기계 번역으로 제공되는 번역입니다. 제공된 번역과 원본 영어의 내용이 상충하는 경우에는 영어 버전이 우선합니다.
로컬 해석력
복잡한 모델의 로컬 해석력에 대한 가장 많이 사용되는 방법은 Shapley Additive Explanations(SHAP) [8] 또는 적분 기울기 [11]에 근거합니다. 각 방법에는 모델 타입 고유한 다양한 변형이 있습니다.
트리 앙상블 모델의 경우, 트리 SHAP를 사용하십시오.
트리 기반 모델의 경우, 동적 프로그래밍을 통해 각 특성에 대한 Shapley 값을
신경망과 미분 가능한 모델의 경우, 적분 기울기와 컨덕턴스를 사용하십시오.
적분 기울기는 신경망의 특징 속성을 계산하는 간단한 방법을 제공합니다. 컨덕턴스는 적분 기울기를 기반으로 하므로 계층 및 개별 뉴런과 같은 신경망 일부의 속성을 해석하는 데 도움이 됩니다. ([3,11] 참조, 구현은 https://captum.ai/
다른 모든 경우에는 Kernel SHAP를 사용하십시오.
커널 SHAP를 사용하여 모든 모델의 특징 속성을 계산할 수 있지만, 이는 전체 Shapley 값을 계산하는 것과 비슷하며 계산 비용이 많이 듭니다([8] 참조). 커널 SHAP에 필요한 계산 리소스는 기능이 많아질수록 빠르게 증가합니다. 이를 위해서는 설명의 충실도, 반복성 및 견고성을 줄일 수 있는 근사치 방법이 필요합니다. Amazon SageMaker Clarify는 별도의 인스턴스에서 커널 SHAP 값을 계산하기 위해 사전 빌드된 컨테이너를 배포하는 편리한 방법을 제공합니다. (예를 보려면 SageMaker Clarify 기능을 사용한 GitHub 리포지토리의 공정성 및 설명 가능성
단일 트리 모델의 경우, 분할 변수와 리프 값은 즉시 설명 가능한 모델을 제공하지만 앞에서 설명한 방법으로는 추가적인 통찰력을 얻을 수 없습니다. 마찬가지로 선형 모델의 경우, 계수를 통해 모델 동작에 대한 명확한 설명이 제공됩니다. (SHAP 방법과 적분 기울기 방법 모두 계수에 의해 결정되는 기여도를 반환합니다.)
SHAP 및 적분 기울기 기반 방법 모두 약점이 있습니다. SHAP에서는 모든 특징 조합의 가중 평균을 바탕으로 기여도를 도출해야 합니다. 이러한 방식으로 얻은 속성은 특성 간에 강한 상호 작용이 있는 경우, 특성 중요도를 추정할 때 오해의 소지가 있을 수 있습니다. 적분 기울기에 근거한 방법은 대규모 신경망에 존재하는 차원 수가 많기 때문에 해석하기 어려울 수 있으며, 이러한 방법은 기준점 선택에 민감합니다. 일반적으로 모델은 특정 수준의 성능을 달성하기 위해 추정치 못한 방식으로 특성을 사용할 수 있으며, 이는 모델에 따라 달라질 수 있습니다. 특성 중요도는 항상 모델에 따라 다릅니다.
권장되는 가시화
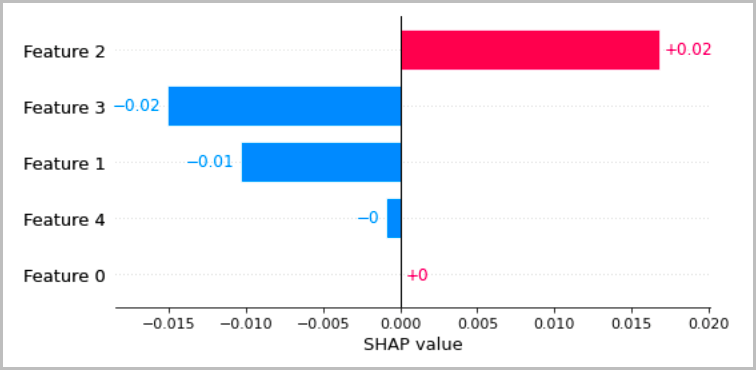
다음 차트는 이전 섹션에서 설명한 로컬 해석을 가시화하는 몇 가지 권장 방법을 보여줍니다. 표 형식 데이터의 경우, 속성을 보여주는 간단한 막대 그래프를 사용하는 것이 좋습니다. 그러면 속성을 쉽게 비교하고 이를 사용하여 모델의 예측 방식을 추론할 수 있습니다.
텍스트 데이터의 경우, 토큰을 내장하면 많은 수의 스칼라 입력이 생성됩니다. 이전 섹션에서 권장한 방법은 임베딩의 각 차원과 각 출력값에 대한 속성을 생성합니다. 이 정보를 가시화하기 위해 주어진 토큰의 속성을 합산할 수 있습니다. 다음 예는 SQUAD 데이터 세트에서 훈련된 BERT 기반 질문 답변 모델의 속성 합계를 보여줍니다. 이 경우, 예측 레이블과 실제 레이블은 “france”라는 단어의 토큰입니다.

그렇지 않으면 다음 예와 같이 토큰 속성의 벡터 기준을 전체 속성 값으로 할당할 수 있습니다.

딥러닝 모델에서 중간 계층의 경우, 다음 예와 같이 가시화를 위한 컨덕턴스에 유사한 집계를 적용할 수 있습니다. 트랜스포머 레이어에 대한 토큰 컨덕턴스의 벡터 기준은 최종 토큰 예측(“프랑스”)의 최종 활성화를 보여줍니다.

개념 활성화 벡터는 심층 신경망을 더 자세히 연구할 수 있는 방법을 제공합니다 [6]. 이 방법은 이미 훈련된 네트워크의 계층에서 특성을 추출하고 이러한 특성에 대해 선형 분류기를 훈련시켜 계층의 정보를 추론합니다. 예컨대, BERT 기반 언어 모델에서 품사에 대한 정보가 가장 많이 포함된 계층을 확인하고 싶을 수 있습니다. 이 경우, 각 계층 출력값에 대해 선형 품사 모델을 훈련시키고 가장 성능이 좋은 분류기가 품사 정보가 가장 많은 계층과 연관되어 있다고 대략적으로 추정할 수 있습니다. 이 방법은 신경망을 해석하는 기본 방법으로 권장하지는 않지만, 좀 더 자세히 연구할 수 있고 네트워크 아키텍처 설계에 도움이 될 수 있습니다.
