기계 번역으로 제공되는 번역입니다. 제공된 번역과 원본 영어의 내용이 상충하는 경우에는 영어 버전이 우선합니다.
예측 결과를 입력 레코드에 연결
대규모 데이터세트에서 예측을 실행할 경우 예측에 필요하지 않은 속성을 제외할 수 있습니다. 예측을 실행한 후 때로는 제외된 속성 일부를 보고서에서 해당 예측 또는 다른 입력 데이터에 연결할 수 있습니다. 배치 변환을 사용하여 이러한 데이터 처리 단계를 수행하면 추가적인 사전 처리나 사후 처리가 필요 없습니다. JSON 및 CVS 형식의 입력 파일만 사용할 수 있습니다.
추론을 입력 레코드에 연결하는 워크플로
다음 다이어그램은 추론을 입력 레코드에 연결하는 워크플로를 보여줍니다.
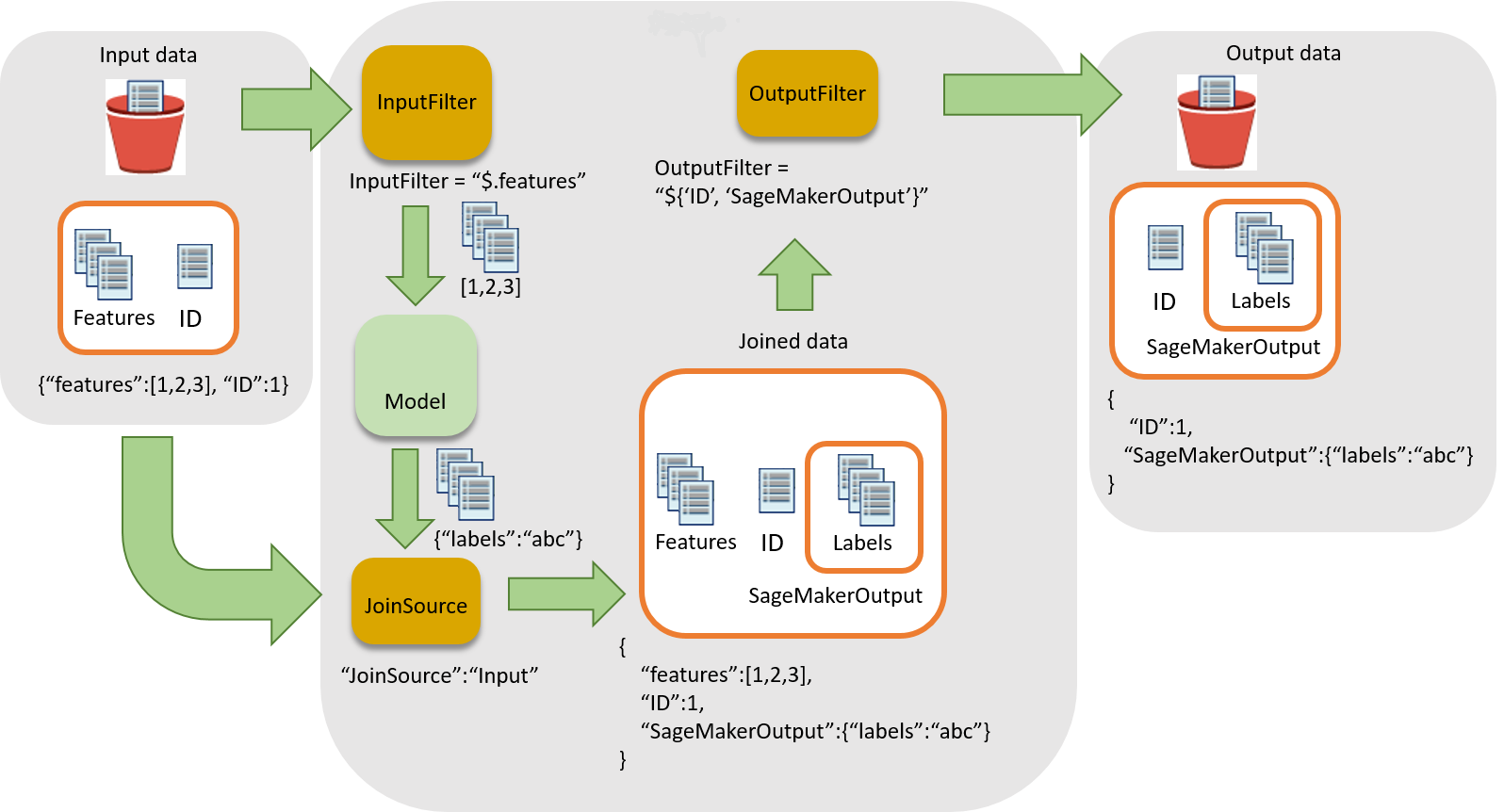
추론을 입력 데이터에 연결할 때 다음 세 가지 단계가 있습니다.
