기계 번역으로 제공되는 번역입니다. 제공된 번역과 원본 영어의 내용이 상충하는 경우에는 영어 버전이 우선합니다.
온도 스케일링
분류 문제에서는 예측 확률(소프트맥스 출력)이 예측 클래스의 실제 정확성 확률을 나타내는 것으로 가정합니다. 그러나 10년 전 모델에서는 이 가정이 합리적이었을지 모르지만 오늘날의 현대 신경망 모델에서는 그렇지 않습니다(Guo 외 2017). 모델 예측 확률과 모델 예측의 신뢰도 사이의 연관성이 상실되면 의사 결정 시스템에서처럼 최신 신경망 모델을 실제 문제에 적용할 수 없게 됩니다. 모델 예측의 신뢰도 점수를 정확하게 파악하는 것은 강력하고 신뢰할 수 있는 기계 학습 애플리케이션을 구축하는 데 필요한 가장 중요한 위험 제어 설정 중 하나입니다.
최신 신경망 모델은 수백만 개의 학습 파라미터가 포함된 대규모 아키텍처를 사용하는 경향이 있습니다. 이러한 모델의 예측 확률 분포는 종종 1이나 0으로 크게 치우쳐 있습니다. 즉, 모델이 지나치게 신뢰되면 이러한 확률의 절대값이 무의미할 수 있습니다. (이 문제는 데이터 세트에 클래스 불균형이 존재하는지 여부와 무관합니다.) 지난 10년 동안 모델의 순진한 확률을 재보정하는 사후 처리 단계를 통해 예측 신뢰도 점수를 생성하는 다양한 보정 방법이 개발되었습니다. 이 섹션에서는 예측 확률을 재보정하는 간단하면서도 효과적인 기법인 온도 스케일링이라는 한 가지 교정 방법을 설명합니다 (Guo 외 2017). 온도 스케일링은 플랫 로지스틱 스케일링의 단일 파라미터 버전입니다 (Platt 1999).
온도 스케일링은 다음 그림과 같이 단일 스칼라 파라미터 T > 0(여기서 T는 온도)을 사용하여 소프트맥스 함수를 적용하기 전에 로짓 점수를 재조정합니다. 모든 클래스에 동일한 T가 사용되므로 스케일링을 적용한 소프트맥스 출력값은 스케일링되지 않은 출력과 단조 관계를 갖습니다. T = 1인 경우 기본 소프트맥스 함수를 사용하여 원래 확률을 복구합니다. T > 1인 과신 모형에서는 재보정된 확률 값이 원래 확률보다 낮고 0과 1 사이에 더 균등하게 분포됩니다.
교육된 모델의 최적 온도 T를 구하는 방법은 홀드아웃 검증 데이터 세트의 음수 로그 발생 가능성을 최소화하는 것입니다.
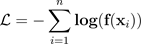
모델 학습 프로세스의 일부로 온도 스케일링 방법을 통합하는 것이 좋습니다. 모델 학습이 완료되면 검증 데이터 세트을 사용하여 온도 값 T를 추출한 다음 소프트맥스 함수의 T를 사용하여 로짓 값을 재조정합니다. BERT 기반 모델을 사용하여 텍스트 분류 작업을 수행한 실험에 따르면 온도 T는 보통 1.5에서 3 사이로 조절됩니다.
다음 그림은 로짓 점수를 소프트맥스 함수에 전달하기 전에 온도 값 T를 적용하는 온도 스케일링 방법을 보여줍니다.
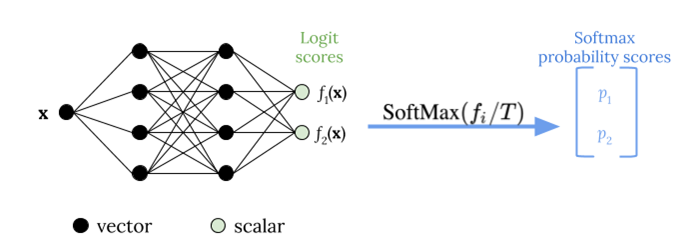
온도 스케일링으로 보정된 확률은 모델 예측의 신뢰도 점수를 대략적으로 나타낼 수 있습니다. 이는 예상 정확도 분포와 예측 확률 분포 간의 정렬을 나타내는 신뢰도 다이어그램(Guo 외 2017)을 작성하여 정량적으로 평가할 수 있습니다.
온도 스케일링은 보정된 확률의 총 예측 불확실성을 정량화하는 효과적인 방법으로도 평가되어 왔지만 데이터 드리프트와 같은 시나리오에서 인식적 불확실성을 파악하는 데는 그다지 효과적이지 않습니다(Ovadia 외 2019). 구현의 용이성을 고려하여 딥 러닝 모델 출력에 온도 스케일링을 적용하여 예측 불확실성을 정량화하는 강력한 솔루션을 구축하는 것이 좋습니다.
