기계 번역으로 제공되는 번역입니다. 제공된 번역과 원본 영어의 내용이 상충하는 경우에는 영어 버전이 우선합니다.
화물 수요 예측을 위한 기계 학습 모델
다음 이미지는 교육 데이터의 예를 보여줍니다. 예측하려는 대상이 목표값이고, 관련 시계열 1과 2는 목표값 예측과 관련된 입력 특성입니다. 과거 데이터는 훈련 및 검증에 사용되며 모델 검증을 위해 일정 기간 동안 과거 데이터를 보류합니다.
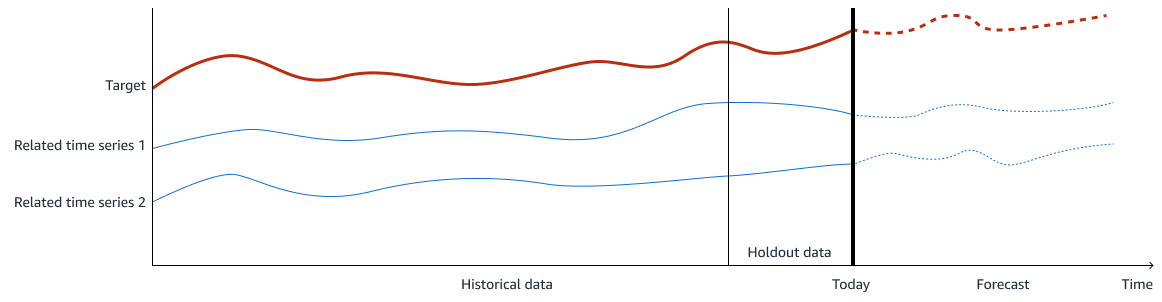
수요 예측에서 생산량 (또는 목표) 은 예측하려는 수요량입니다. 입력 특징은 출력과 관련된 시계열 데이터입니다. 수요량을 정확하게 예측하도록 ML 모델을 학습시키려면 솔루션에 두 가지 기계 학습 모델이 필요합니다. 첫 번째 모델은 내부 및 외부 데이터를 포함하여 입력 특징에 대한 시계열 예측을 만듭니다. 두 번째 모델은 모든 기능을 사용하여 최종 수요 예측을 수행합니다. 이 두 모델을 함께 사용하면 시계열 추세와 목표와 입력 간의 관계를 효과적으로 파악할 수 있습니다.
입력 기능 예측을 위한 ML 모델
입력 기능에는 내부 및 외부 과거 시계열 데이터가 모두 포함됩니다. 1차원 (1D) 시계열 모델을 사용하여 각 특징을 예측하면 됩니다. 다양한 알고리즘을 사용할 수 있습니다. 예를 들어, 계절적 영향이 강하고 여러 시즌의 과거 데이터가 있는 시계열에 가장 Prophet
대상 변수 예측의 ML 모델
산출물 또는 수요량에 대한 ML 모델은 모든 기능과 산출물 간의 관계를 파악하도록 구축되었습니다. ,, lassoridge regression, random forest 등 다양한 감독 회귀 모델을 사용할 수 있습니다. XGBoost 모델을 구축하고 최적의 매개변수와 하이퍼파라미터를 찾을 때 홀드아웃 데이터를 사용할 수 있습니다. 홀드아웃 데이터는 레이블이 지정된 과거 데이터 중 일부이며, 기계 학습 모델을 학습시키는 데 사용되는 데이터셋에는 포함되지 않습니다. 홀드아웃 데이터를 사용하여 예측과 홀드아웃 데이터를 비교하여 모델 성능을 평가할 수 있습니다.