-
입력 데이터를 배치 변환 작업에 전달하기 전에 추론에 필요하지 않은 입력 데이터를 필터링합니다.
InputFilter파라미터를 사용하여 어느 속성을 모델에 대한 입력으로 사용할지 결정합니다. -
입력 데이터를 추론 결과에 연결합니다.
JoinSource파라미터를 사용하여 입력 데이터를 추론과 결합합니다. -
조인된 데이터를 필터링하여 보고서에서 예측을 해석하기 위한 컨텍스트를 제공하는 데 필요한 입력을 유지합니다.
OutputFilter를 사용하여 조인된 데이터세트의 지정된 부분을 출력 파일에 저장합니다.
배치 변환 작업에서 데이터 처리 사용
CreateTransformJob을 사용하여 데이터를 처리할 배치 변환 작업을 생성하는 경우 다음을 수행합니다.
-
DataProcessing데이터 구조에서InputFilter파라미터를 사용하여 모델로 전달할 입력 부분을 지정합니다. -
JoinSource파라미터를 사용하여 원시 데이터를 변환된 데이터와 조인합니다. -
OutputFilter파라미터를 사용하여 조인된 입력과 배치 변환 작업에서 변환된 데이터의 어떤 부분을 출력 파일에 포함할지 지정합니다. -
JSON 또는 CSV 형식 파일을 입력으로 선택합니다.
-
JSON 또는 JSON 라인 형식 입력 파일의 경우, SageMaker AI가 입력 파일에
SageMakerOutput속성을 추가하거나SageMakerInput및SageMakerOutput속성을 사용하여 새로운 JSON 출력 파일을 만듭니다. 자세한 내용은DataProcessing단원을 참조하십시오. -
CSV 형식 입력 파일의 경우, 조인된 입력 데이터 다음에 변환된 데이터가 오며, 출력은 CSV 파일입니다.
-
DataProcessing 구조를 포함하는 알고리즘을 사용하는 경우, 해당 알고리즘이 입력 및 출력 파일 모두에 대해 선택한 형식을 지원해야 합니다. 예를 들어 CreateTransformJob API의 TransformOutput 필드에서, ContentType 및 Accept 파라미터 모두를 다음 값 text/csv, application/json 또는 application/jsonlines 중 하나로 설정해야 합니다. CSV 파일에서 열을 지정하는 구문과 JSON 파일에서 속성을 지정하는 구문은 다릅니다. 잘못된 구문을 사용하면 오류가 발생합니다. 자세한 내용은 배치 변환 예제 단원을 참조하십시오. 기본 제공 알고리즘을 위한 입력 및 출력 형식에 대한 자세한 내용은 Amazon SageMaker 기본 제공 알고리즘 또는 사전 훈련된 모델 사용 섹션을 참조하세요.
입력 및 출력용 레코드 구분 기호 역시 선택한 파일 입력과 일치해야 합니다. SplitType 파라미터는 입력 데이터세트에서 레코드를 분할하는 방법을 나타냅니다. AssembleWith 파라미터는 출력의 레코드를 리어셈블하는 방법을 나타냅니다. 입력 및 출력 형식을 text/csv로 설정한 경우, SplitType 및 AssembleWith 파라미터를 line으로 설정해야 합니다. 입력 및 출력 형식을 application/jsonlines로 설정한 경우, SplitType 및 AssembleWith 모두 line으로 설정할 수 있습니다.
CSV 파일의 경우 포함된 줄 바꿈 문자를 사용할 수 없습니다. JSON 파일의 경우, 속성 이름 SageMakerOutput은 출력용으로 예약됩니다. JSON 입력 파일은 이 이름의 속성을 가질 수 없습니다. 그럴 경우 입력 파일의 해당 데이터가 덮여 쓰일 수 있습니다.
