기계 번역으로 제공되는 번역입니다. 제공된 번역과 원본 영어의 내용이 상충하는 경우에는 영어 버전이 우선합니다.
복원 옵션
다음 섹션에서는 백업이 온프레미스일 때 Amazon Elastic Compute Cloud(Amazon EC2)에서 SQL Server에 대한 두 가지 데이터베이스 복원 옵션을 제공합니다.
Amazon S3 사용
이 SQL Server 데이터베이스 복원 접근 방식에서는 AWS Command Line Interface (AWS CLI)에 대한 Amazon Simple Storage Service(Amazon S3) 명령 또는 Amazon S3 API를 사용하여 백업 파일을 S3 버킷으로 직접 업로드합니다.
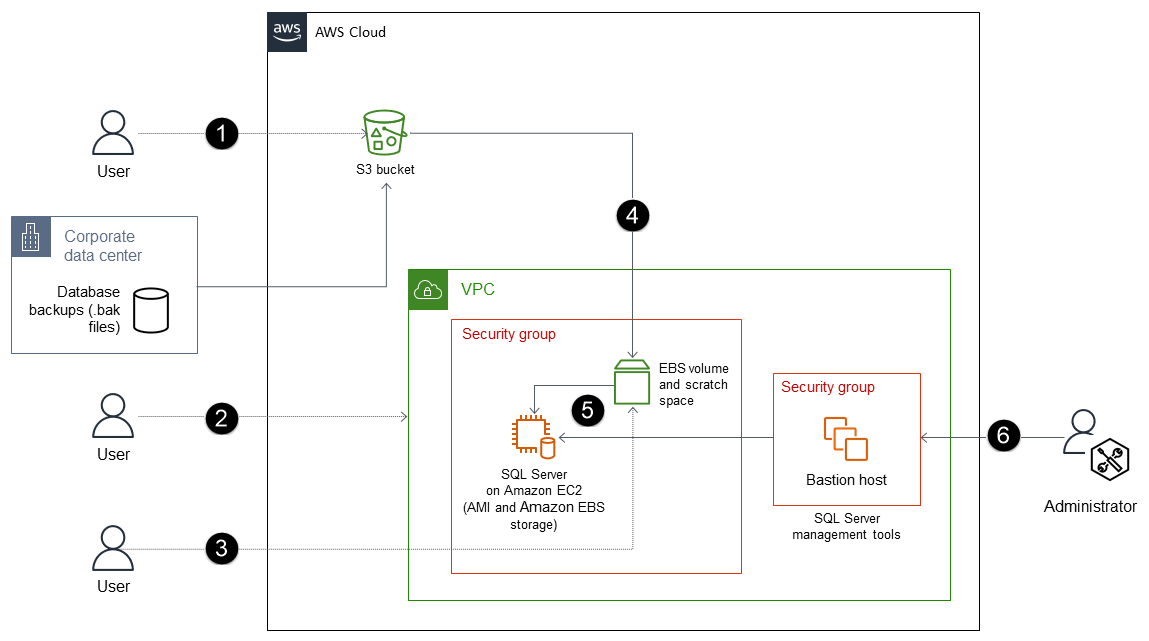
프로세스는 다음 단계로 구성됩니다.
-
S3 버킷을 생성(또는 기존 버킷 사용)하여 백업 파일을 저장하고, AWS CLI 또는 Amazon S3 API를 사용하여 온프레미스 데이터베이스에서 S3 버킷으로 백업(.bak) 파일을 전송합니다.
-
SQL Server Amazon Machine Image(AMI)를 사용하여 EBS에 최적화된 EC2 인스턴스에 SQL Server를 배포합니다. 이 AMI에는 OS 파티션, 데이터 파티션, LOG 파티션, tempdb(NVMe) 스토리지 및 스크래치 공간으로 구성된 EBS 볼륨이 포함되어야 합니다.
-
(선택 사항) 루트가 아닌 EBS 볼륨을 EC2 인스턴스에 연결합니다.
-
백업 파일을 루트가 아닌 EBS 볼륨에 복사합니다.
-
EBS 볼륨의 백업 파일을 EC2 인스턴스의 SQL Server로 복원합니다.
-
SQL Server 관리 도구를 사용하여 데이터베이스를 관리합니다.
AWS DataSync 및 Amazon FSx 사용
이 SQL Server 데이터베이스 복원 접근 방식은 AWS DataSync 를 사용하여 백업 파일을 Amazon FSx for Windows File Server로 전송합니다.
