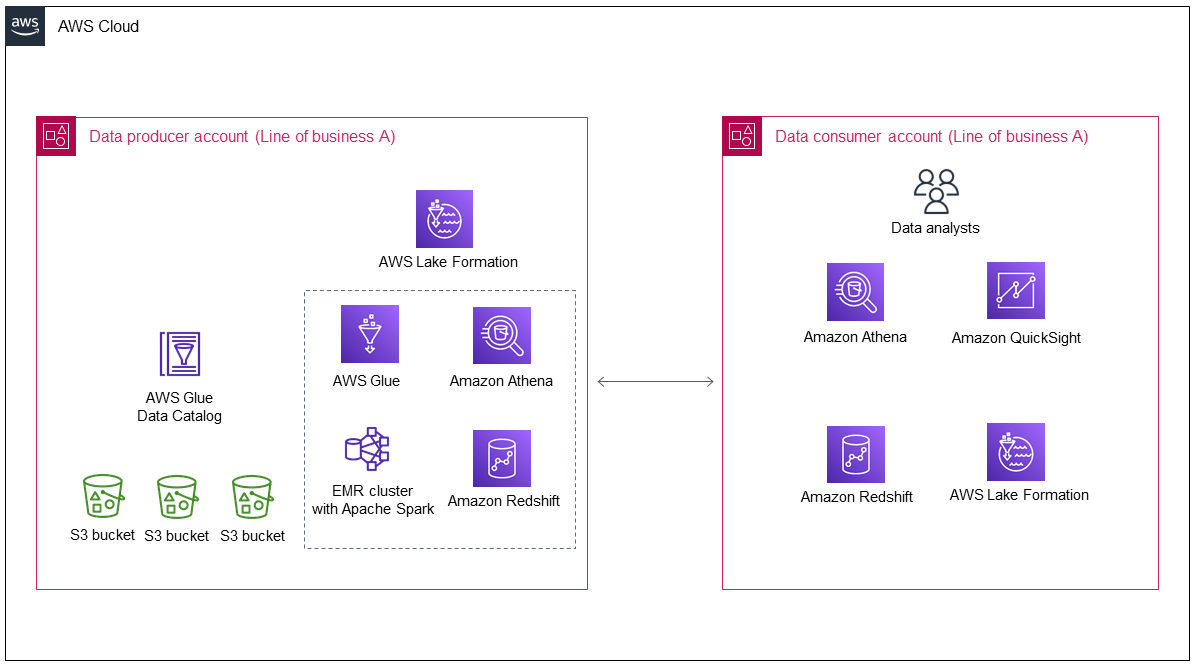
다이어그램은 다음 구성 요소를 보여줍니다.
-
데이터 생산자 계정은 데이터를 수집 및 처리하고, 처리된 데이터를 저장하고, 사용을 준비합니다.
-
데이터 생산자 계정의 데이터는 Amazon Simple Storage Service(Amazon S3) 버킷에 저장되며,이 버킷에는 여러 데이터 계층이 있을 수 있습니다.
-
데이터 처리에 AWS 서비스를 사용할 수 있습니다(예: AWS Glue 및 Amazon EMR).
-
데이터 생산자는 데이터 레이크에 데이터를 생성하고 저장할 뿐만 아니라 데이터 소비자와 공유할 데이터와 공유 방법을 결정해야 합니다.는 데이터 생산자 계정의 데이터 레이크를 AWS Lake Formation 관리하는 동시에 데이터 생산자에서 데이터 소비자로의 교차 계정 데이터 공유를 관리합니다.
-
데이터 소비자 계정은 특정 비즈니스 사용 사례에 대해 데이터 생산자 계정의 공유 데이터를 사용합니다.
데이터 소비자 증가
다음 다이어그램은 Line of Business A의 데이터가 증가할 때 더 많은 데이터가 데이터 레이크로 들어오는 것을 보여줍니다. 그런 다음 데이터 레이크는 더 많은 데이터 소비자를 유치하여 데이터를 활용하고 데이터에서 가치를 얻습니다.