지원되는 JSONPath 연산자
입력 데이터 및 추론을 필터링하고 조인하려면 JSONPath 하위 표현식을 사용합니다. SageMaker AI는 정의된 JSONPath 연산자의 하위 세트만 지원합니다. 다음 표는 지원되는 JSONPath 연산자입니다. CSV 데이터의 경우 각 행은 JSON 배열로 간주되므로 인덱스 기반 JSONPath만 적용할 수 있습니다(예: $[0], $[1:]). CSV 데이터도 RFC 형식
| JSONPath 연산자 | 설명 | 예제 |
|---|---|---|
$ |
쿼리의 루트 요소. 이 연산자는 모든 경로 표현식의 시작 부분에 필요합니다. |
$ |
. |
점으로 표기된 하위 요소. |
|
* |
와일드카드. 속성 이름 또는 숫자 값 대신 사용합니다. |
|
[' |
괄호로 표기된 요소 또는 다중 하위 요소. |
|
[ |
인덱스 또는 인덱스 배열. 음의 인덱스 값도 지원됩니다. |
|
[ |
배열 조각 연산자. 배열 조각() 메서드는 배열의 한 부분을 추출하고 새 배열을 반환합니다. |
|
대괄호 표기법을 사용하여 주어진 필드의 여러 하위 요소를 지정하는 경우 대괄호 안에 하위 요소를 추가 중첩할 수 없습니다. 예를 들어 $.field1.['child1','child2']는 지원되는 반면 $.field1.['child1','child2.grandchild']는 지원되지 않습니다.
JSONPath 연산자에 대한 자세한 내용은 GitHub의 JsonPath
배치 변환 예제
다음 예제에서는 입력 데이터를 예측 결과와 조인하는 몇 가지 일반적인 방법을 보여줍니다.
주제
예제: 추론만 출력
기본적으로 DataProcessing 파라미터는 추론 결과를 입력과 조인하지 않습니다. 추론 결과만 출력합니다.
결과를 입력과 조인하지 않도록 명시적으로 지정하려면 Amazon SageMaker Python SDK
sm_transformer = sagemaker.transformer.Transformer(…) sm_transformer.transform(…, input_filter="$", join_source= "None", output_filter="$")
AWS SDK for Python을 사용하여 추론을 출력하려면 CreateTransformJob 요청에 다음 코드를 추가합니다. 다음 코드는 기본 동작을 모방합니다.
{ "DataProcessing": { "InputFilter": "$", "JoinSource": "None", "OutputFilter": "$" } }
예제: 입력 데이터와 조인된 추론 출력
Amazon SageMaker Python SDKassemble_with 및 accept 파라미터를 지정하세요. 변환 호출을 사용할 때는 join_source 파라미터에 대해 Input을 지정하고 split_type 및 content_type 파라미터도 지정하세요. split_type 파라미터는 assemble_with와 같은 값을 가져야 하고 content_type 파라미터는 accept와 같은 값을 가져야 합니다. 파라미터 및 허용되는 값에 대한 자세한 내용은 Amazon SageMaker AI Python SDK의 변환기
sm_transformer = sagemaker.transformer.Transformer(…, assemble_with="Line", accept="text/csv") sm_transformer.transform(…, join_source="Input", split_type="Line", content_type="text/csv")
AWS SDK for Python(Boto 3)을 사용하는 경우 CreateTransformJob 요청에 다음 코드를 추가하여 모든 입력 데이터를 추론과 조인합니다. Accept 및 ContentType의 값이 일치해야 하고, AssembleWith 및 SplitType의 값도 일치해야 합니다.
{ "DataProcessing": { "JoinSource": "Input" }, "TransformOutput": { "Accept": "text/csv", "AssembleWith": "Line" }, "TransformInput": { "ContentType": "text/csv", "SplitType": "Line" } }
JSON 또는 JSON 라인 입력 파일의 경우, 결과가 JSON 파일의 SageMakerOutput 키에 있습니다. 예를 들어 입력이 키-값 페어 {"key":1}을 포함하는 JSON 파일인 경우 데이터 변환 결과는 {"label":1}일 수 있습니다.
SageMaker AI는 2가지 모두 입력 파일의 SageMakerInput 키에 저장합니다.
{ "key":1, "SageMakerOutput":{"label":1} }
참고
JSON에 대한 조인된 결과는 키-값 페어 객체여야 합니다. 입력이 키-값 페어 객체가 아닌 경우, SageMaker AI는 새로운 JSON 파일을 만듭니다. 새 JSON 파일에서 입력 데이터는 SageMakerInput 키에 저장되고, 결과는 SageMakerOutput 값으로 저장됩니다.