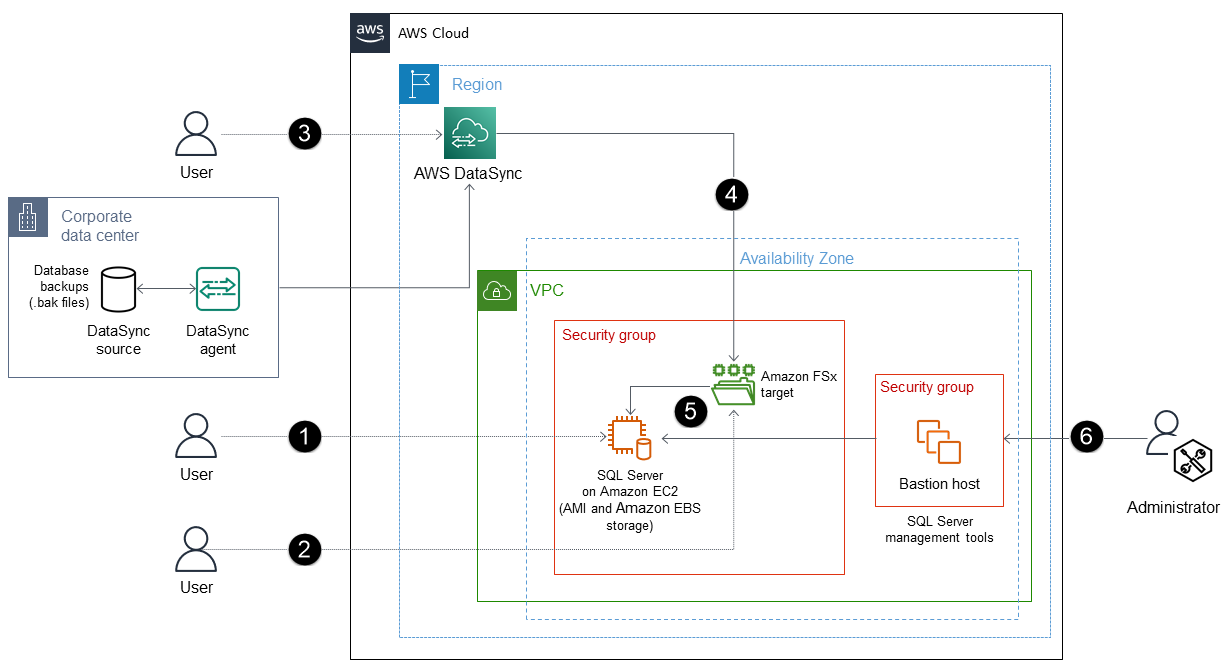
프로세스는 다음 단계로 구성됩니다.
-
OS, 데이터, 로그 및 tempdb로 구성된 EBS 볼륨이 포함된 AMI를 사용하여 NVMe가 연결된 EBS에 최적화된 EC2 인스턴스에 SQL Server를 배포합니다. (예를 들어, 메모리 최적화
r5d.large인스턴스 클래스를 사용할 수 있습니다.) -
FSx for Windows File Server File Server를 사용하여 파일 서버를 생성합니다. 이는 온프레미스 환경에서 SQL Server 백업(.bak) 파일을 다운로드하기 위한 임시 저장 위치로 사용할 수 있습니다.
-
Amazon FSx 파일 서버용 DataSync 엔드포인트 및 에이전트를 생성합니다.
-
DataSync는 Amazon S3가 필요 없이 온프레미스 스토리지와 Amazon FSx 파일 서버 간의 데이터 동기화를 자동화합니다.
-
Amazon FSx 파일 서버의 백업 파일을 EC2 인스턴스의 SQL Server로 복원합니다.
-
SQL Server 관리 도구를 사용하여 데이터베이스를 관리합니다.
참고
Amazon EC2는 여러 SQL Server 에디션을 위한 Microsoft Windows Server AMI 기반 Microsoft SQL Server를
Amazon S3 File Gateway 사용
다음 다이어그램에 나와 있는 것처럼 Amazon S3 File Gateway를
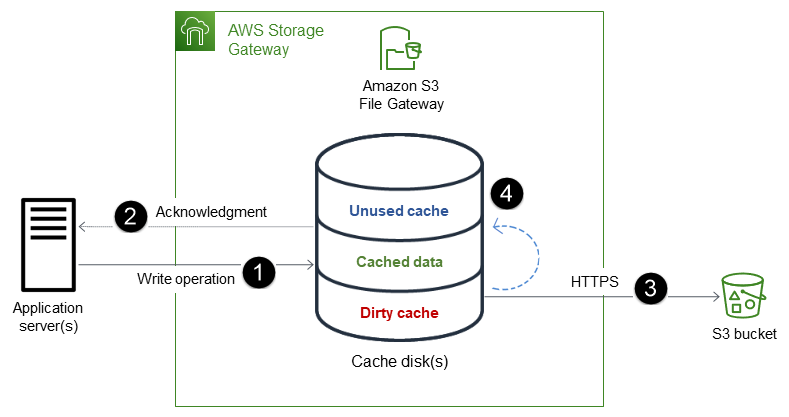
프로세스는 다음 단계로 구성됩니다.
-
데이터는 File Gateway의 로컬 캐시 디스크에 기록됩니다.
-
데이터가 로컬 캐시에 안전하게 보관되면 File Gateway는 클라이언트 애플리케이션에 쓰기 작업 완료를 승인합니다.
-
File Gateway는 데이터를 S3 버킷으로 비동기적으로 전송합니다. 데이터 전송을 최적화하고 HTTPS를 이용해 전송 중인 데이터를 암호화합니다.
-
S3 버킷에 업로드된 데이터는 제거될 때까지 File Gateway의 로컬 캐시에 보관됩니다.
