기계 번역으로 제공되는 번역입니다. 제공된 번역과 원본 영어의 내용이 상충하는 경우에는 영어 버전이 우선합니다.
에서 조인 힌트 사용 Spark SQL
Spark3.0에서는 런타임에 Spark 사용할 조인 알고리즘 유형을 지정할 수 있습니다. 조인 전략 힌트인 BROADCAST, SHUFFLE_REPLICATE_NL, SHUFFLE_HASH및 MERGE는 다른 관계와 조인Spark할 때 지정된 각 관계에서 힌트 전략을 사용하도록에 지시합니다. 이 섹션에서는 조인 전략 힌트에 대해 자세히 설명합니다.
브로드캐스트
브로드캐스트 해시 조인에서 데이터 세트 중 하나는 다른 데이터 세트보다 훨씬 작습니다. 더 작은 데이터 세트는 메모리에 들어갈 수 있으므로 클러스터의 모든 실행기로 브로드캐스팅됩니다. 데이터가 브로드캐스팅되면 표준 해시 조인이 수행됩니다. 브로드캐스트 해시 조인은 다음 두 단계로 이루어집니다.
-
브로드캐스트 - 더 작은 데이터 세트가 클러스터 내의 모든 실행기로 브로드캐스트됩니다.
-
해시 조인 - 더 작은 데이터 세트는 모든 실행기에서 해시된 다음 더 큰 데이터 세트와 조인됩니다.
sort 또는 merge 작업이 없습니다. 대형 팩트 테이블을 스타 스키마 조인을 수행하는 데 사용되는 더 작은 차원 테이블과 조인할 때 Broadcast Hash는 가장 빠른 조인 알고리즘입니다. 다음 예제에서는 브로드캐스트 해시 조인의 작동 방식을 보여줍니다. spark.sql.autoBroadcastJoinThreshold 속성에 지정된 크기 제한에 관계없이 힌트가 있는 조인 측이 브로드캐스팅됩니다. 조인의 양쪽에 브로드캐스트 힌트가 있는 경우 크기가 더 작은 조인(통계 기준)이 브로드캐스트됩니다. spark.sql.autoBroadcastJoinThreshold 속성의 기본값은 10MB입니다. 조인을 수행할 때 모든 작업자 노드로 브로드캐스트되는 테이블의 최대 크기를 바이트 단위로 구성합니다.
다음 예제에서는 쿼리, 물리적 EXPLAIN 계획 및 쿼리를 실행하는 데 걸리는 시간을 제공합니다. 두 번째 예제 EXPLAIN 계획과 같이 BROADCASTJOIN힌트를 사용하여 브로드캐스트 조인을 강제하는 경우 쿼리 처리 시간이 단축됩니다.
SQL Query : select table1.id,table1.col,table2.id,table2.int_col from table1 join table2 on table1.id = table2.id == Physical Plan == AdaptiveSparkPlan isFinalPlan=false +- SortMergeJoin [id#80L], [id#95L], Inner :- Sort [id#80L ASC NULLS FIRST], false, 0 : +- Exchange hashpartitioning(id#80L, 36), ENSURE_REQUIREMENTS, [id=#725] : +- Filter isnotnull(id#80L) : +- Scan ExistingRDD[id#80L,col#81] +- Sort [id#95L ASC NULLS FIRST], false, 0 +- Exchange hashpartitioning(id#95L, 36), ENSURE_REQUIREMENTS, [id=#726] +- Filter isnotnull(id#95L) +- Scan ExistingRDD[id#95L,int_col#96L] Number of records processed: 799541 Querytime : 21.87715196 seconds
SQL Query : select /*+ BROADCASTJOIN(table1)*/ table1.id,table1.col,table2.id,table2.int_col from table1 join table2 on table1.id = table2.id Physical Plan == AdaptiveSparkPlan isFinalPlan=false\n +- BroadcastHashJoin [id#271L], [id#286L], Inner, BuildLeft, false :- BroadcastExchange HashedRelationBroadcastMode(List(input[0, bigint, false]),false), [id=#955] : +- Filter isnotnull(id#271L) : +- Scan ExistingRDD[id#271L,col#272] +- Filter isnotnull(id#286L) +- Scan ExistingRDD[id#286L,int_col#287L] Number of records processed: 799541 Querytime : 15.35717314 seconds
MERGE
셔플 정렬 병합 조인은 두 데이터 세트가 크고 메모리에 들어갈 수 없는 경우에 선호됩니다. 이름에서 알 수 있듯이이 조인에는 다음 세 단계가 포함됩니다.
-
셔플 단계 - 조인 쿼리의 두 데이터 세트가 모두 셔플됩니다.
-
정렬 단계 - 레코드는 양쪽의 조인 키를 기준으로 정렬됩니다.
-
병합 단계 - 조인 키에 따라 조인 조건의 양쪽이 반복됩니다.
다음 이미지는 셔플 정렬 병합 조인의 방향성 비순환 그래프(DAG) 시각화를 보여줍니다. 두 테이블 모두 처음 두 단계에서 읽습니다. 다음 단계(17단계)에서는 끝에서 셔플링, 정렬 및 병합됩니다.