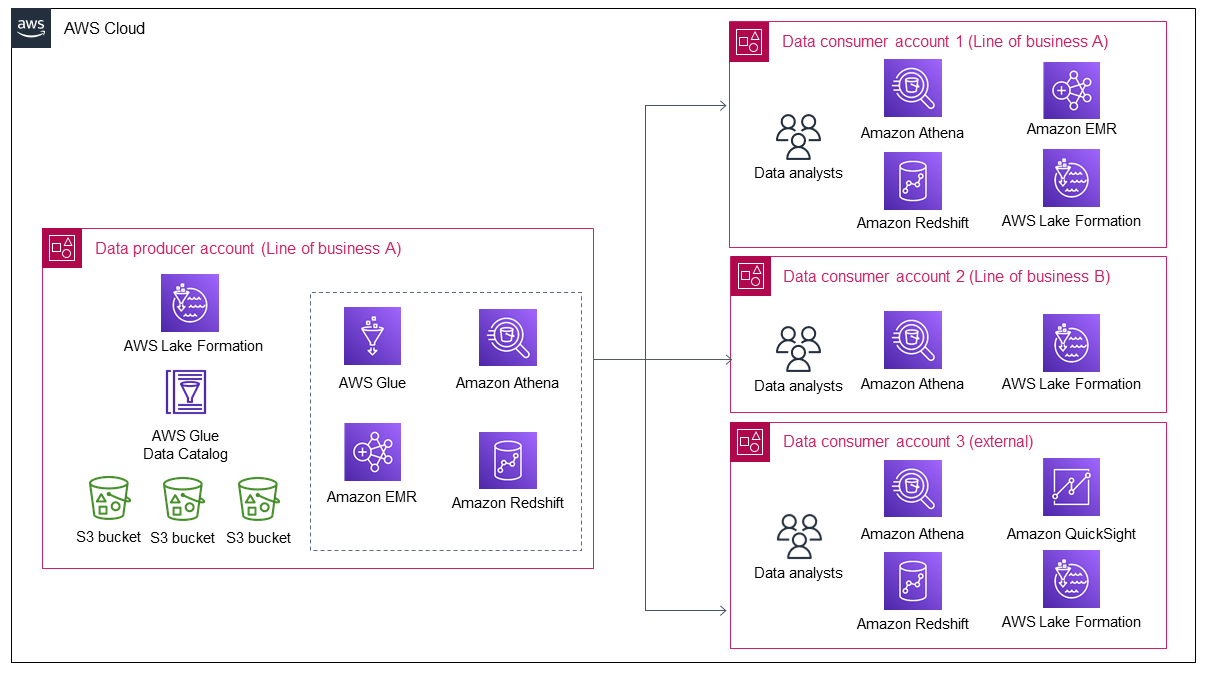
다이어그램은 조직이 기존 데이터 자산에서 거의 지속적인 가치를 생성하는 방법과 이로 인해 더 많은 데이터 소비자가 유치되는 방법을 보여줍니다. 그러나 데이터 소비자가 증가하면 데이터 생산자는 이러한 증가를 수용하기 위해 다음 두 가지 옵션만 사용할 수 있습니다.
-
개별 데이터 소비자의 데이터 공유 및 액세스를 수동으로 관리합니다. 이는 확장 가능한 접근 방식이 아닙니다.
-
데이터 공유 및 데이터 액세스 관리를 위한 자동 또는 반자동 프로세스를 개발합니다. 이는 확장 가능한 옵션일 수 있지만 내부 및 외부 데이터 소비자의 보안 제어 요구 사항이 다르기 때문에 설계 및 구축에 상당한 시간과 노력이 필요합니다. 향후 솔루션 개선에는 추가 시간과 노력도 필요합니다.
데이터 생산자 증가
다음 다이어그램은 여러 비즈니스 라인이 데이터 생산자로 조인할 때의 데이터 레이크 아키텍처를 보여줍니다.
