기계 번역으로 제공되는 번역입니다. 제공된 번역과 원본 영어의 내용이 상충하는 경우에는 영어 버전이 우선합니다.
Debugger 고급 데모 및 시각화
다음 데모에서는 Debugger를 이용한 고급 사용 사례 및 시각화 스크립트를 안내합니다.
주제
Amazon SageMaker Experiments 및 Debugger를 이용한 모델 훈련 및 정리
Nathalie Rauschmayr 박사, AWS 응용 과학자 | 길이: 49분 26초
Amazon SageMaker Experiments 및 Debugger로 훈련 작업 관리를 간소화할 수 있는 방법을 알아보세요. Amazon SageMaker Debugger는 훈련 작업을 투명하게 시각화하고 훈련 지표를 Amazon S3 버킷에 저장합니다. SageMaker Experiments는 사용자가 SageMaker Studio를 통해 훈련 정보를 평가로 호출할 수 있게 하고 훈련 작업의 시각화를 지원합니다. 이렇게 하면 중요도 순위에 따라 중요도가 낮은 파라미터를 줄이면서 모델 품질을 우수하게 유지할 수 있습니다.
이 동영상에서는 모델 정확도에 대한 높은 표준을 유지하면서 사전 훈련된 ResNet50 및 AlexNet 모델을 가볍고 경제적으로 만드는 모델 정리 기법을 보여줍니다.
SageMaker AI 예측기는 PyTorch 프레임워크를 이용하여 AWS 딥 러닝 컨테이너의 PyTorch 모델 Zoo에서 제공되는 알고리즘을 훈련시키며, Debugger는 훈련 프로세스에서 훈련 지표를 추출합니다.