참고:이 이미지의 일부 단계는 이전 단계에서 완료되었으므로 건너뛴 것으로 표시됩니다. 해당 데이터는 이러한 단계에서 사용하기 위해 캐시되거나 유지됩니다. |
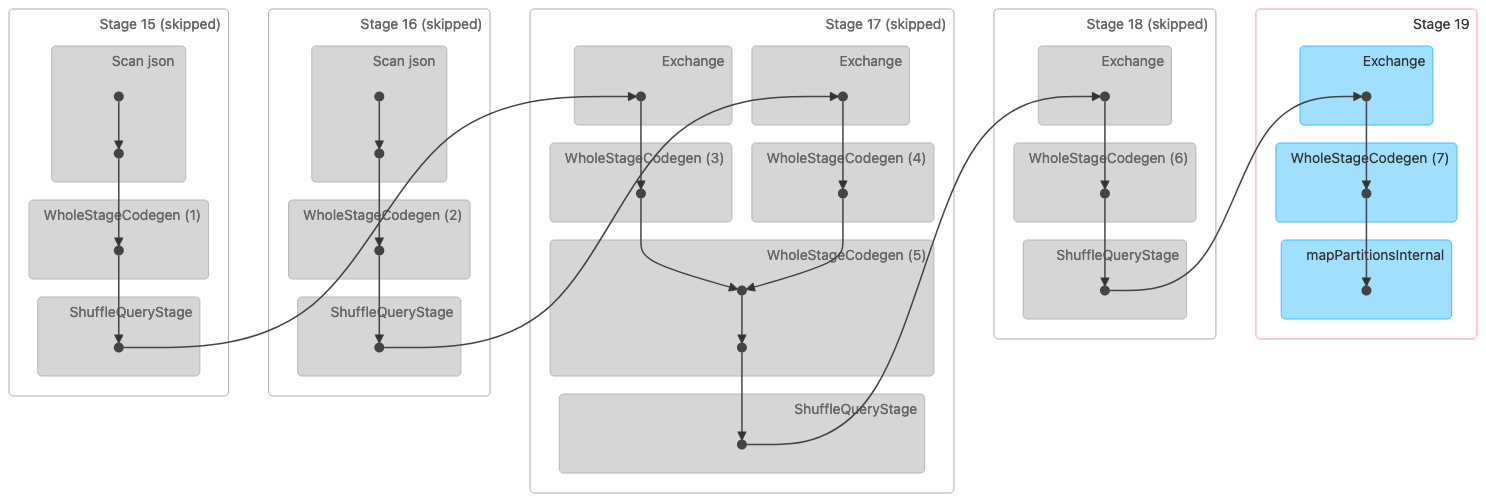
다음은 병합 조인 정렬을 나타내는 물리적 계획입니다.
== Physical Plan == AdaptiveSparkPlan isFinalPlan=false +- SortMergeJoin [id#320L], [id#335L], Inner :- Sort [id#320L ASC NULLS FIRST], false, 0 : +- Exchange hashpartitioning(id#320L, 36), ENSURE_REQUIREMENTS, [id=#1018] : +- Filter isnotnull(id#320L) : +- Scan ExistingRDD[id#320L,col#321] +- Sort [id#335L ASC NULLS FIRST], false, 0 +- Exchange hashpartitioning(id#335L, 36), ENSURE_REQUIREMENTS, [id=#1019] +- Filter isnotnull(id#335L) +- Scan ExistingRDD[id#335L,int_col#336L]
SHUFFLE_HASH
이름에서 알 수 있듯이 셔플 해시 조인은 두 데이터 세트를 모두 셔플링하여 작동합니다. 양쪽에서 동일한 키는 동일한 파티션 또는 작업으로 이어집니다. 데이터가 셔플링되면 두 데이터 세트 중 가장 작은 데이터 세트가 버킷으로 해시된 다음 파티션 내에서 해시 조인이 수행됩니다. 셔플 해시 조인은 전체 데이터 세트가 브로드캐스트되지 않기 때문에 브로드캐스트 해시 조인과 다릅니다. 셔플 해시 조인은 두 단계로 나뉩니다.
-
셔플 단계 - 두 데이터 세트가 모두 셔플됩니다.
-
해시 조인 단계 - 데이터의 작은 쪽은 해시, 버킷팅된 다음 모든 파티션의 큰 쪽과 조인됩니다.
파티션 내부의 셔플 해시 조인에서는 정렬이 필요하지 않습니다. 다음 이미지는 셔플 해시 조인의 단계를 보여줍니다. 데이터는 처음에 읽은 다음 셔플링되고 해시가 생성되어 조인에 사용됩니다.
기본적으로 옵티마이저는 브로드캐스트 해시 조인을 사용할 수 없는 경우 셔플 해시 조인을 선택합니다. 브로드캐스트 해시 조인 임계값 크기(spark.sql.autoBroadcastJoinThreshold)와 선택한 셔플 파티션 수(spark.sql.shuffle.partitions)에 따라 논리적 SQL의 단일 파티션이 로컬 해시 테이블을 빌드할 수 있을 만큼 작을 때 셔플 해시 조인을 사용합니다.
SHUFFLE_REPLICATE_NL
데카르트 제품 조인이라고도 하는 Shuffle-and-Replicate 중첩 루프 조인은 데이터 세트가 브로드캐스트되지 않는다는 점을 제외하면 브로드캐스트 해시 조인과 매우 유사하게 작동합니다.
이 조인 알고리즘에서 셔플은 실제 셔플을 참조하지 않습니다. 키가 동일한 레코드는 동일한 파티션으로 전송되지 않기 때문입니다. 대신 두 데이터 세트의 전체 파티션이 네트워크를 통해 복사됩니다. 데이터 세트의 파티션을 사용할 수 있으면 중첩 루프 조인이 수행됩니다. 첫 번째 데이터 세트의 레코드 X 수와 각 파티션의 두 번째 데이터 세트의 레코드 Y 수가 있는 경우 두 번째 데이터 세트의 각 레코드는 첫 번째 데이터 세트의 모든 레코드와 조인됩니다. 이는 모든 파티션에서 루프 X × Y 시간으로 계속됩니다.
