기계 번역으로 제공되는 번역입니다. 제공된 번역과 원본 영어의 내용이 상충하는 경우에는 영어 버전이 우선합니다.
데이터 준비 및 정리
데이터 준비 및 정리는 데이터 수명 주기에서 가장 중요하지만 가장 시간이 많이 걸리는 단계 중 하나입니다. 다음 다이어그램은 데이터 준비 및 정리 단계가 데이터 엔지니어링 자동화 및 액세스 제어 수명 주기에 어떻게 부합하는지 보여줍니다.
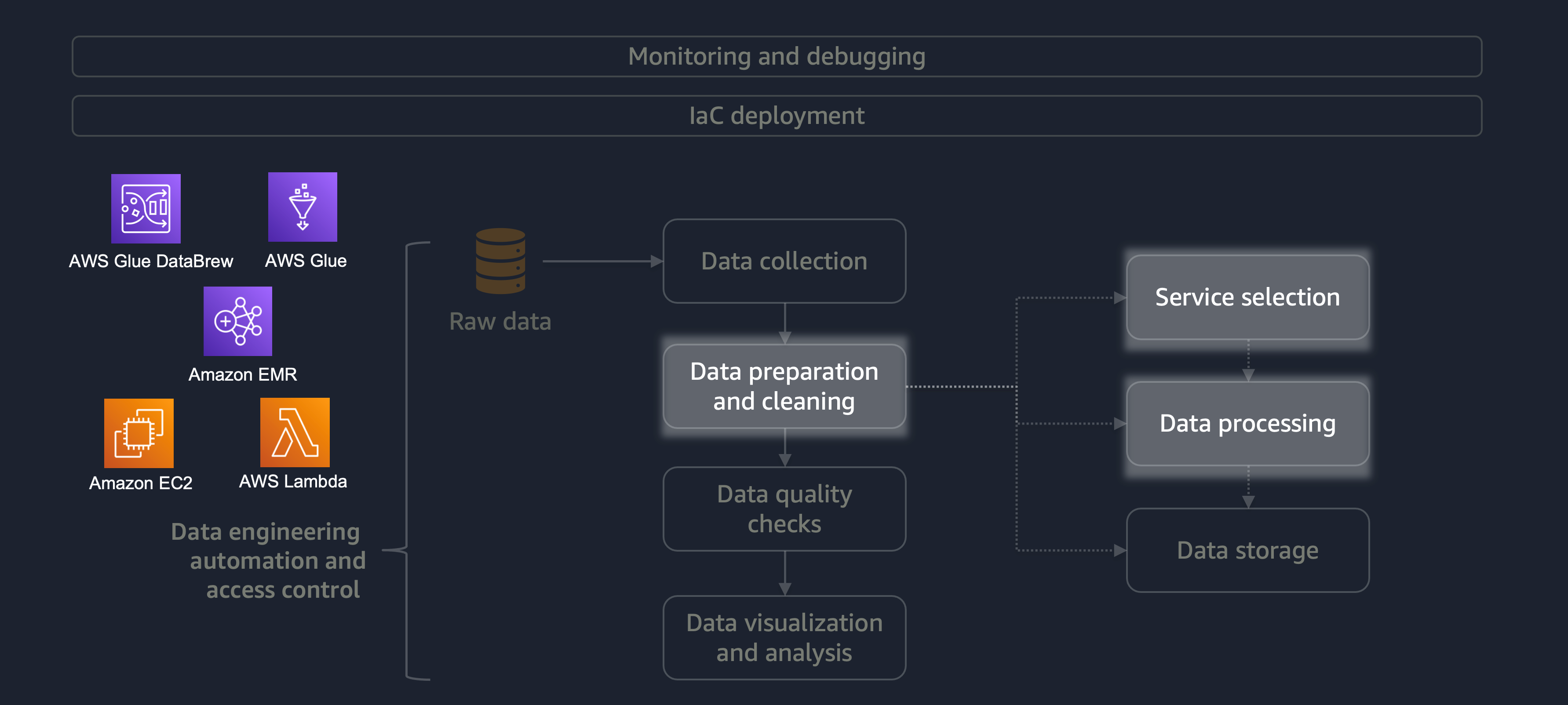
다음은 데이터 준비 또는 정리의 몇 가지 예입니다.
-
텍스트 열을 코드에 매핑
-
빈 열 무시
-
빈 데이터 필드를
0,None또는 로 채우기'' -
개인 식별 정보(PII) 익명화 또는 마스킹
다양한 데이터가 있는 대규모 워크로드가 있는 경우 데이터 준비 및 정리 작업에 Amazon EMRDataFrame 또는를 생성하여 수평 처리로 작업DynamicFrame할 수 있습니다. 또한 AWS Glue DataBrew
분산 처리가 필요하지 않고 15분 이내에 완료할 수 있는 소규모 워크로드의 경우 데이터 준비 및 정리에 AWS Lambda
데이터 준비 및 정리에 적합한 AWS 서비스를 선택하고 선택과 관련된 장단점을 이해하는 것이 중요합니다. 예를 들어 AWS Glue, DataBrew 및 Amazon EMR 중에서 선택하는 시나리오를 생각해 보세요. AWS Glue는 ETL 작업이 빈번하지 않은 경우에 적합합니다. 자주 수행되지 않는 작업은 하루에 한 번, 일주일에 한 번 또는 한 달에 한 번 발생합니다. 또한 데이터 엔지니어가 일반적으로 Spark 코드 작성( 빅 데이터 사용 사례용) 또는 스크립팅에 능숙하다고 가정할 수 있습니다. 작업이 더 자주 발생하는 경우 AWS Glue를 지속적으로 실행하면 비용이 많이 들 수 있습니다. 이 경우 Amazon EMR은 분산 처리 기능을 제공하고 서버리스 버전과 서버 기반 버전을 모두 제공합니다. 데이터 엔지니어에게 적절한 기술이 없거나 결과를 빠르게 전달해야 하는 경우 DataBrew가 좋은 옵션입니다. DataBrew는 코드 개발 노력을 줄이고 데이터 준비 및 정리 프로세스의 속도를 높일 수 있습니다.