또한이 동영상에서는 정리된 모델의 정확도를 모니터링하고, 정확도가 임계값에 도달하면 Amazon CloudWatch 이벤트와 AWS Lambda 함수를 트리거하고, 중복 반복을 방지하기 위해 정리 프로세스를 자동으로 중지하도록 Debugger 사용자 지정 규칙을 설정하는 방법을 보여줍니다.
학습 목표는 다음과 같습니다.
-
SageMaker AI를 이용하여 ML 모델 훈련을 가속화하고 모델 품질을 개선하는 방법을 알아봅니다.
-
입력 파라미터, 구성 및 결과를 자동으로 캡처하여 SageMaker Experiments를 통해 훈련 반복을 관리하는 방법을 알아보세요.
-
Debugger를 사용해 가중치, 그라데이션, 합성곱 신경망의 활성화 출력 등 여러 지표에서 실시간 텐서 데이터를 자동으로 캡처하여 훈련 프로세스를 투명하게 만드는 방법을 알아보세요.
-
Debugger가 문제를 발견하면 CloudWatch를 사용하여 Lambda를 트리거하세요.
-
SageMaker Experiments 및 Debugger를 사용하여 SageMaker 훈련 프로세스를 마스터하세요.
이 동영상에서 사용된 노트북 및 훈련 스크립트는 SageMaker Debugger PyTorch 반복 모델 정리
