기계 번역으로 제공되는 번역입니다. 제공된 번역과 원본 영어의 내용이 상충하는 경우에는 영어 버전이 우선합니다.
SageMaker Clarify를 사용한 공정성, 모델 설명 가능성 및 편향 감지
Amazon SageMaker Clarify를 사용하여 공정성과 모델 설명 가능성을 이해하고 모델의 편향을 설명하고 감지할 수 있습니다. SageMaker Clarify 처리 작업을 구성하여 편향 지표와 특성 어트리뷰션을 계산하고 모델 설명 가능성에 대한 보고서를 생성할 수 있습니다. SageMaker Clarify 처리 작업은 특수한 SageMaker Clarify 컨테이너 이미지를 사용하여 구현됩니다. 다음 페이지에서는 SageMaker Clarify의 작동 방식과 분석을 시작하는 방법을 설명합니다.
기계 학습 예측을 위한 공정성과 모델 설명 가능성은 무엇인가요?
기계 학습(ML) 모델은 금융 서비스, 의료, 교육 및 인적 자원과 같은 분야에서 의사 결정을 내리는 데 도움을 줍니다. 정책 입안자와 규제 기관 및 지지자들은 기계 학습과 데이터 기반 시스템이 야기하는 윤리적 및 정책적 당면 과제에 대한 인식 제고에 나서고 있습니다. Amazon SageMaker Clarify는 ML 모델이 특정 예측을 수행한 이유와 훈련 또는 추론 중에 이 편향이 이 예측에 영향을 미치는지를 이해하는 데 도움이 될 수 있습니다. 또한 SageMaker Clarify는 편향이 적고 더 이해하기 쉬운 기계 학습 모델을 구축하는 데 도움이 되는 도구를 제공합니다. 또한 위험 및 규정 준수 팀과 외부 규제 기관에 알리는 데 사용할 수 있는 모델 거버넌스 보고서도 생성할 수 있습니다. SageMaker Clarify를 사용하면 다음을 수행할 수 있습니다.
-
모델 예측에서 편향을 감지하고 모델 예측을 설명합니다.
-
훈련 전 데이터에서 편향 유형을 식별합니다.
-
모델 훈련 중이나 모델이 프로덕션 단계에 있을 때 나타날 수 있는 훈련 후 데이터에서 편향 유형을 식별합니다.
SageMaker Clarify는 이러한 모델이 특성 어트리뷰션을 사용하여 예측을 수행하는 방법을 설명하는 데 도움이 됩니다. 이는 또한 프로덕션 단계의 추론 모델의 편향이나 특성 어트리뷰션 드리프트를 모니터링할 수 있습니다. 이 정보를 이용하면 다음 영역에서 도움이 될 수 있습니다.
-
규제 - 정책 입안자 및 기타 규제 기관은 ML 모델의 출력을 사용하는 결정의 차별적 영향에 대해 우려할 수 있습니다. 예를 들어 ML 모델은 편향을 인코딩하고 자동화된 결정에 영향을 미칠 수 있습니다.
-
비즈니스 - 규제된 도메인에는 ML 모델이 예측하는 방법에 대한 신뢰할 수 있는 설명이 필요할 수 있습니다. 모델 설명 가능성은 신뢰성, 안전성 및 규정 준수에 의존하는 산업에 특히 중요할 수 있습니다. 여기에는 금융 서비스, 인사, 의료 및 자동 운송이 포함될 수 있습니다. 예를 들어 대출 애플리케이션에서 ML 모델이 대출 담당자, 예측 담당자 및 고객에게 특정 예측을 수행한 방법에 대한 설명을 제공해야 할 수 있습니다.
-
데이터 과학 - 데이터 과학자와 ML 엔지니어는 모델이 노이즈가 있거나 관련이 없는 특성을 기반으로 추론을 하는지를 확인할 수 있을 때 ML 모델을 디버깅하고 개선할 수 있습니다. 또한 모델 및 모델이 직면할 수 있는 장애 모드의 제한 사항을 이해할 수 있습니다.