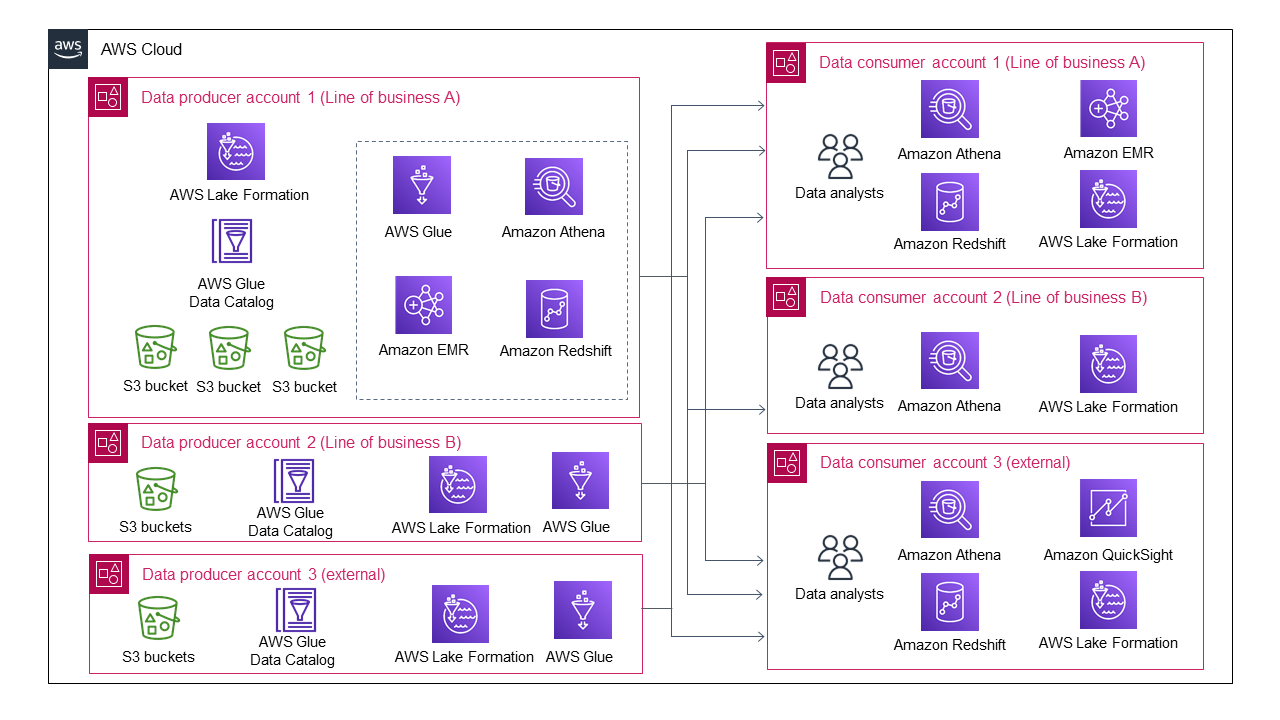
데이터 레이크의 아키텍처는 데이터 생산자 3명과 데이터 소비자 3명만으로도 점점 복잡해지고 있습니다.
각 데이터 생산자는 여러 데이터 소비자의 데이터 공유 및 데이터 액세스 관리를 처리해야 합니다. 모든 데이터 생산자가 데이터 공유 및 데이터 액세스 관리를 위한 자동 또는 반자동 프로세스를 개발할 것으로 예상하는 것은 비현실적입니다. 일부 데이터 생산자는 데이터를 공유하지 않도록 선택할 수 있으므로 저렴한 관리 오버헤드를 피할 수 있습니다. 마찬가지로 각 데이터 소비자는 여러 데이터 생산자와 상호 작용하여 서로 다른 데이터 소비 프로세스를 이해해야 합니다. 즉, 개별 데이터 소비자는 서로 다른 데이터 공유 패턴을 처리하기 위한 관리 오버헤드가 증가합니다.
많은 조직에서이 데이터 레이크는 병목 현상을 일으키며 성장하거나 확장할 수 없습니다. 이는 조직이 병목 현상을 제거하기 위해 데이터 레이크를 재설계하고 재구축해야 함을 의미할 수 있으며, 이로 인해 상당한 시간, 리소스 및 비용이 발생할 수 있습니다.