다음 이미지는 반복 모델 정리 프로세스를 이용해 활성화 출력 및 그라데이션에 의해 평가된 중요도 순위를 기반으로 중요도가 가장 낮은 100개의 필터를 잘라내어 AlexNet의 크기를 줄이는 방법을 보여줍니다.
정리 프로세스를 통해 초기 5,000만 개의 파라미터가 1,800만 개의 파라미터로 줄어들었습니다. 또한 예상 모델 크기가 201MB에서 73MB로 줄어들었습니다.
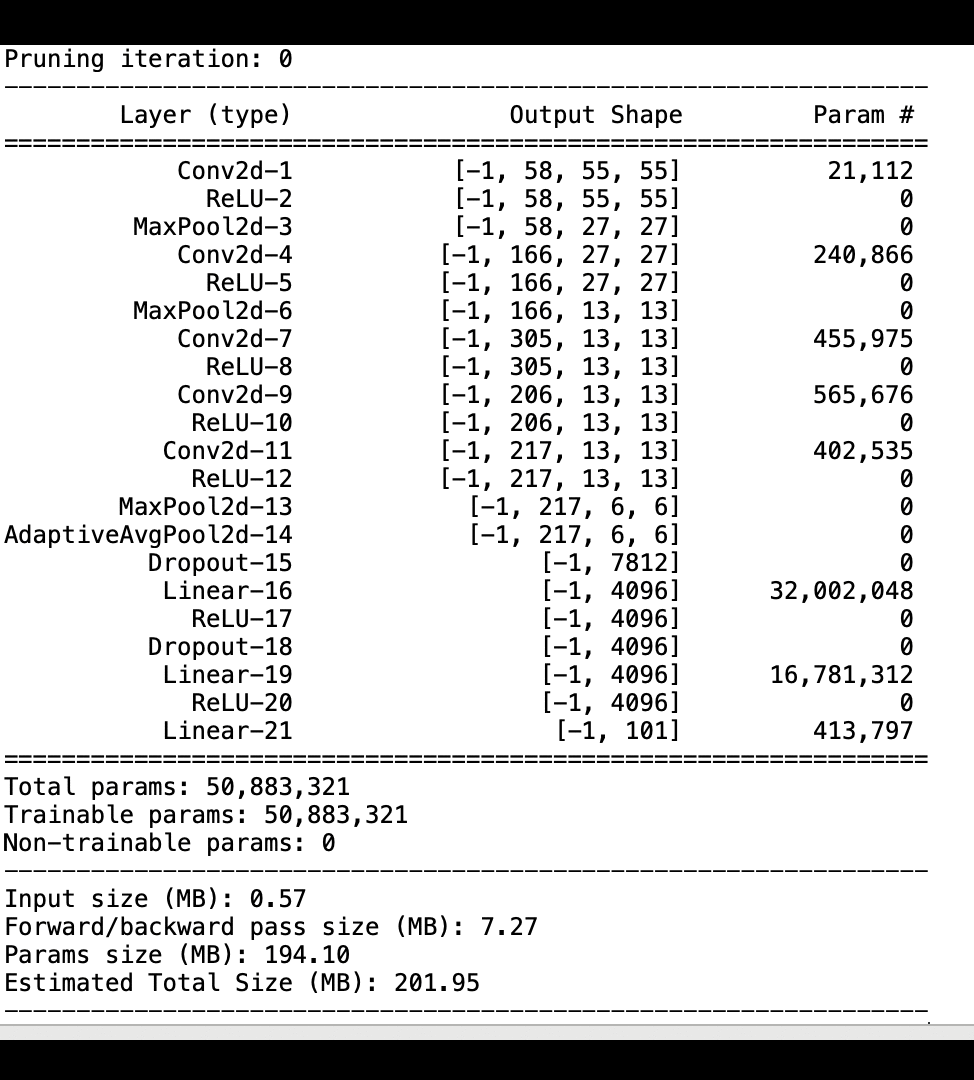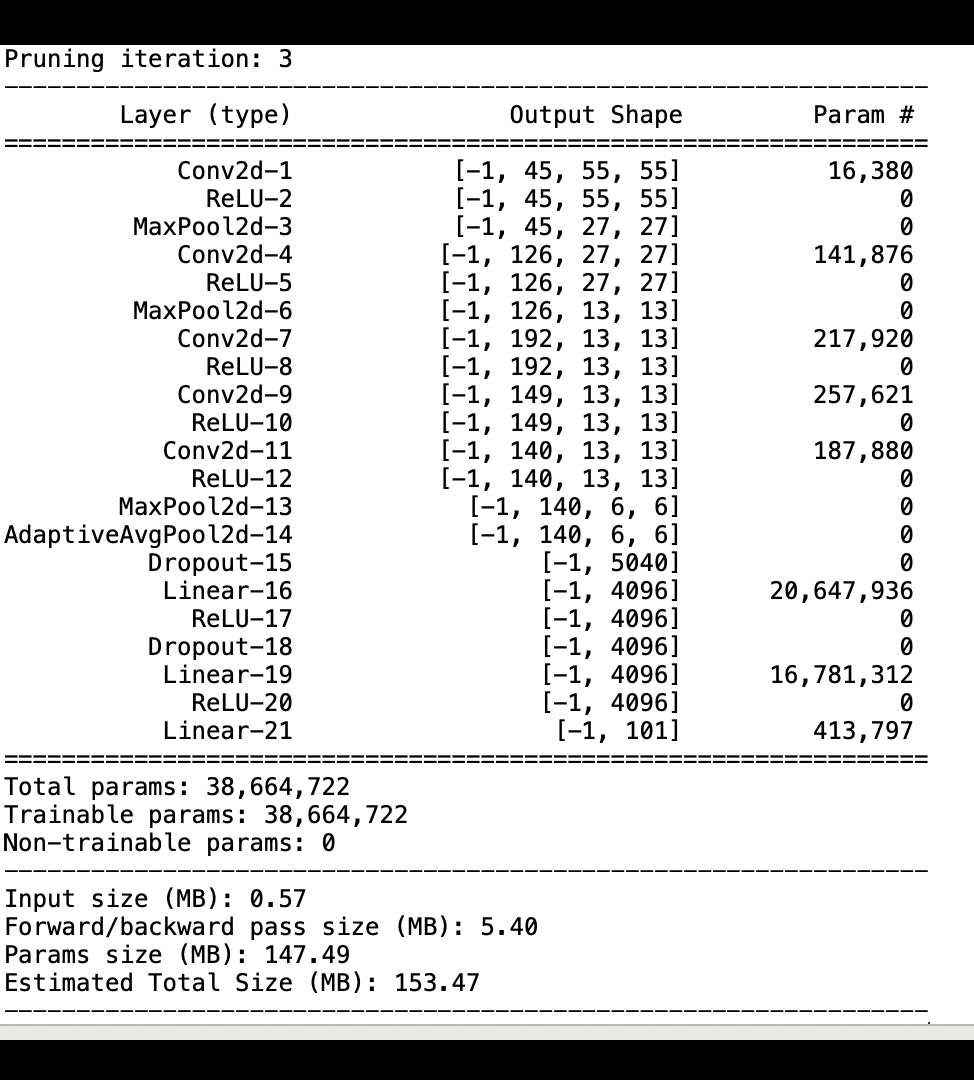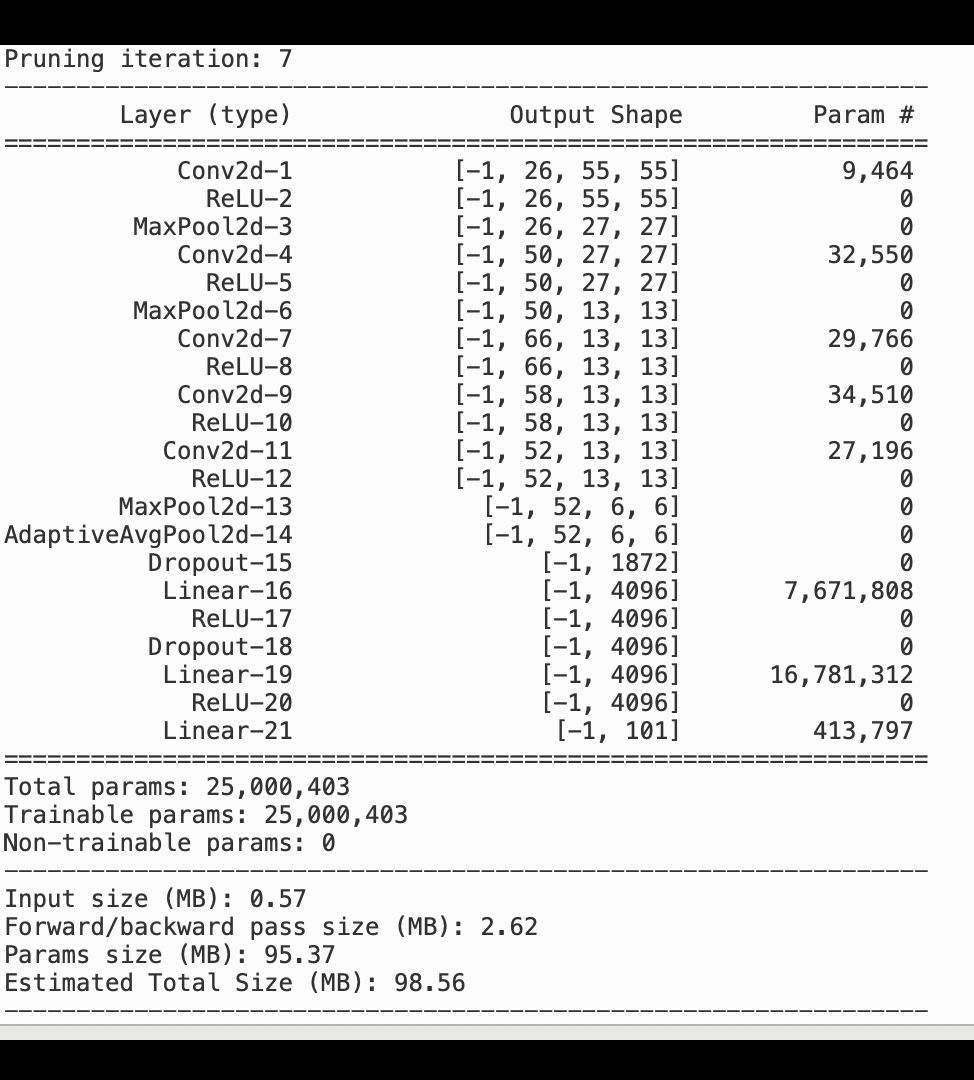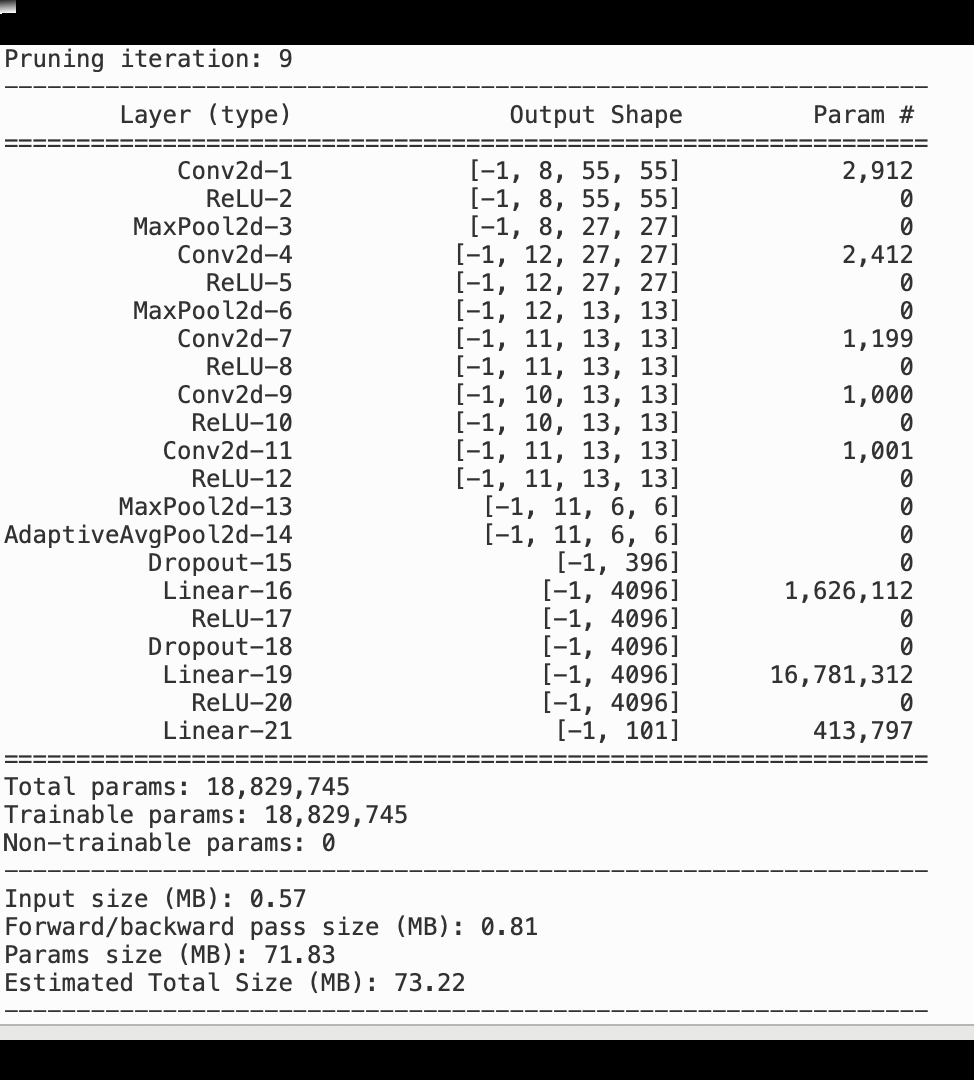
모델 정확도 역시 추적해야 합니다. 다음 이미지는 SageMaker Studio의 파라미터 수에 따라 모델 정확도의 변경사항을 시각화하기 위해 모델 정리 프로세스를 표시하는 방법을 보여줍니다.
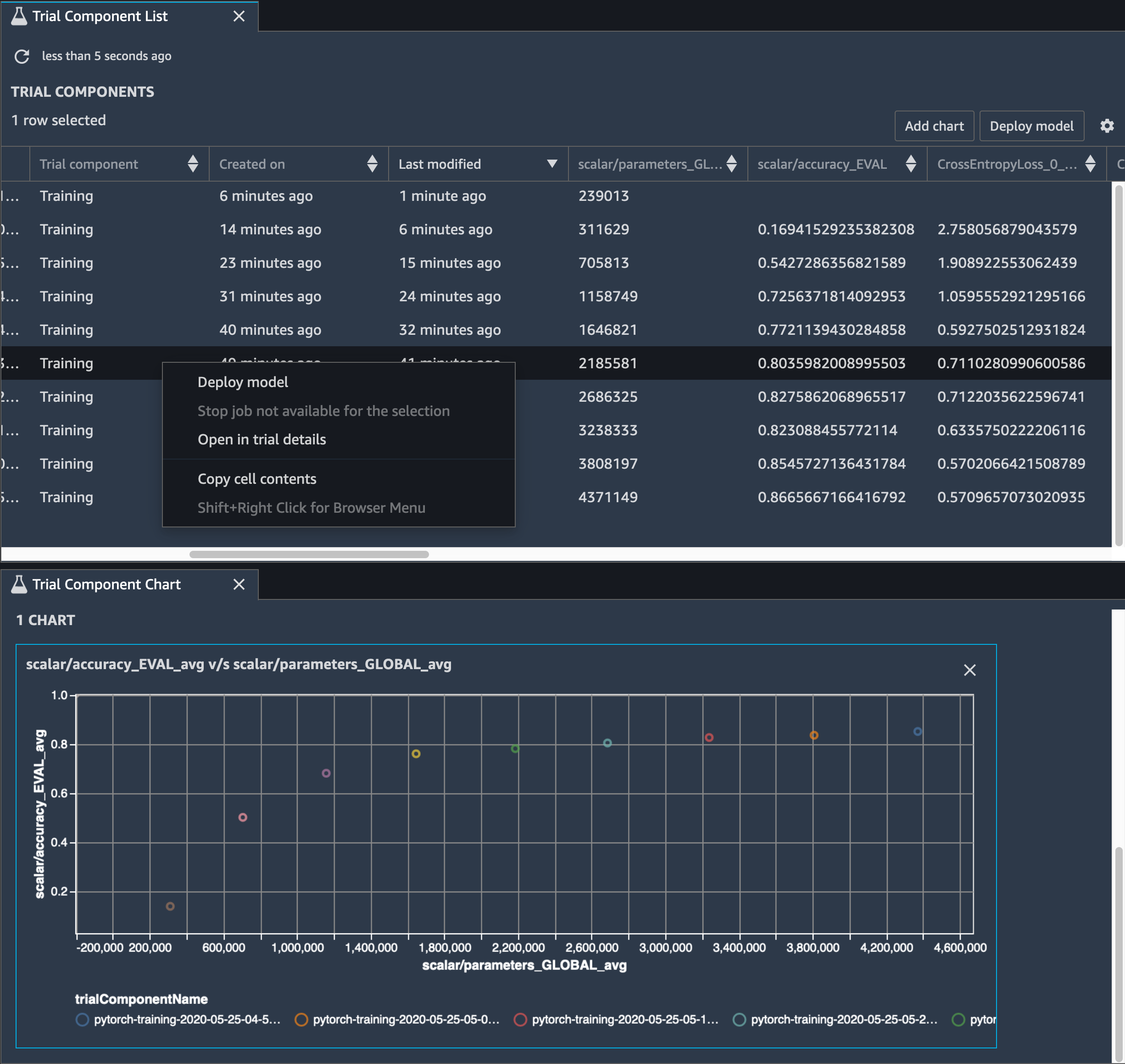
SageMaker Studio에서 실험 탭을 선택하고 Debugger가 정리 프로세스에서 저장한 텐서의 목록을 선택한 다음, 평가 구성 요소 목록 패널을 구성하세요. 반복 10개를 모두 선택한 다음 차트 추가를 선택하여 평가 구성 요소 차트를 생성하세요. 배포할 모델을 결정한 후 평가 구성 요소를 선택하고, 작업을 수행할 메뉴를 선택하거나 모델 배포를 선택하세요.
