기계 번역으로 제공되는 번역입니다. 제공된 번역과 원본 영어의 내용이 상충하는 경우에는 영어 버전이 우선합니다.
의 확장 가능한 웹 크롤링 시스템을 위한 아키텍처 AWS
다음 아키텍처 다이어그램은 웹 사이트에서 환경, 사회 및 거버넌스(ESG) 데이터를 윤리적으로 추출하도록 설계된 웹 크롤러 시스템을 보여줍니다. AWS 인프라에 최적화된 Python기반 크롤러를 사용합니다. AWS Batch 를 사용하여 대규모 크롤링 작업을 오케스트레이션하고 Amazon Simple Storage Service(Amazon S3)를 스토리지에 사용합니다. 다운스트림 애플리케이션은 Amazon S3 버킷에서 데이터를 수집하고 저장할 수 있습니다.
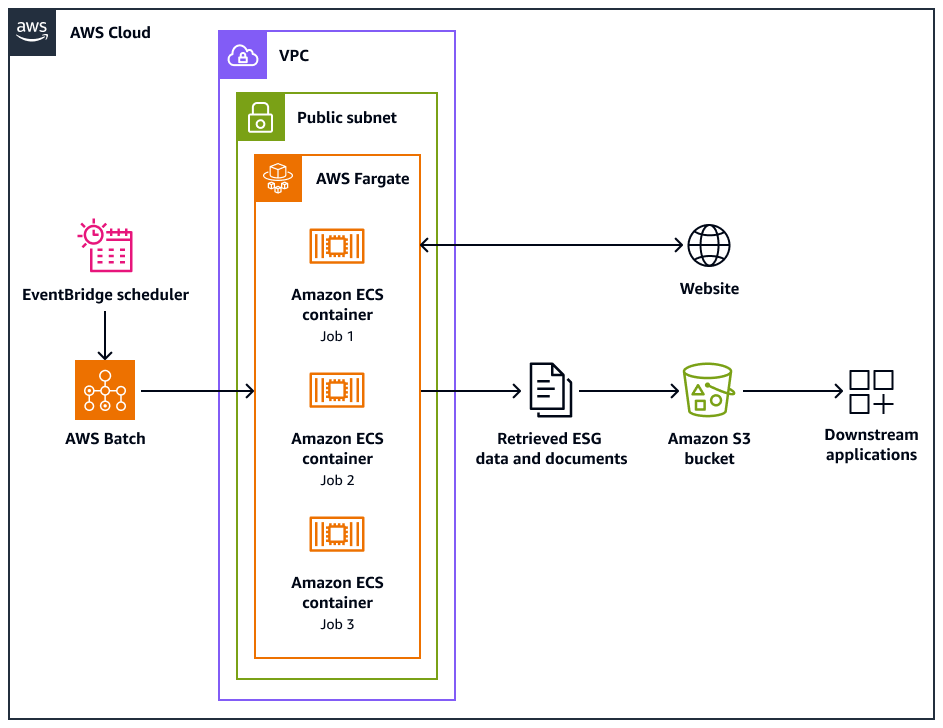
이 다이어그램은 다음 워크플로를 보여줍니다.
-
Amazon EventBridge 스케줄러는 사용자가 예약한 간격으로 크롤링 프로세스를 시작합니다.
-
AWS Batch 는 웹 크롤러 작업의 실행을 관리합니다. AWS Batch 작업 대기열은 보류 중인 크롤링 작업을 보류하고 오케스트레이션합니다.
-
웹 크롤링 작업은 Amazon Elastic Container Service(Amazon ECS) 컨테이너에서 실행됩니다 AWS Fargate. 작업은 Virtual Private Cloud(VPC)의 퍼블릭 서브넷에서 실행됩니다.
-
웹 크롤러는 대상 웹 사이트를 크롤링하고 PDF, CSV 또는 기타 문서 파일과 같은 ESG 데이터 및 문서를 검색합니다.
-
웹 크롤러는 검색된 데이터와 원시 파일을 Amazon S3 버킷에 저장합니다.
-
다른 시스템 또는 애플리케이션은 Amazon S3 버킷에 저장된 데이터와 파일을 수집하거나 처리합니다.
웹 크롤러 설계 및 작업
일부 웹 사이트는 데스크톱 또는 모바일 디바이스에서 실행되도록 특별히 설계되었습니다. 웹 크롤러는 데스크톱 사용자 에이전트 또는 모바일 사용자 에이전트 사용을 지원하도록 설계되었습니다. 이러한 에이전트는 대상 웹 사이트에 성공적으로 요청하는 데 도움이 됩니다.
웹 크롤러가 초기화되면 다음 작업을 수행합니다.
-
웹 크롤러가
setup()메서드를 호출합니다. 이 메서드는 robots.txt 파일을 가져오고 구문 분석합니다.참고
사이트맵을 가져오고 구문 분석하도록 웹 크롤러를 구성할 수도 있습니다.