CSV 파일의 경우, 예를 들어 레코드가 [1,2,3]이고, 레이블 결과가 [1]인 경우, 출력 파일은 [1,2,3,1]을 포함하게 됩니다.
예제: 입력 데이터와 조인된 추론 출력 및 입력에서 ID 열 제외(CSV)
Amazon SageMaker Python SDKinput_filter에 대한 JSONPath 하위 표현식을 지정하세요. 예를 들어 입력 데이터가 5개 열을 포함하고 첫 번째 열이 ID 열인 경우, 다음과 같은 변환기 요청을 사용하여 기능으로 ID 열을 제외한 모든 열을 선택하세요. 변환기는 여전히 추론과 조인된 모든 입력 열을 출력합니다. 파라미터 및 허용되는 값에 대한 자세한 내용은 Amazon SageMaker AI Python SDK의 변환기
sm_transformer = sagemaker.transformer.Transformer(…, assemble_with="Line", accept="text/csv") sm_transformer.transform(…, split_type="Line", content_type="text/csv", input_filter="$[1:]", join_source="Input")
AWS SDK for Python(Boto 3)을 사용하는 경우 CreateTransformJob 요청에 다음 코드를 추가합니다.
{ "DataProcessing": { "InputFilter": "$[1:]", "JoinSource": "Input" }, "TransformOutput": { "Accept": "text/csv", "AssembleWith": "Line" }, "TransformInput": { "ContentType": "text/csv", "SplitType": "Line" } }
SageMaker AI에서 열을 지정하려면 배열 요소의 인덱스를 사용합니다. 첫 번째 열은 인덱스 0, 두 번째 열은 인덱스 1, 여섯 번째 열은 인덱스 5입니다.
입력에서 첫 번째 열을 제외하려면 InputFilter를 "$[1:]"로 설정합니다. 콜론(:)은 SageMaker AI에게 두 값 사이의 모든 요소를 포함(두 값도 포함)하도록 지시합니다. 예를 들어, $[1:4]는 두 번째 열부터 다섯 번째 열까지 지정합니다.
예를 들어, [5:] 같이 콜론 뒤의 숫자를 생략할 경우 하위 집합에 여섯 번째 열부터 마지막 열까지 모든 열이 포함됩니다. 예를 들어, [:5] 같이 콜론 앞의 숫자를 생략할 경우 하위 집합에 첫 번째 열(인덱스 0)부터 여섯 번째 열까지 모든 열이 포함됩니다.
예제: ID 열과 조인된 추론 출력 및 입력에서 ID 열 제외(CSV)
Amazon SageMaker Python SDKoutput_filter를 지정하여 특정 입력 열(예: ID 열)만 추론과 결합하도록 출력을 지정할 수 있습니다. output_filter는 JSONPath 하위 표현식을 사용하여 입력 데이터를 추론 결과와 조인한 후 출력으로 반환할 열을 지정합니다. 다음 요청은 ID 열을 제외한 상태에서 예측한 다음 ID 열을 추론과 결합하는 방법을 보여줍니다. 다음 예제에서는 출력의 마지막 열(-1)에 추론이 포함되어 있다는 점에 유의하세요. JSON 파일을 사용하는 경우 SageMaker AI는 추론 결과를 속성 SageMakerOutput에 저장합니다. 파라미터 및 허용되는 값에 대한 자세한 내용은 Amazon SageMaker AI Python SDK의 변환기
sm_transformer = sagemaker.transformer.Transformer(…, assemble_with="Line", accept="text/csv") sm_transformer.transform(…, split_type="Line", content_type="text/csv", input_filter="$[1:]", join_source="Input", output_filter="$[0,-1]")
AWS SDK for Python(Boto 3)을 사용하는 경우 CreateTransformJob 요청에 다음 코드를 추가하여 ID 열만 추론과 조인합니다.
{ "DataProcessing": { "InputFilter": "$[1:]", "JoinSource": "Input", "OutputFilter": "$[0,-1]" }, "TransformOutput": { "Accept": "text/csv", "AssembleWith": "Line" }, "TransformInput": { "ContentType": "text/csv", "SplitType": "Line" } }
주의
JSON 형식의 입력 파일을 사용하는 경우에는 파일에 속성 이름 SageMakerOutput이 포함되지 못합니다. 이 속성 이름은 출력 파일에서 추론용으로 예약됩니다. JSON 형식의 입력 파일에 이 이름의 속성이 있는 경우에는 입력 파일의 값을 추론이 덮어쓰게 될 수 있습니다.