참고
다음 노트북 예제를 사용하여 SageMaker Studio를 통해 모델을 배포하려면 train.py 스크립트의 train 함수 끝 부분에 한 줄을 추가하세요.
# In the train.py script, look for the train function in line 58. def train(epochs, batch_size, learning_rate): ... print('acc:{:.4f}'.format(correct/total)) hook.save_scalar("accuracy", correct/total, sm_metric=True) # Add the following code to line 128 of the train.py script to save the pruned models # under the current SageMaker Studio model directorytorch.save(model.state_dict(), os.environ['SM_MODEL_DIR'] + '/model.pt')
SageMaker Debugger를 사용하여 컨볼루션 자동 인코더 모델 훈련 모니터링
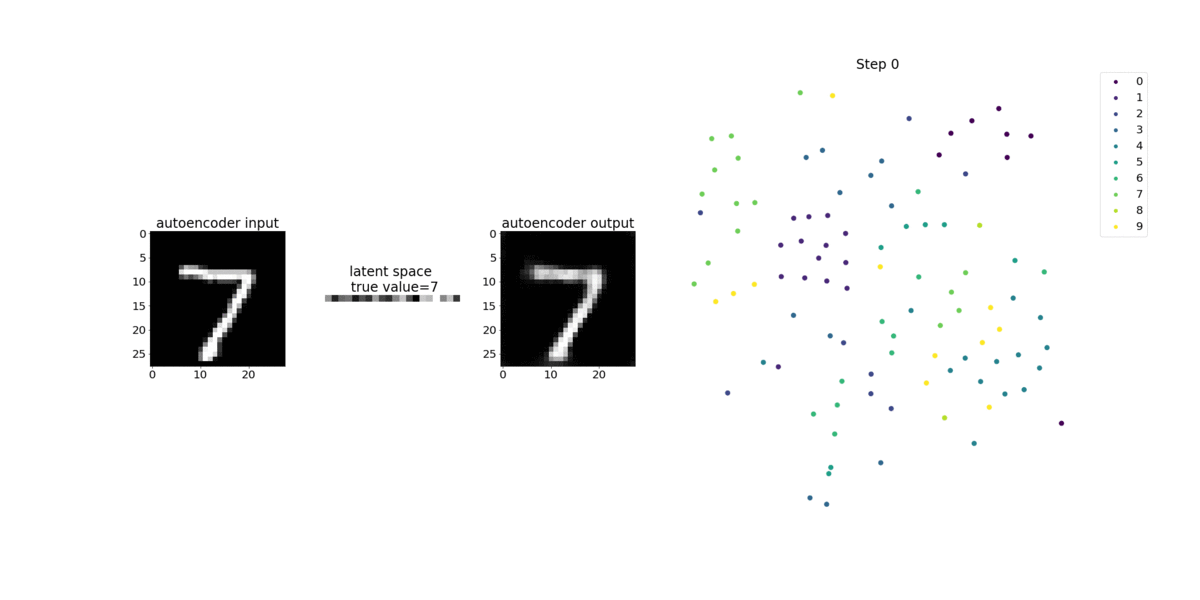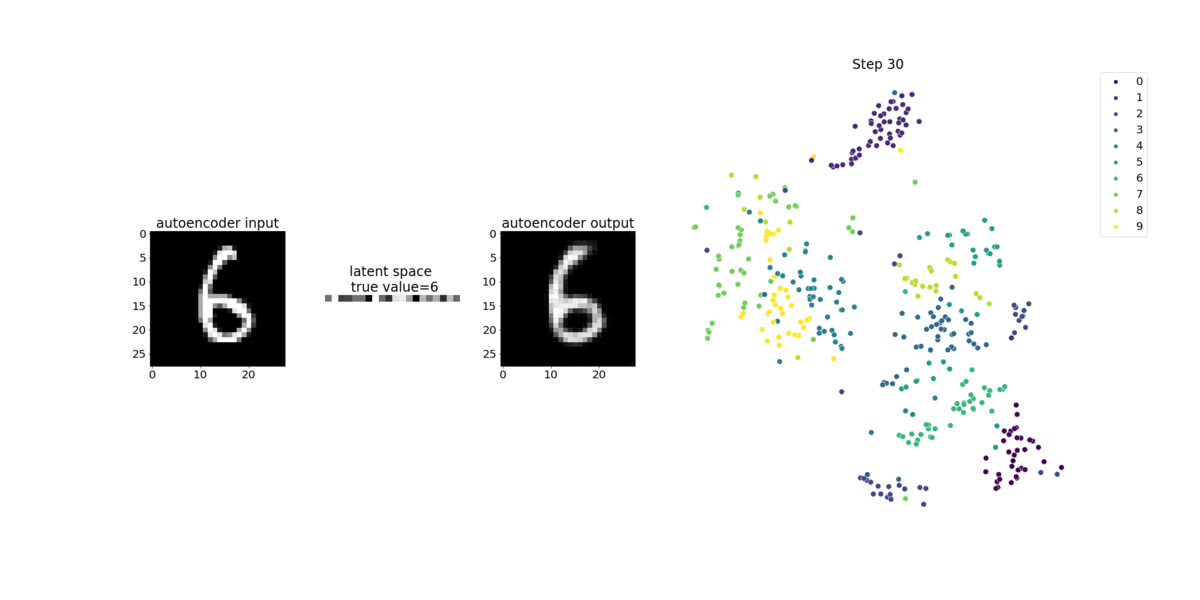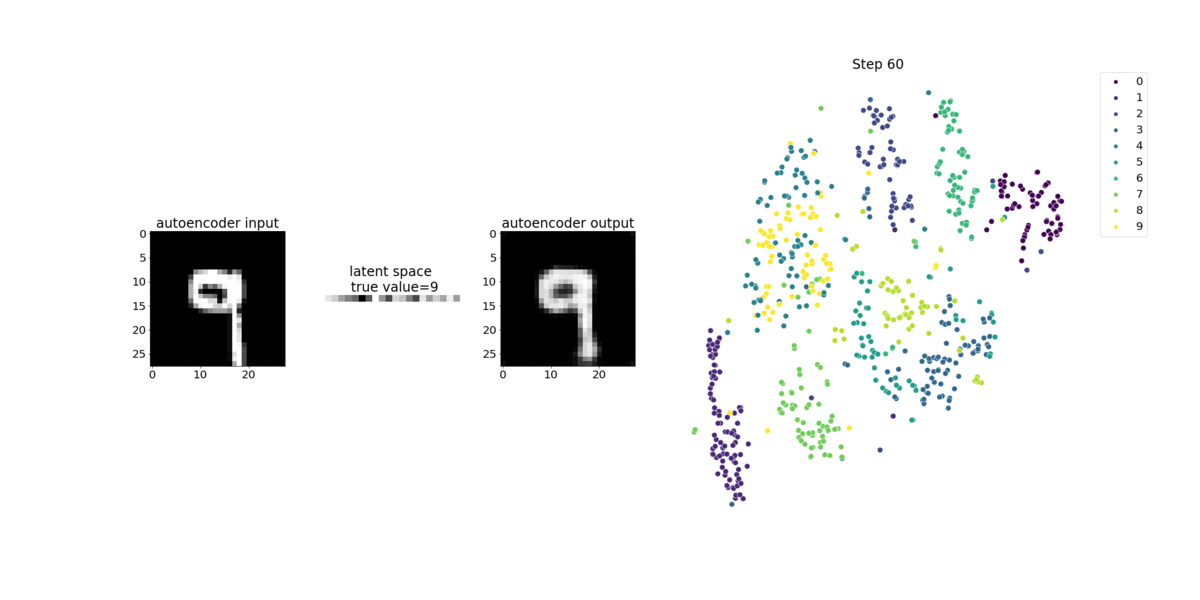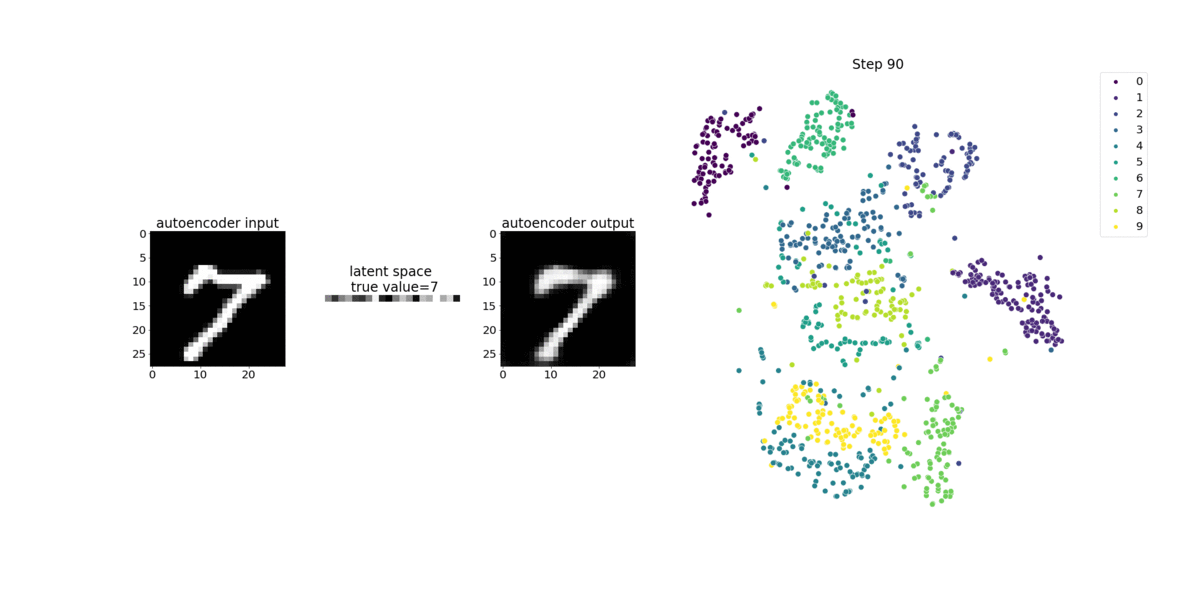
이 노트북은 SageMaker Debugger가 수기로 쓴 숫자로 구성된 MNIST 이미지 데이터세트에서 감독되지 않은(또는 자체 감독된) 학습 프로세스의 텐서를 시각화하는 방법을 보여줍니다.
이 노트북의 훈련 모델은 MXNet 프레임워크가있는 컨볼루션 자동 인코더입니다. 컨볼루션 자동 인코더에는 인코더 부분과 디코더 부분으로 구성된 병목 모양의 컨볼루션 신경망이 있습니다.