처리가 완료되면 ETL 프로세스의 데이터가 AWS에 저장됩니다. 스토리지 선택은 처리하는 데이터 유형에 따라 달라집니다. 예를 들어 그래프 데이터, 키-값 페어 데이터, 이미지, 텍스트 파일 또는 관계형 구조화 데이터와 같은 비관계형 데이터로 작업할 수 있습니다.
다음 다이어그램과 같이 데이터 스토리지에 다음 AWS 서비스를 사용할 수 있습니다.
-
Amazon S3
는 비정형 데이터 또는 반정형 데이터(예: Apache Parquet 파일, 이미지 및 비디오)를 저장합니다. -
Amazon Neptune
은 SPARQL 또는 GREMLIN을 사용하여 쿼리할 수 있는 그래프 데이터 세트를 저장합니다. -
Amazon Keyspaces(Apache Cassandra용)
는 Apache Cassandra와 호환되는 데이터 세트를 저장합니다. -
Amazon Aurora
는 관계형 데이터 세트를 저장합니다. -
Amazon DynamoDB
는 키 값 또는 문서 데이터를 NoSQL 데이터베이스에 저장합니다. -
Amazon Redshift
는 구조화된 데이터에 대한 워크로드를 데이터 웨어하우스에 저장합니다.
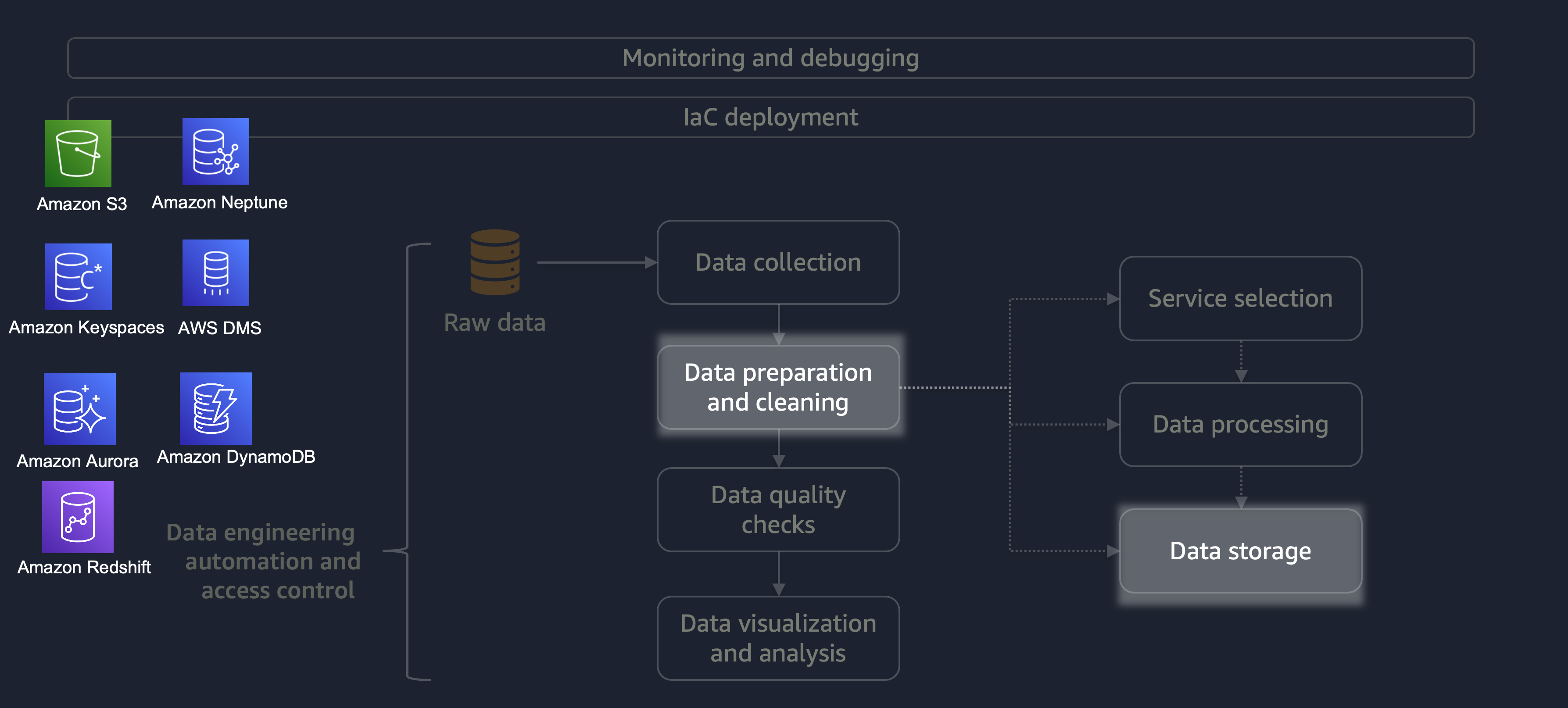
올바른 서비스와 올바른 구성을 사용하면 가장 효율적이고 효과적인 방식으로 데이터를 저장할 수 있습니다. 이렇게 하면 데이터 검색과 관련된 노력이 최소화됩니다.
