기계 번역으로 제공되는 번역입니다. 제공된 번역과 원본 영어의 내용이 상충하는 경우에는 영어 버전이 우선합니다.
TensorBoard에서 Amazon SageMaker Debugger 출력 텐서 시각화하기
중요
이 페이지는 Amazon SageMaker SageMaker SageMaker AI에 더 이상 사용되지 않습니다. TensoBoard TensorBoard 자세한 내용은 Amazon SageMaker AI의 TensorBoard 을 참조하십시오.
SageMaker Debugger를 사용하여 TensorBoard와 호환되는 출력 텐서 파일을 생성할 수 있습니다. 파일을 로드하여 TensorBoard에서 시각화하고 SageMaker 훈련 작업을 분석할 수 있습니다. Debugger는 TensorBoard와 호환되는 출력 텐서 파일을 자동으로 생성합니다. 출력 텐서를 저장하기 위해 사용자 지정하는 모든 후크 구성에 대해 Debugger는 TensorBoard로 가져올 수 있는 스칼라 요약, 분포, 히스토그램에 대한 유연성을 갖추고 있습니다.
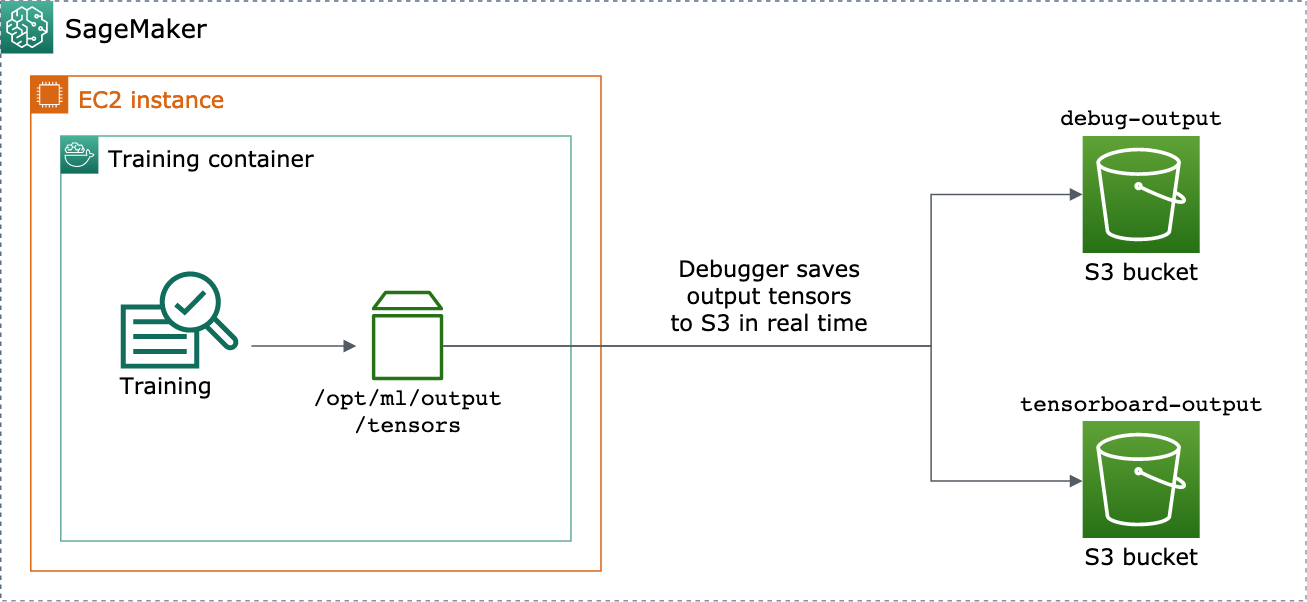
estimator에 DebuggerHookConfig 및 TensorBoardOutputConfig 객체를 전달하여 이를 활성화할 수 있습니다.
다음 절차는 스칼라, 가중치 및 편향을 TensorBoard로 시각화할 수 있는 전체 텐서, 히스토그램 및 분포로 저장하는 방법을 설명합니다. Debugger는 이를 훈련 컨테이너의 로컬 경로(기본 경로는 /opt/ml/output/tensors)에 저장하고 Debugger 출력 구성 객체를 통해 전달된 Amazon S3 위치에 동기화합니다.