이 예제의 인코더에는 입력 이미지의 압축 표현(잠재적 변수)을 생성하는 두 개의 컨볼루션 계층이 있습니다. 이 경우 인코더는 원래 입력 이미지 크기(28, 28)에서 크기(1, 20)의 잠재적 변수를 생성하고 훈련을 위해 데이터 크기를 40배까지 크게 줄입니다.
디코더는 두 개의 디컨볼루션 계층을 포함하고 있으며 잠재적 변수가 출력 이미지를 재구성하여 주요 정보를 유지하도록 보장합니다.
합성곱 인코더는 입력 데이터 크기가 작은 클러스터링 알고리즘을 가동시키고 k-means, k-NN, t-SNE(t-Distributed Stochastic Neighbor Embedding) 등 여러 클러스터링 알고리즘의 성능을 구현합니다.
이 노트북 예제에서는 다음 애니메이션과 같이 Debugger를 사용하여 잠재적 변수를 시각화하는 방법을 보여줍니다. 또한 t-SNE 알고리즘이 잠재적 변수를 10개의 클러스터로 분류하여 2차원 공간으로 투영하는 방법을 보여줍니다. 이미지 오른쪽의 산점도 색 구성표는 실제 값을 반영하여 BERT 모델 및 t-SNE 알고리즘이 잠재적 변수를 클러스터에 얼마나 잘 구성하는지를 보여줍니다.
SageMaker Debugger를 사용하여 BERT 모델 훈련에서 주의 모니터링
BERT(Bidirectional Encode Representations from Transformers)는 언어 표현 모델입니다. 모델 이름이 나타내는 바와 같이 BERT 모델은 NLP(자연어 처리)를 위해 전이 학습 및 변환기 모델을 바탕으로 빌드됩니다.
BERT 모델은 문장에서 누락된 단어를 예측하거나 이전 문장을 자연스럽게 따르는 다음 문장을 예측하는 것과 같이 감독되지 않은 작업에 대한 사전 훈련을 받습니다. 훈련 데이터에는 Wikipedia, 전자 서적 등의 출처에서 발췌한 영어 텍스트 33억 단어(토큰)가 포함되어 있습니다. 간단한 예를 들어, BERT 모델은 주제 토큰의 적절한 동사 토큰 또는 대명사 토큰에 높은 어텐션을 지정할 수 있습니다.