SageMaker Clarify를 SageMaker SageMaker AI 파이프라인에 통합하는 사기 자동차 클레임을 위한 완전한 기계 학습 모델을 설계하고 구축하는 방법을 보여주는 블로그 게시물은 아키텍트를 참조하고 AWS end-to-end Amazon SageMaker AI 데모를 사용하여 전체 기계 학습 수명 주기를 구축
ML 수명 주기 내에서의 공정성 및 설명 가능성 평가를 위한 모범 사례
프로세스로서의 공정성 – 편향과 공정성의 개념은 적용 분야에 따라 달라집니다. 편향 측정 및 편향 지표 선택은 사회적, 법적 및 기타 비기술적 고려 사항에 따라 달라질 수 있습니다. 공정성 인식 ML 접근 방식을 성공적으로 채택하려면 주요 이해관계자의 합의와 협업이 필요합니다. 여기에는 제품, 정책, 법률, 엔지니어링, AI/ML 팀, 최종 사용자 및 커뮤니티가 포함될 수 있습니다.
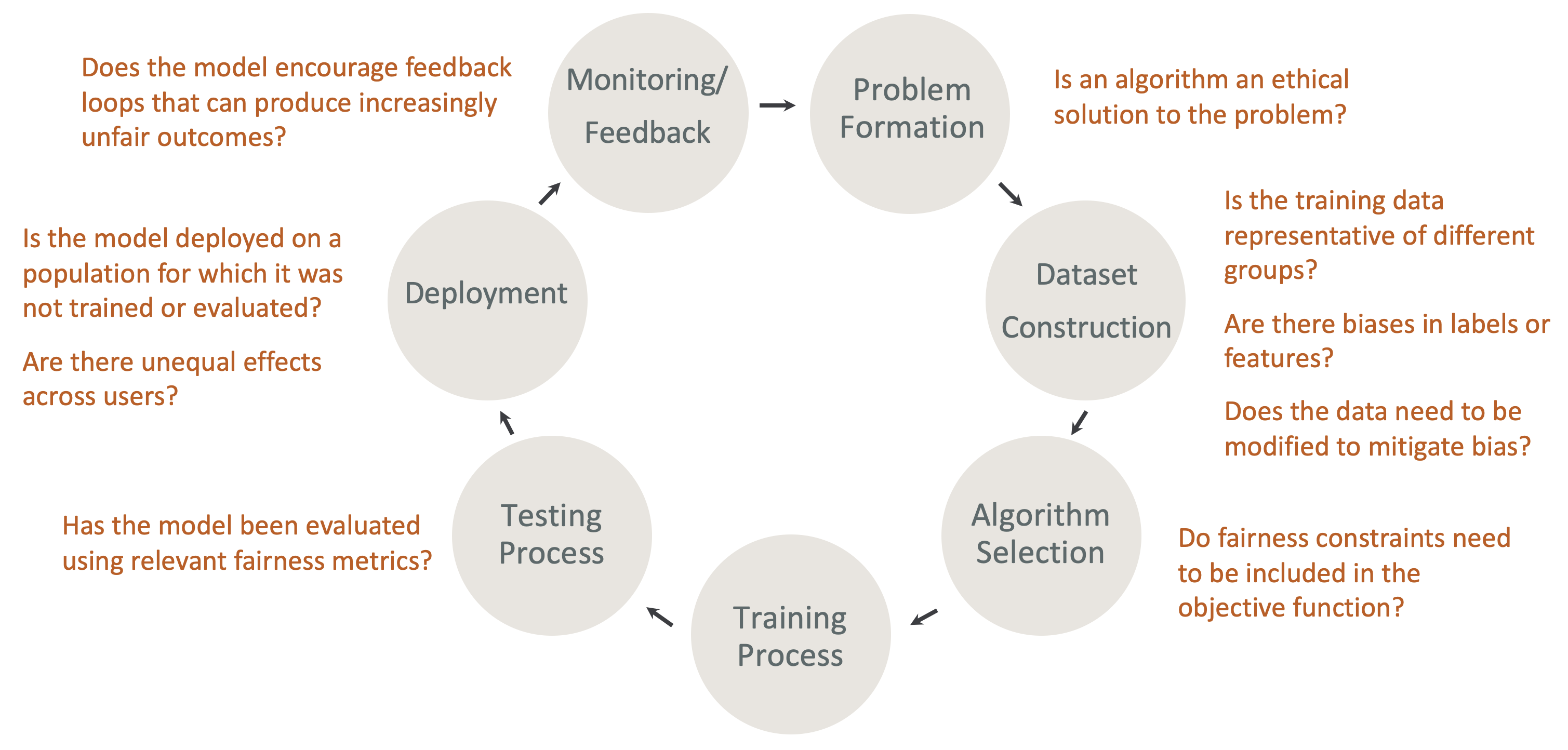
ML 수명 주기의 설계상 공정성 및 설명 가능성 - ML 수명 주기의 각 단계에서 공정성과 설명 가능성을 고려합니다. 이러한 단계에는 문제 형성, 데이터세트 구성, 알고리즘 선택, 모델 훈련 프로세스, 테스트 프로세스, 배포, 모니터링 및 피드백이 포함됩니다. 이러한 분석을 수행할 수 있는 올바른 도구를 갖추는 것이 중요합니다. ML 수명 주기 동안 다음 질문을 하는 것이 좋습니다.