-
웹 크롤러는 robots.txt 파일을 처리합니다. robots.txt 파일에 크롤링 지연이 지정된 경우 웹 크롤러는 데스크톱 사용자 에이전트의 크롤링 지연을 추출합니다. robots.txt 파일에 크롤링 지연이 지정되지 않은 경우 웹 크롤러는 임의의 지연을 사용합니다.
-
웹 크롤러는
crawl()메서드를 호출하여 크롤링 프로세스를 시작합니다. 대기열에 URLs 없으면 시작 URL이 추가됩니다.참고
크롤러는 최대 페이지 수에 도달하거나 크롤링할 URLs 부족해질 때까지 계속됩니다.
-
크롤러는 URLs을 처리합니다. 대기열의 각 URL에 대해 크롤러는 URL이 이미 크롤링되었는지 확인합니다.
-
URL이 크롤링되지 않은 경우 크롤러는 다음과 같이
crawl_url()메서드를 호출합니다.-
크롤러는 robots.txt 파일을 확인하여 데스크톱 사용자 에이전트를 사용하여 URL을 크롤링할 수 있는지 확인합니다.
-
허용되는 경우 크롤러는 데스크톱 사용자 에이전트를 사용하여 URL을 크롤링하려고 시도합니다.
-
허용되지 않거나 데스크톱 사용자 에이전트가 크롤링하지 못하는 경우 크롤러는 robots.txt 파일을 확인하여 모바일 사용자 에이전트를 사용하여 URL을 크롤링할 수 있는지 확인합니다.
-
허용되는 경우 크롤러는 모바일 사용자 에이전트를 사용하여 URL을 크롤링하려고 시도합니다.
-
-
크롤러는 콘텐츠를 검색하고 처리하는
attempt_crawl()메서드를 호출합니다. 크롤러는 적절한 헤더가 있는 URL로 GET 요청을 보냅니다. 요청이 실패하면 크롤러는 재시도 로직을 사용합니다. -
파일이 HTML 형식인 경우 크롤러는
extract_esg_data()메서드를 호출합니다. Beautiful Soup를 사용하여 HTML 콘텐츠를 구문 분석합니다. 키워드 일치를 사용하여 환경, 사회 및 거버넌스(ESG) 데이터를 추출합니다. 파일이 PDF인 경우 크롤러가
save_pdf()메서드를 호출합니다. 크롤러는 PDF 파일을 다운로드하여 Amazon S3 버킷에 저장합니다. -
크롤러가
extract_news_links()메서드를 호출합니다. 그러면 뉴스 기사, 보도 자료 및 블로그 게시물에 대한 링크가 검색되고 저장됩니다. -
크롤러가
extract_pdf_links()메서드를 호출합니다. 이렇게 하면 PDF 문서에 대한 링크가 식별되고 저장됩니다. -
크롤러가
is_relevant_to_sustainable_finance()메서드를 호출합니다. 이는 사전 정의된 키워드를 사용하여 뉴스 또는 기사가 지속 가능한 금융과 관련이 있는지 확인합니다. -
크롤링을 시도할 때마다 크롤러는
delay()메서드를 사용하여 지연을 구현합니다. robots.txt 파일에 지연이 지정된 경우 해당 값을 사용합니다. 그렇지 않으면 1초에서 3초 사이의 임의 지연을 사용합니다. -
크롤러는
save_esg_data()메서드를 호출하여 ESG 데이터를 CSV 파일에 저장합니다. CSV 파일은 Amazon S3 버킷에 저장됩니다. -
크롤러는
save_news_links()메서드를 호출하여 관련성 정보를 포함하여 뉴스 링크를 CSV 파일에 저장합니다. CSV 파일은 Amazon S3 버킷에 저장됩니다. -
크롤러는
save_pdf_links()메서드를 호출하여 PDF 링크를 CSV 파일에 저장합니다. CSV 파일은 Amazon S3 버킷에 저장됩니다.
일괄 처리 및 데이터 처리
크롤링 프로세스는 구조화된 방식으로 구성되고 수행됩니다. AWS Batch 는 병렬로 배치로 실행되도록 각 회사에 작업을 할당합니다. 각 배치는 데이터 세트에서 식별한 단일 회사의 도메인과 하위 도메인에 중점을 둡니다. 그러나 동일한 배치의 작업은 순차적으로 실행되므로 너무 많은 요청으로 웹 사이트가 중복되지 않습니다. 이를 통해 애플리케이션은 크롤링 워크로드를 보다 효율적으로 관리하고 각 회사에 대해 모든 관련 데이터를 캡처할 수 있습니다.
웹 크롤링을 회사별 배치로 구성하면 수집된 데이터가 컨테이너화됩니다. 이렇게 하면 한 회사의 데이터가 다른 회사의 데이터와 혼합되는 것을 방지할 수 있습니다.
배치를 사용하면 애플리케이션이 웹에서 데이터를 효율적으로 수집하는 동시에 대상 회사 및 해당 웹 도메인을 기반으로 정보의 명확한 구조와 분리를 유지할 수 있습니다. 이 접근 방식은 수집된 데이터의 무결성과 유용성을 보장하는 데 도움이 됩니다. 이는 깔끔하게 구성되고 적절한 회사 및 도메인과 연결되어 있기 때문입니다.