사전 훈련된 BERT 모델을 추가 출력 계층으로 미세 조정하면 질문에 대한 자동 응답, 텍스트 분류 및 기타 여러 가지 NLP 작업의 최첨단 모델 훈련을 달성할 수 있습니다.
Debugger는 미세 조정 프로세스에서 텐서를 수집합니다. NLP의 컨텍스트에서는 뉴런의 가중치를 어텐션이라고 합니다.
이 노트북은 Stanford Question and Answering 데이터세트의 GluonNLP 모델 Zoo에서 사전 훈련된 BERT 모델
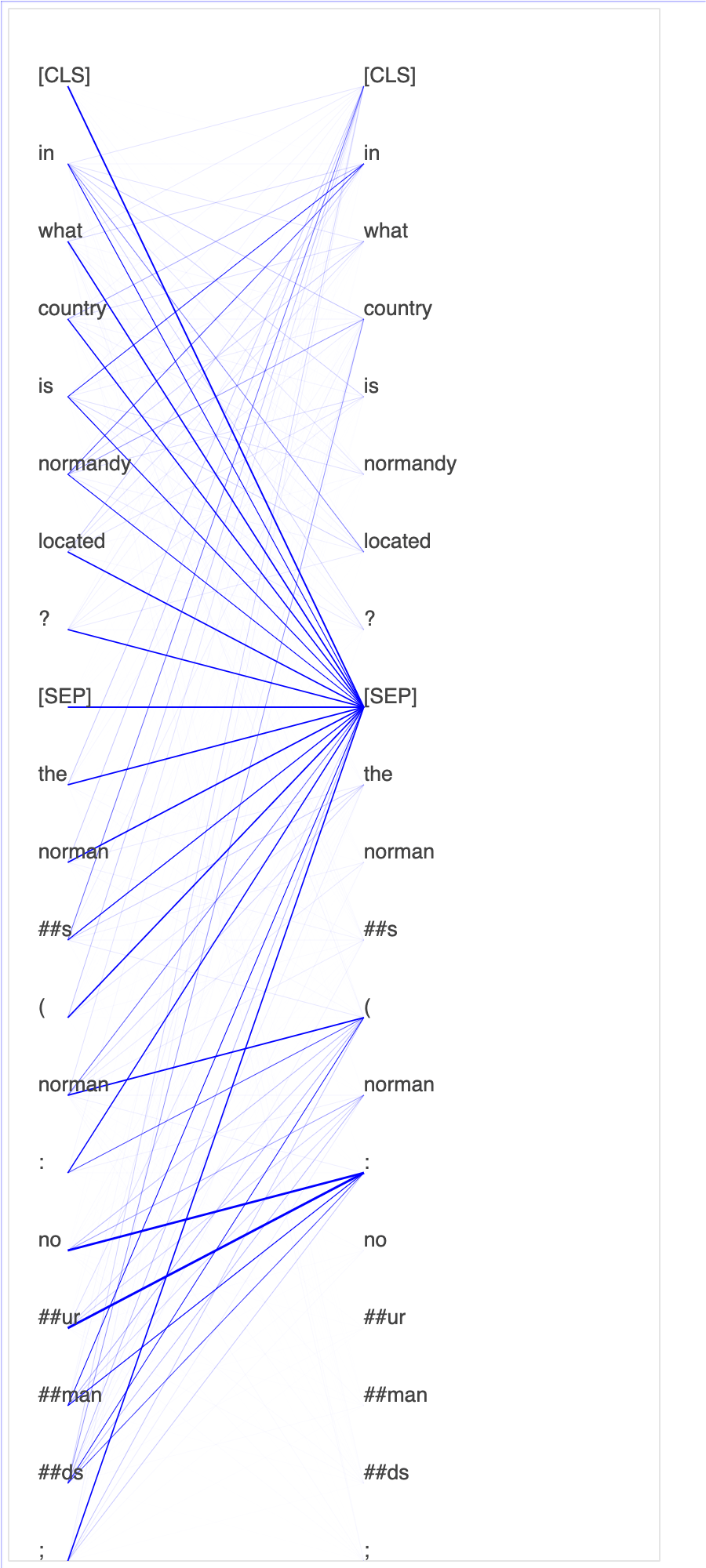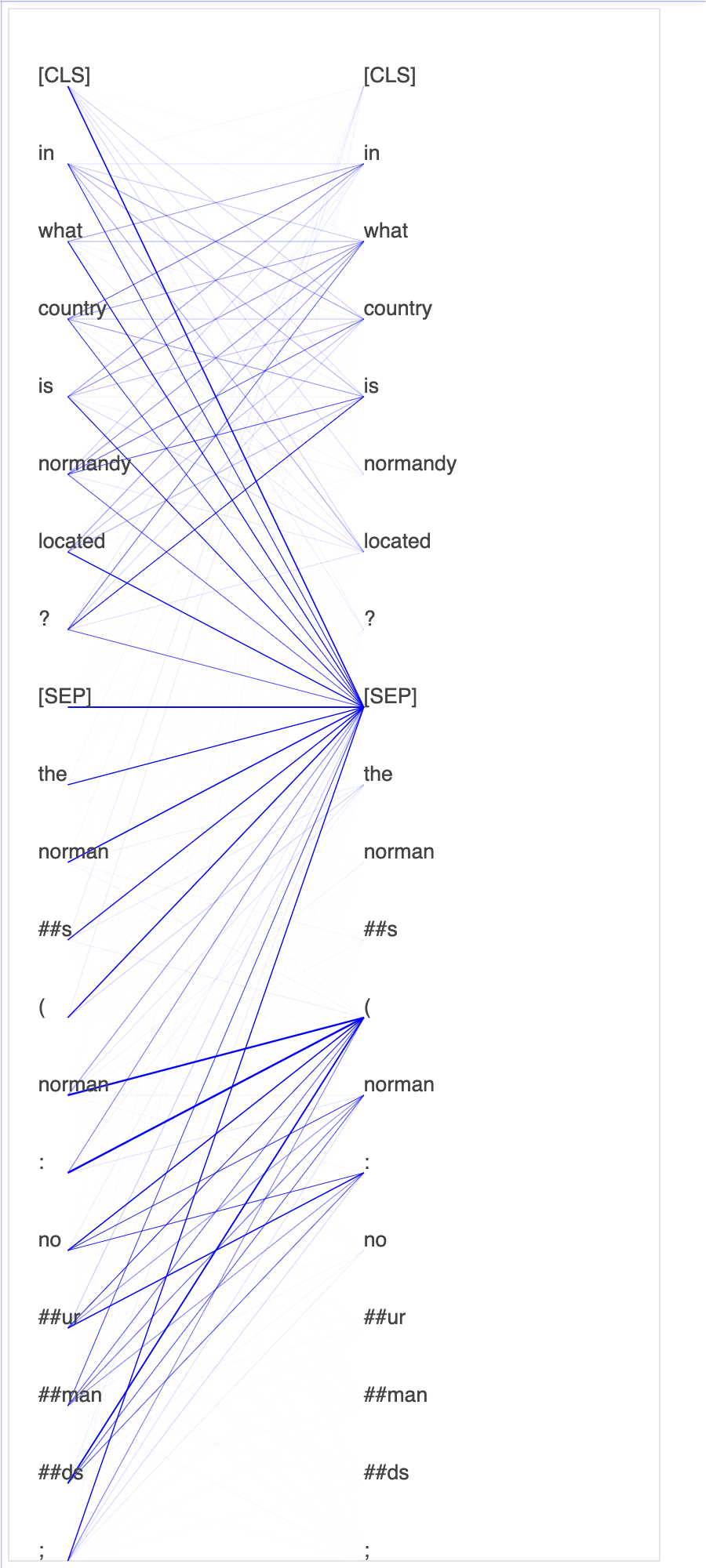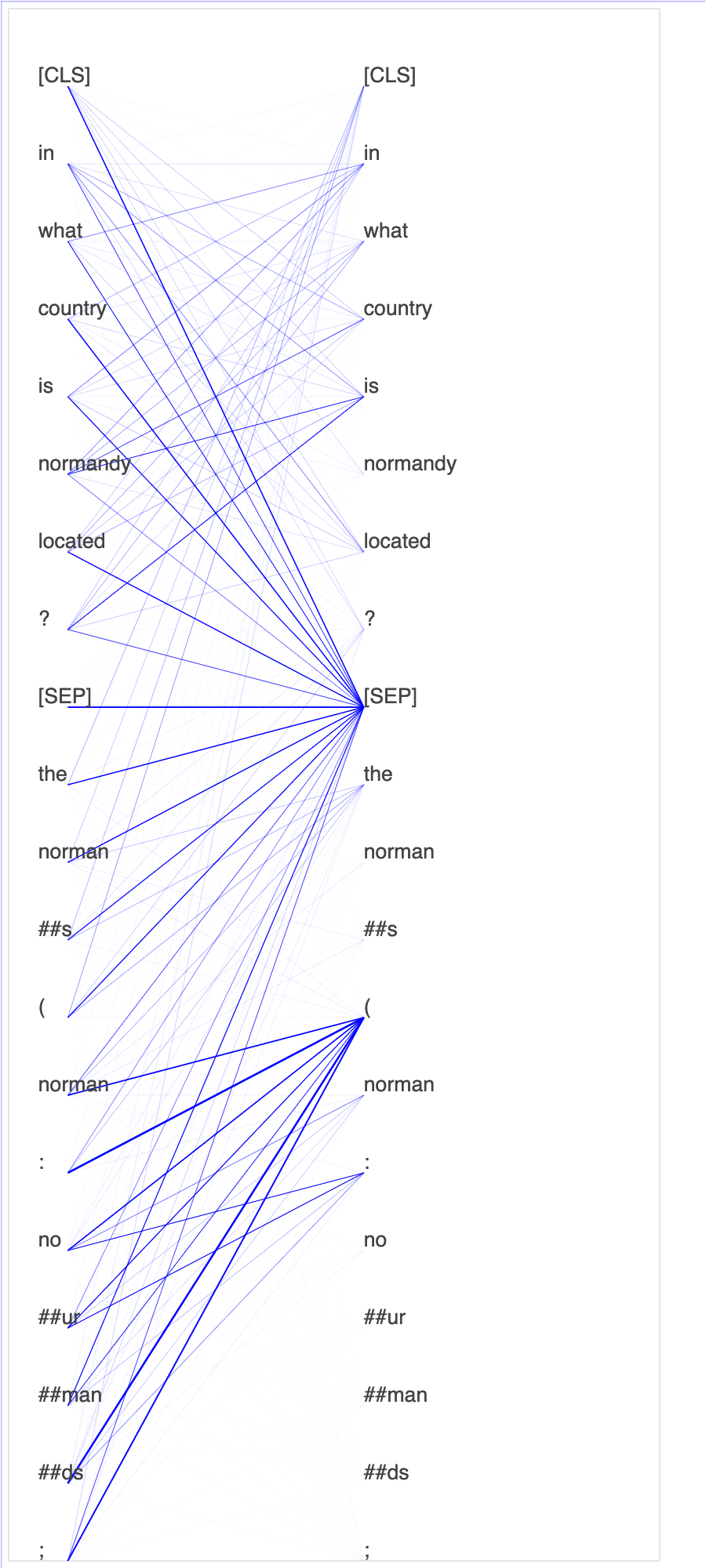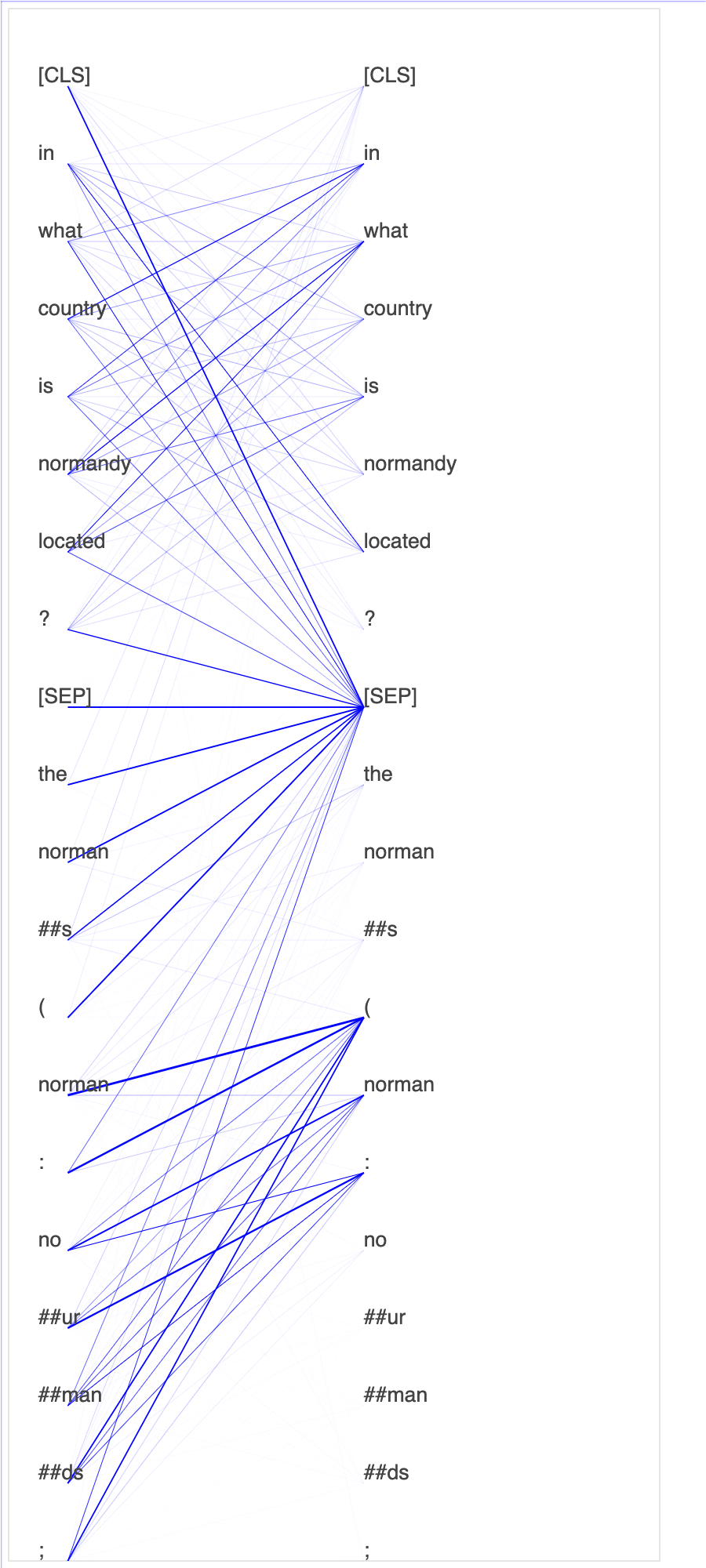
쿼리 및 주요 벡터에 어텐션 점수 및 개별 뉴런을 표시하면 잘못된 모델 예측의 원인을 식별하는 데 도움이 될 수 있습니다. SageMaker AI Debugger를 사용하면 텐서를 검색하고, 훈련이 진행됨에 따라 실시간으로 어텐션 헤드 뷰를 표시하며, 모델이 학습하는 내용을 파악할 수 있습니다.