-
모델이 점점 더 불공정한 결과를 가져올 수 있는 피드백 루프를 장려하나요?
-
알고리즘이 문제에 대한 윤리적 해결책인가요?
-
훈련 데이터가 다른 그룹을 대표하나요?
-
레이블 또는 특성에 편향이 있나요?
-
편향을 완화하려면 데이터를 수정해야 하나요?
-
공정성 제약 조건을 목표 함수에 포함해야 하나요?
-
관련 공정성 지표를 사용하여 모델을 평가했나요?
-
사용자 간에 불평등한 영향이 있나요?
-
모델이 훈련 또는 평가되지 않은 모집단에 배포되나요?
SageMaker AI 설명 및 편향 설명서 가이드
편향은 모델을 훈련하기 전과 후에 데이터에서 발생하고 측정될 수 있습니다. SageMaker Clarify는 훈련 후 모델 예측과 프로덕션에 배포된 모델에 대한 설명을 제공할 수 있습니다. SageMaker Clarify는 또한 프로덕션 단계의 모델에 기준 설명 어트리뷰션의 드리프트가 있는지 모니터링하고 필요한 경우 기준을 계산할 수 있습니다. SageMaker Clarify를 사용하여 편향을 설명하고 감지하기 위한 설명서는 다음과 같이 구성되어 있습니다.
-
편향 및 설명 가능성 관련 처리 작업 설정에 대한 자세한 내용은 SageMaker Clarify 처리 작업 구성 섹션을 참조하세요.
-
모델 훈련에 사용되기 이전의 사전 처리 데이터에서 편향을 감지하는 방법에 대한 자세한 내용은 훈련 전 데이터 편향 섹션을 참조하세요.
-
훈련 후 데이터 편향 및 모델 편향 감지에 대한 자세한 내용은 훈련 후 데이터 및 모델 편향 섹션을 참조하세요.
-
훈련 후 모델의 예측을 설명하기 위한 어느 모델에나 사용 가능한 특성 어트리뷰션 접근법에 대한 자세한 내용은 모델 설명 가능성 섹션을 참조하세요.
-
모델 훈련 중에 확립된 기준을 벗어나는 특성 어트리뷰션의 드리프트를 모니터링하는 방법에 대한 자세한 내용은 프로덕션 환경의 모델에 대한 특성 어트리뷰션 드리프트 섹션을 참조하세요.
-
프로덕션 단계인 모델의 기준 드리프트 모니터링에 대한 자세한 내용은 프로덕션 환경의 모델에 대한 바이어스 드리프트 섹션을 참조하세요.
-
SageMaker AI 엔드포인트에서 실시간으로 설명을 얻는 방법에 대한 자세한 내용은 섹션을 참조하세요SageMaker Claify를 통한 온라인 설명 가능성.
SageMaker Clarify 처리 작업의 작동 방식
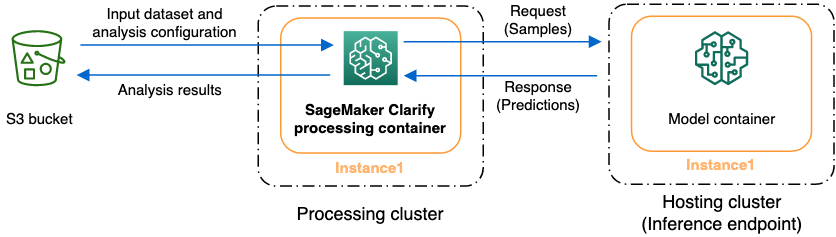
SageMaker Clarify를 사용하면 데이터세트와 모델을 분석하여 설명 가능성을 구현하고 편향을 파악할 수 있습니다. SageMaker Clarify 처리 작업은 SageMaker Clarify 처리 컨테이너를 사용하여 입력 데이터세트를 포함하는 Amazon S3 버킷과 상호작용합니다. SageMaker Clarify를 사용하여 SageMaker AI 추론 엔드포인트에 배포된 고객 모델을 분석할 수도 있습니다.
