기계 번역으로 제공되는 번역입니다. 제공된 번역과 원본 영어의 내용이 상충하는 경우에는 영어 버전이 우선합니다.
Amazon SageMaker Debugger 아키텍처
이 주제에서는 Amazon SageMaker Debugger 워크플로에 대한 고급 개요를 안내합니다.
Debugger는 성능 최적화를 위한 프로파일링 기능을 지원하여 계산 문제(예: 시스템 병목 현상 및 낮은 사용률)를 파악하고, 하드웨어 리소스 사용률을 대규모로 최적화하도록 돕습니다.
Debugger의 모델 최적화를 위한 디버깅 기능은 최적화 알고리즘(예: 경사 하강 및 그 변형)을 이용하여 손실 함수를 최소화하는 동시에 발생 가능한 비수렴 훈련 문제를 분석하는 것입니다.
다음 다이어그램은 SageMaker Debugger의 아키텍처를 나타냅니다. 경계선이 굵은 블록은 Debugger가 훈련 작업 분석 시 관리하는 블록입니다.
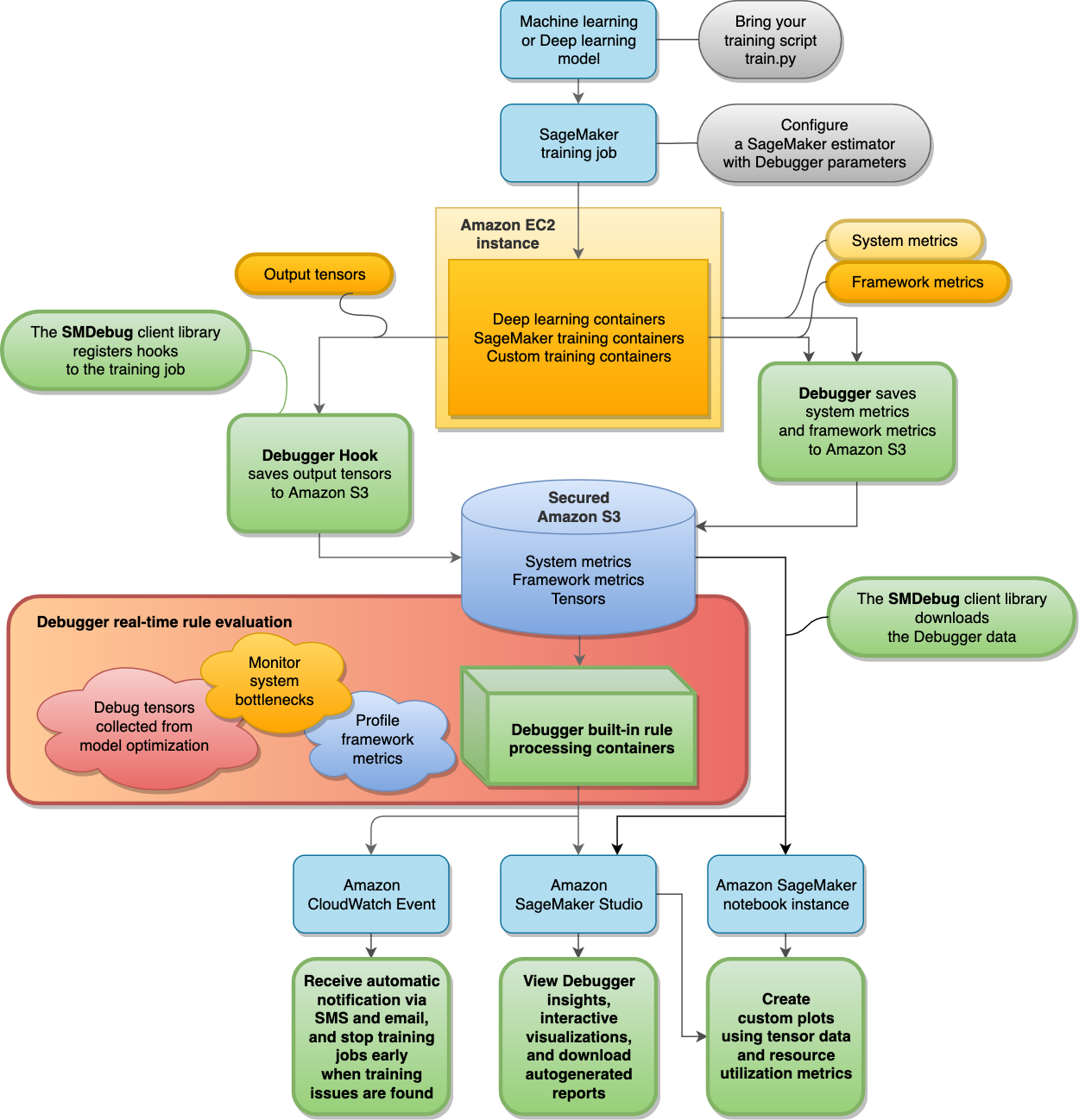
Debugger는 훈련 작업에서 수집된 다음 데이터를 안전한 Amazon S3 버킷에 저장합니다.
-
출력 텐서 - ML 모델을 훈련시키는 동안 순방향 및 역방향 과정에서 지속적으로 업데이트되는 스칼라 및 모델 파라미터의 모음입니다. 출력 텐서로는 스칼라 값(정확도 및 손실)과 매트릭스(가중치, 그라데이션, 입력 계층, 출력 계층) 등이 있습니다.
참고
기본적으로 Debugger는 SageMaker AI 예측기에 구성된 Debugger별 파라미터 없이 SageMaker 훈련 작업을 모니터링하고 디버깅합니다. Debugger는 500밀리초마다 시스템 지표를, 500단계마다 기본 출력 텐서(손실 및 정확도 등의 스칼라 출력)를 수집합니다. 또한
ProfilerReport규칙을 실행하여 시스템 지표를 분석하고 Studio Debugger 인사이트 대시보드와 프로파일링 보고서를 집계합니다. Debugger는 출력 데이터를 안전한 Amazon S3 버킷에 저장합니다.
Debugger 기본 제공 규칙은 처리 컨테이너로 실행됩니다. 이 컨테이너는 S3 버킷에서 수집된 훈련 데이터를 처리하여 기계 학습 모델을 평가하도록 설계되었습니다(데이터 처리 및 모델 평가 참조). 기본 제공 규칙은 Debugger를 통해 완전히 관리됩니다. 모델에 맞게 사용자 지정된 규칙을 자체적으로 생성하여 모니터링할 문제를 감시할 수도 있습니다.
