기계 번역으로 제공되는 번역입니다. 제공된 번역과 원본 영어의 내용이 상충하는 경우에는 영어 버전이 우선합니다.
Factorization Machine 작동 방법
Factorization Machines 모델의 예측 작업은 기능 세트 xi에서 대상 도메인까지 함수 ŷ를 추정하는 것입니다. 이 도메인은 회귀의 경우 실제 값이고 분류의 경우 바이너리입니다. Factorization Machine 모델은 감독되므로 사용 가능한 훈련 데이터세트 (xi,yj)가 있습니다. 이 모델의 이점은 인수분해된 파라미터화를 사용하여 쌍으로 이루어지는 특징 상호 작용을 캡처하는 방식에 있습니다. 이는 다음과 같은 수학 공식으로 나타낼 수 있습니다.
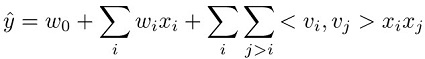
이 방정식의 3개 항은 각각 모델 구성 요소 3개에 해당합니다.
-
w0 항은 전역 편향을 나타냅니다.
-
wi 선형항은 i번째 변수의 강도를 모델링합니다.
-
<vi,vj> 인수분해 항은 i번째와 j번째 변수 간 쌍별 상호 작용을 모델링합니다.
전역 편향 및 선형항은 선형 모델에서와 동일합니다. 쌍별 특징 상호 작용은 각 특징에 대해 학습된 해당 인수의 내적으로 세 번째 항에서 모델링됩니다. 학습된 팩터는 각 특징에 대한 임베딩 벡터로 고려될 수 있습니다. 예를 들어 분류 작업에서 한 쌍의 기능이 정상 샘플에서 더욱 자주 동시에 발생하는 편인 경우 이러한 팩터의 내적은 클 것입니다. 다시 말해 임베딩 벡터는 코사인 유사도에 있는 각각과 근접합니다. Factorization Machine 모델에 대한 자세한 정보는 Factorization Machines
회귀 작업의 경우 모델 예측 ŷn 및 대상 값 yn 사이의 제곱근 오차를 최소화함으로써 모델을 훈련합니다. 이를 제곱 손실이라고 합니다.
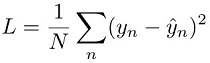
분류 작업의 경우 모델은 교차 엔트로피 손실(로그 손실이라고도 함)을 최소화함으로써 훈련됩니다.

여기서 각 항목은 다음과 같습니다.

분류용 손실 함수에 대한 자세한 정보는 Loss functions for classification