다음 그래픽은 SageMaker Clarify 처리 작업이 입력 데이터 및 고객 모델(선택사항)과 상호작용하는 방식을 보여줍니다. 이 상호작용은 수행 중인 분석의 구체적인 유형에 따라 달라집니다. SageMaker Clarify 처리 컨테이너는 S3 버킷에서 분석을 위한 입력 데이터세트 및 구성을 가져옵니다. 특징 분석을 비롯한 특정 분석 유형의 경우, SageMaker Clarify 처리 컨테이너는 반드시 모델 컨테이너에 요청을 보내도록 되어 있습니다. 그런 다음에는 모델 컨테이너가 보내오는 응답에서 모델 예측을 얻어냅니다. 이 작업이 완료되면, SageMaker Clarify 처리 컨테이너는 분석 결과를 계산하여 이를 S3 버킷에 저장합니다.
사용자는 기계 학습 워크플로 수명 주기의 여러 단계에서 SageMaker Clarify 처리 작업을 실행할 수 있습니다. SageMaker Clative는 다음과 같은 분석 유형을 계산하는 데 도움이 될 수 있습니다.
-
훈련 전 편향 지표. 이 지표는 데이터의 편향을 파악하도록 도와주므로, 사용자는 이를 해결하여 보다 공정한 데이터세트를 기반으로 모델을 훈련할 수 있게 됩니다. 훈련 전 편향 지표에 대한 자세한 내용은 훈련 전 편향 지표 섹션을 참조하세요. 훈련 전 편향 지표를 분석하는 작업을 실행하려면, 해당 데이터세트와 JSON 분석 구성 파일을 제공하여 분석 구성 파일해야 합니다.
-
훈련 후 편향 지표. 이 지표를 사용하면 알고리즘이나 하이퍼파라미터 선택에 의해 발생한 편향 또는 흐름 초반에는 뚜렷하지 않았던 편향을 파악하는 데 도움이 될 수 있습니다. 훈련 후 편향 지표에 대한 자세한 내용은 훈련 후 데이터 및 모델 편향 지표 섹션을 참조하세요. SageMaker Clarify는 데이터 및 레이블 외에도 모델 예측을 사용하여 편향을 식별합니다. 훈련 후 편향 지표를 분석하는 작업을 실행하려면, 해당 데이터세트와 JSON 분석 구성 파일을 제공해야 합니다. 해당 구성에는 모델 또는 엔드포인트 이름이 포함되어야 합니다.
-
특성이 모델 예측 결과에 미치는 영향을 이해하는 데 도움이 될 수 있는 Shapley 값. Shapley 값에 대한 자세한 내용은 Shapley 값을 사용하는 기능 특성 섹션을 참조하세요. 이 특징을 사용하려면 훈련된 모델이 필요합니다.
-
한 특성의 값을 변경할 경우 예측 대상 변수가 얼마나 변하게 되는지 파악하는 데 도움이 되는 부분 종속성 도표(PDP). PDP에 대한 자세한 내용은 부분 종속성 도표(PDP) 분석 섹션을 참조하세요. 이 특성에는 훈련된 모델이 필요합니다.
SageMaker Clarify는 훈련 후 편향 지표와 특징 속성을 계산하기 위해 모델 예측을 필요로 합니다. 엔드포인트는 사용자가 제공할 수 있으며, 미제공 시 SageMaker Clarify가 해당 모델의 이름을 사용하여 섀도우 엔드포인트라고도 하는 임시 엔드포인트를 생성합니다. SageMaker Clarify 컨테이너는 계산이 완료되면 섀도우 엔드포인트를 삭제합니다. 개괄적으로, SageMaker Clarify 컨테이너는 다음과 같은 단계를 완료합니다.
-
입력 및 매개변수의 유효성을 검사합니다.
-
섀도우 엔드포인트를 생성합니다(모델 이름이 제공된 경우).
-
입력 데이터세트를 데이터 프레임에 로드합니다.
-
필요한 경우 엔드포인트에서 모델 예측을 가져옵니다.
-
편향 지표와 특징 속성을 계산합니다.
-
섀도우 엔드포인트를 삭제합니다.
