기계 번역으로 제공되는 번역입니다. 제공된 번역과 원본 영어의 내용이 상충하는 경우에는 영어 버전이 우선합니다.
문서 적용 범위 및 정확도 - 도메인 내부
다음 그래프에서 볼 수 있는 바와 같이 딥 앙상블의 예측 성능을 테스트 시 적용한 드롭아웃, MC 드롭아웃 및 나이브 소프트맥스 함수를 사용하여 비교했습니다. 추론 후 불확실성이 가장 높은 예측을 여러 수준에서 제거하여 남은 데이터의 적용 범위는 10% 에서 100% 사이였습니다. 딥 앙상블이 인식적 불확실성을 정량화하는 능력, 즉 데이터에서 모델의 경험이 적은 영역을 식별하는 능력이 향상되어 불확실한 예측을 더 효율적으로 식별할 수 있을 것으로 기대했습니다. 이는 다양한 데이터 커버리지 수준에서 더 높은 정확도로 반영되어야 합니다. 각각의 딥 앙상블에 대해 5개 모델을 사용하고 추론을 20회 적용했습니다. MC 드롭아웃의 경우 각 모델에 대해 추론을 100회 적용했습니다. 각 방법에 동일한 하이퍼파라미터 세트와 모델 아키텍처를 사용했습니다.
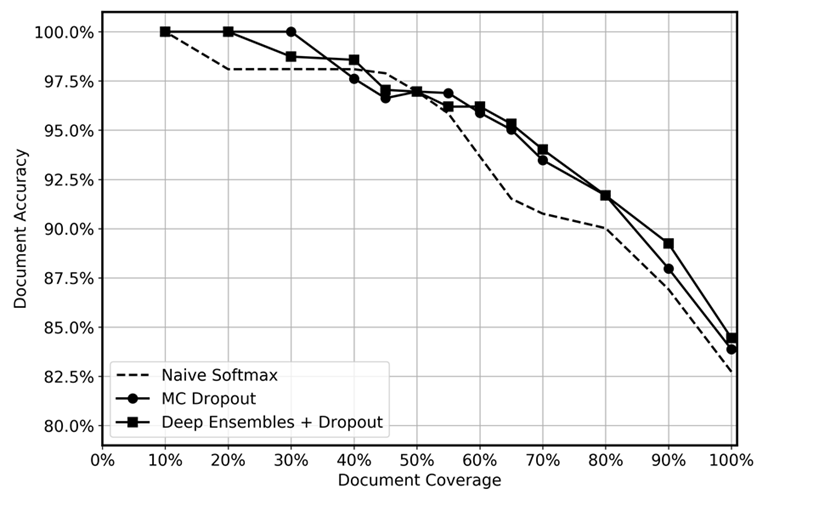
이 그래프는 딥 앙상블과 MC 드롭아웃을 사용하면 나이브 소프트맥스에 비해 약간의 이점이 있는 것으로 보입니다. 이는 50~80%의 데이터 커버리지 범위에서 가장 두드러집니다. 이 수치가 더 크지 않은 이유는 무엇입니까? 딥 앙상블 섹션에서 언급했듯이 딥 앙상블의 강점은 다양한 손실 궤적에서 비롯됩니다. 이 상황에서는 사전 훈련된 모델을 사용하고 있습니다. 전체 모델을 미세 조정하긴 하지만 거의 대부분의 가중치는 사전 훈련된 모델에서 초기화되고 일부 숨겨진 레이어만 무작위로 초기화됩니다. 따라서 대규모 모델을 사전 훈련하면 다양화가 거의 이루어지지 않아 과도하게 신뢰하게 되는 일이 발생할 수 있다고 추측합니다. 우리가 아는 한, 딥 앙상블의 효능은 이전에 전이 학습 시나리오에서 테스트된 적이 없으며 앞으로의 연구에 흥미로운 영역이 될 것으로 보고 있습니다.