다음 애니메이션은 노트북 예제에 제공된 훈련 작업에서 10회 반복에 대해 처음 20개 입력 토큰의 어텐션 점수를 보여줍니다.
SageMaker Debugger를 사용하여 컨볼루션 신경망(CNNs)에서 클래스 활성화 맵 시각화
이 노트북은 SageMaker Debugger를 사용하여 합성곱 신경망(CNN)의 이미지 감지 및 분류를 위해 클래스 활성화 맵을 표시하는 방법을 보여줍니다. 딥 러닝에서 합성곱 신경망(CNN 또는 ConvNet)은 일종의 심층 신경망을 가리키며, 시각적 이미지 분석에 가장 흔하게 적용됩니다. 클래스 활성화 맵을 채택한 애플리케이션 중 하나가 바로 자율주행 자동차입니다. 이 애플리케이션에서는 교통 표지판, 도로, 장애물 등의 이미지를 즉각적으로 감지하고 분류해야 합니다.
이 노트북에서 PyTorch ResNet 모델은 40개 이상의 교통 관련 물체와 총 50,000개 이상의 이미지가 포함된 독일 교통 표지 데이터세트
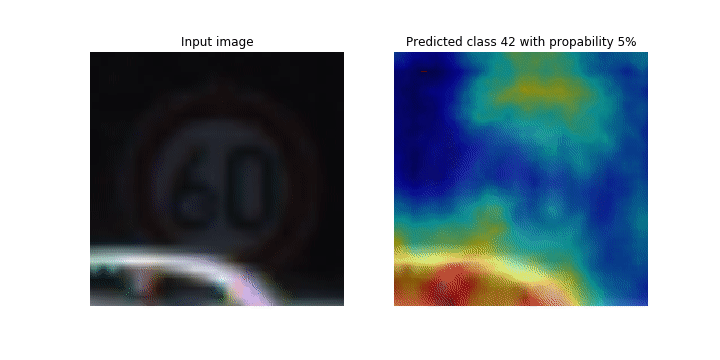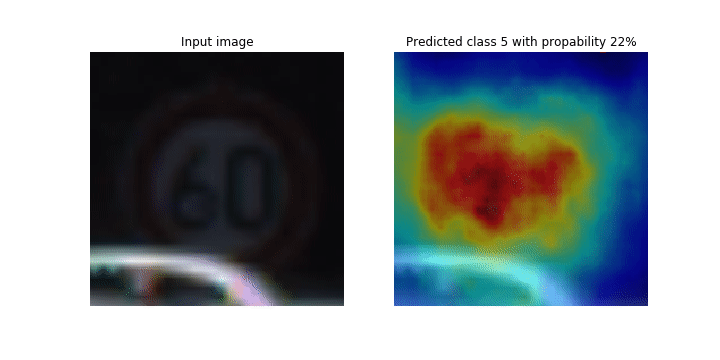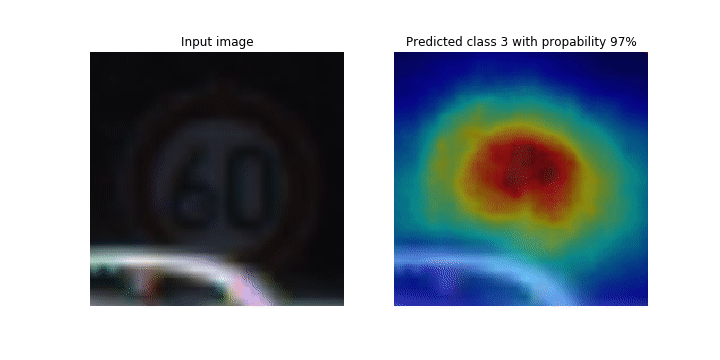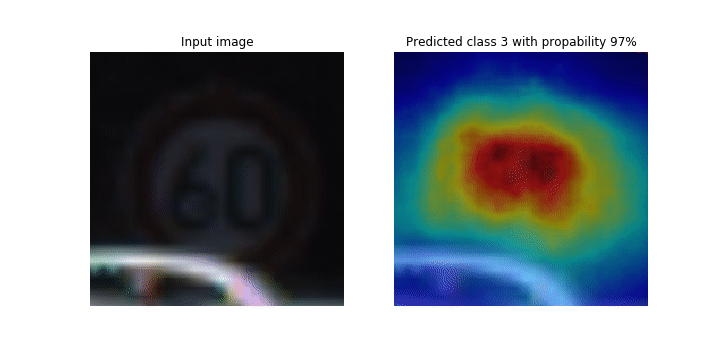
훈련 프로세스가 진행되는 동안 SageMaker Debugger가 텐서를 수집하여 클래스 활성화 맵을 실시간으로 표시합니다. 애니메이션 이미지에서와 같이 클래스 활성화 맵(Saliency 맵이라고도 함)은 활성화가 높은 영역을 빨간색으로 강조 표시합니다.
Debugger가 캡처한 텐서를 사용하여 모델 훈련 중에 활성화 맵이 어떻게 진화하는지를 시각화할 수 있습니다. 이 모델은 훈련 작업 시작 시 왼쪽 하단 모서리의 엣지를 감지하는 것으로 시작됩니다. 훈련이 진행됨에 따라 초점이 중심으로 이동하고 속도 제한 기호를 감지하며 모델은 97%의 신뢰도 수준으로 Class 3(60km/h 속도 제한 표지 클래스)으로 입력 이미지를 성공적으로 예측합니다.