-
분석 결과를 생성합니다.
SageMaker Clarify 처리 작업이 완료된 후 분석 결과는 해당 작업의 처리 출력 매개변수에서 지정한 출력 위치에 저장됩니다. 이러한 결과에는 편향 지표 및 글로벌 특징 속성이 포함된 JSON 파일, 시각적 보고서, 그리고 로컬 특징 속성을 위한 추가 파일이 포함됩니다. 결과는 출력 위치에서 다운로드하여 볼 수 있습니다.
편향 지표, 설명 가능성 및 해석 방법에 대한 추가 정보는 Learn How Amazon SageMaker Clarify Helps Detect Bias
샘플 노트북
다음 섹션에는 SageMaker Clarify 사용을 시작하는 데 도움이 되는 노트북이 포함되어 있습니다. 이 노트북을 분산 작업 내부의 작업을 포함한 특수 작업 및 컴퓨터 비전에 사용할 수 있습니다.
시작
다음 샘플 노트북에서는 SageMaker Clarify를 사용하여 설명 가능성 및 모델 편향 작업을 시작하는 방법을 보여줍니다. 이러한 작업에는 처리 작업 만들기, 기계 학습(ML) 모델 훈련, 모델 예측 모니터링이 포함됩니다.
-
Explainability and bias detection with Amazon SageMaker Clarify
– SageMaker Clarify를 사용하여 편향을 감지하고 모델 예측을 설명하기 위한 처리 작업을 만듭니다. -
Monitoring bias drift and feature attribution drift Amazon SageMaker Clarify
- Amazon SageMaker Model Monitor를 사용하여 시간 경과에 따른 바이어스 드리프트 및 특징 속성 드리프트를 모니터링합니다. -
Mitigate Bias, train another unbiased model, and put it in the model registry
- Synthetic Minority Over-sampling Technique(SMOTE) 및 SageMaker Clarify를 사용하여 편향을 완화하고, 다른 모델을 훈련한 다음 새 모델을 모델 레지스트리에 넣습니다. 또한 이 샘플 노트북은 데이터, 코드 및 모델 메타데이터를 포함한 새 모델 아티팩트를 모델 레지스트리에 배치하는 방법을 보여줍니다. 이 노트북은 SageMaker Clarify를 Architect에 설명된 SageMaker AI 파이프라인에 통합하고 블로그 게시물을 사용하여 전체 기계 학습 수명 주기를 구축하는 방법을 보여주는 시리즈의 일부입니다. AWS
특수 사례
다음 노트북은 자체 컨테이너 내부를 포함한 특수 사례와 자연어 처리 작업에 SageMaker Clarify를 사용하는 방법을 보여줍니다.
-
Fairness and Explainability with SageMaker Clarify (Bring Your Own Container)
- SageMaker Clarify와 통합할 수 있는 자체 모델 및 컨테이너를 빌드하여 편향을 측정하고 설명 가능성 분석 보고서를 생성합니다. 또한 이 샘플 노트북에서는 주요 용어를 소개하고 SageMaker Studio Classic을 통해 보고서에 액세스하는 방법을 보여줍니다. -
Fairness and Explainability with SageMaker Clarify Spark Distributed Processing
- 분산 처리를 사용하여 데이터세트의 훈련 전 편향과 모델의 훈련 후 편향을 측정하는 SageMaker Clarify 작업을 실행합니다. 또한 이 샘플 노트북은 모델 출력에서 입력 특성의 중요성에 대한 설명을 얻고 SageMaker Studio Classic을 통해 설명 가능성 분석 보고서에 액세스하는 방법을 보여줍니다. -
Explainability with SageMaker Clarify - Partial Dependence Plots (PDP)
- SageMaker Clarify를 사용하여 PDP를 생성하고 모델 설명 가능성 보고서에 액세스합니다. -
Explaining text sentiment analysis using SageMaker Clarify Natural language processing (NLP) explainability
- 텍스트 감정 분석에 SageMaker Clarify를 사용합니다.
이 노트북은 Amazon SageMaker Studio Classic에서 실행이 검증되었습니다. Studio Classic에서 노트북을 여는 방법에 대한 지침이 필요한 경우, Amazon SageMaker Studio Classic 노트북 만들기 또는 열기 섹션을 참조하세요. 커널을 선택하라는 메시지가 표시되면, Python 3(데이터 과학)를 선택합니다.