Debugger를 사용하여 TensorBoard 호환 출력 텐서 파일을 저장하려면
-
Debugger
TensorBoardOutputConfig클래스를 사용하여 TensorBoard 출력을 저장하도록tensorboard_output_config구성 객체를 설정합니다.s3_output_path파라미터에 현재 SageMaker AI 세션의 기본 S3 버킷 또는 기본 S3 버킷을 지정합니다. SageMaker 이 예제에서는container_local_output_path파라미터를 추가하지 않고 대신 기본 로컬 경로/opt/ml/output/tensors로 설정합니다.import sagemaker from sagemaker.debugger import TensorBoardOutputConfig bucket = sagemaker.Session().default_bucket() tensorboard_output_config = TensorBoardOutputConfig( s3_output_path='s3://{}'.format(bucket) )자세한 내용은 Amazon SageMaker Python SDK
의 Debugger TensorBoardOutputConfigAPI를 참고하세요. -
Debugger 후크를 구성하고 후크 파라미터 값을 사용자 지정합니다. 예를 들어, 다음 코드는 훈련 단계에서는 100단계마다, 검증 단계에서는 10단계마다 모든 스칼라 출력을 저장하고,
weights파라미터는 500단계마다(텐서 컬렉션을 저장하는 기본save_interval값은 500), 글로벌 단계가 500에 도달할 때까지 10개의 글로벌 단계마다bias파라미터를 저장하도록 Debugger 후크를 구성합니다.from sagemaker.debugger import CollectionConfig, DebuggerHookConfig hook_config = DebuggerHookConfig( hook_parameters={ "train.save_interval": "100", "eval.save_interval": "10" }, collection_configs=[ CollectionConfig("weights"), CollectionConfig( name="biases", parameters={ "save_interval": "10", "end_step": "500", "save_histogram": "True" } ), ] )Debugger 구성 API에 대한 자세한 내용은 Amazon SageMaker Python SDK
의 Debugger CollectionConfig및DebuggerHookConfigAPI를 참고하세요. -
구성 객체를 전달하는 Debugger 파라미터를 사용하여 SageMaker AI 예측기를 구성합니다. 다음 예제 템플릿은 일반 SageMaker AI 예측기를 생성하는 방법을 보여줍니다.
estimator및를 다른 SageMaker AI 프레임워크의 예측기 상위 클래스 및 예측기 클래스Estimator로 바꿀 수 있습니다. 이 기능에 사용할 수 있는 SageMaker AI 프레임워크 예측기는TensorFlow,PyTorch및 입니다MXNet.from sagemaker.estimatorimportEstimatorestimator =Estimator( ... # Debugger parameters debugger_hook_config=hook_config, tensorboard_output_config=tensorboard_output_config ) estimator.fit()estimator.fit()메서드는 훈련 작업을 시작하고 Debugger는 출력 텐서 파일을 Debugger S3 출력 경로와 TensorBoard S3 출력 경로에 실시간으로 씁니다. 출력 경로를 검색하려면 아래의 예측기 메서드를 사용하세요.-
Debugger S3 출력 경로의 경우,
estimator.latest_job_debugger_artifacts_path()를 사용하세요. -
TensorBoard S3 출력 경로의 경우
estimator.latest_job_tensorboard_artifacts_path()를 사용하세요.
-
-
훈련이 완료되면 저장된 출력 텐서의 이름을 확인합니다.
from smdebug.trials import create_trial trial = create_trial(estimator.latest_job_debugger_artifacts_path()) trial.tensor_names() -
Amazon S3에서 TensorBoard 출력 데이터를 확인합니다.
tensorboard_output_path=estimator.latest_job_tensorboard_artifacts_path() print(tensorboard_output_path) !aws s3 ls {tensorboard_output_path}/ -
TensorBoard 출력 데이터를 노트북 인스턴스에 다운로드합니다. 예를 들어 다음 AWS CLI 명령은 노트북 인스턴스의 현재 작업 디렉터리
/logs/fit아래에 있는에 TensorBoard 파일을 다운로드합니다.!aws s3 cp --recursive {tensorboard_output_path}./logs/fit -
파일 디렉터리를 TAR 파일로 압축하여 로컬 컴퓨터에 다운로드합니다.
!tar -cf logs.tar logs -
Tensorboard TAR 파일을 다운로드하여 장치의 디렉터리에 압축을 풀고, Jupyter notebook 서버를 시작하고, 새 노트북을 열고, TensorBoard 앱을 실행합니다.
!tar -xf logs.tar %load_ext tensorboard %tensorboard --logdir logs/fit
다음 애니메이션 스크린샷은 5~8단계를 보여주는 스크린샷입니다. Debugger TensorBoard TAR 파일을 다운로드하고 로컬 기기의 Jupyter notebook에 파일을 로드하는 방법을 보여줍니다.