기계 번역으로 제공되는 번역입니다. 제공된 번역과 원본 영어의 내용이 상충하는 경우에는 영어 버전이 우선합니다.
샤딩된 데이터 병렬 처리
샤딩된 데이터 병렬 처리는 데이터 병렬 그룹 내 GPU의 모델 상태(모델 파라미터, 그라디언트 및 옵티마이저 상태)를 분할하는 메모리 절약형 분산 훈련 기법입니다.
참고
샤딩된 데이터 병렬 처리는 SageMaker 모델 병렬 처리 라이브러리 v1.11.0 이상에서 PyTorch에 사용할 수 있습니다.
훈련 작업을 대규모 GPU 클러스터로 확장할 때 여러 GPU에서 모델의 훈련 상태를 샤딩하여 모델의 GPU당 메모리 사용량을 줄일 수 있습니다. 두 가지 이점은 다음과 같습니다. 표준 데이터 병렬 처리로는 메모리 부족이 발생할 수도 있는 더 큰 모델에 맞추거나 확보된 GPU 메모리를 사용하여 배치 크기를 늘릴 수 있다는 것입니다.
표준 데이터 병렬 처리 기법은 데이터 병렬 그룹의 GPU에서 훈련 상태를 복제하고 AllReduce 연산을 기반으로 그라디언트 집계를 수행합니다. 샤딩된 데이터 병렬 처리는 옵티마이저 상태의 샤딩 특성을 고려하여 표준 데이터 병렬 분산 훈련 절차를 수정합니다. 모델과 옵티마이저 상태가 샤딩되는 순위 그룹을 샤딩 그룹이라고 합니다. 샤딩된 데이터 병렬 처리 기법은 샤딩 그룹의 GPU에서 모델의 훈련 가능한 파라미터와 이에 상응하는 그라디언트 및 옵티마이저 상태를 샤딩합니다.
SageMaker AI는 MiCS 구현을 통해 샤딩된 데이터 병렬화를 달성합니다. MiCS 구현은 블로그 AWS 게시물에 거대 모델 훈련의 거의 선형적인 조정에 대해 설명되어 있습니다. AWSAllGather 작업을 통해 모든 GPU의 모델 파라미터를 일시적으로 재결합합니다. 각 레이어의 순방향 또는 역방향 패스 후 MiCS는 파라미터를 다시 분할하여 GPU 메모리를 절약합니다. 역방향 통과 중에 MiCS는 그라디언트를 줄이고 동시에 ReduceScatter 작업을 통해 GPU 전체에 샤딩합니다. 마지막으로 MiCS는 옵티마이저 상태의 로컬 샤드를 사용하여 축소 및 샤딩된 로컬 그라디언트를 해당 로컬 파라미터 샤드에 적용합니다. 통신 오버헤드를 줄이기 위해 SageMaker 모델 병렬 처리 라이브러리는 순방향 또는 역방향 패스에서 다음 레이어를 미리 가져오고 네트워크 통신을 계산과 중첩합니다.
모델의 훈련 상태는 샤딩 그룹 전체에 복제됩니다. 즉, 파라미터에 그라디언트를 적용하기 전에 샤딩 그룹 내에서 수행되는 ReduceScatter 작업 외에도 샤딩 그룹 전체에서 AllReduce 작업이 수행되어야 합니다.
실제로 샤딩된 데이터 병렬 처리는 통신 오버헤드와 GPU 메모리 효율성 간의 균형을 맞춥니다. 샤딩된 데이터 병렬 처리를 사용하면 통신 비용이 증가하지만 GPU당 메모리 사용량(활성화로 인한 메모리 사용량 제외)을 샤딩된 데이터 병렬 처리 수준으로 나누므로 더 큰 모델을 GPU 클러스터에 맞출 수 있습니다.
샤딩된 데이터 병렬도 선택
분할된 데이터 병렬도 값을 선택할 때는 값이 데이터 병렬도를 균등하게 나누어야 합니다. 예를 들어 8방향 데이터 병렬 처리 작업의 경우 샤딩된 데이터 병렬도 등급으로 2, 4 또는 8을 선택합니다. 샤딩된 데이터 병렬도를 선택할 때는 적은 수로 시작하여 모델이 메모리 및 배치 크기에 맞을 때까지 점진적으로 늘리는 것이 좋습니다.
배치 크기 선택
샤딩된 데이터 병렬 처리를 설정한 후에는 GPU 클러스터에서 성공적으로 실행할 수 있는 최적의 훈련 구성을 찾아야 합니다. 대규모 언어 모델(LLM)을 훈련시키려면 배치 크기 1부터 시작한 다음, 메모리 부족(OOM) 오류가 발생할 때까지 배치 크기를 점차 늘립니다. 배치 크기가 가장 작더라도 OOM 오류가 발생하는 경우 더 높은 수준의 샤딩된 데이터 병렬 처리를 적용하거나 샤딩된 데이터 병렬 처리 및 텐서 병렬 처리를 조합하여 적용합니다.
주제
샤딩된 데이터 병렬 처리를 훈련 작업에 적용하는 방법
샤딩된 데이터 병렬 처리를 시작하려면 훈련 스크립트에 필요한 수정 사항을 적용하고 샤딩된 데이터 병렬 처리 관련 파라미터를 사용하여 SageMaker PyTorch 예측기를 설정합니다. 참조 값 및 예제 노트북을 시작점으로 사용하는 것도 고려해 봅니다.
PyTorch 훈련 스크립트 조정
1단계: PyTorch 훈련 스크립트 수정의 지침을 따라 torch.nn.parallel 및 torch.distributed 모듈의 smdistributed.modelparallel.torch 래퍼를 사용해 모델 및 옵티마이저 객체를 래핑합니다.
(선택 사항)외부 모델 파라미터를 등록하기 위한 추가 수정
모델이 torch.nn.Module로 구축되고 모듈 클래스 내에 정의되지 않은 파라미터를 사용할 경우 SMP가 전체 파라미터를 수집할 수 있도록 이를 모듈에 수동 등록해야 합니다. 파라미터를 모듈에 등록하려면 smp.register_parameter(module,
parameter)를 사용합니다.
class Module(torch.nn.Module): def __init__(self, *args): super().__init__(self, *args) self.layer1 = Layer1() self.layer2 = Layer2() smp.register_parameter(self, self.layer1.weight) def forward(self, input): x = self.layer1(input) # self.layer1.weight is required by self.layer2.forward y = self.layer2(x, self.layer1.weight) return y
SageMaker PyTorch 예측기 설정
2단계: SageMaker Python SDK를 사용하여 훈련 작업 시작에서 SageMaker PyTorch 예측기를 구성할 때 샤딩된 데이터 병렬 처리용 파라미터를 추가합니다.
샤딩된 데이터 병렬 처리를 켜려면 SageMaker PyTorch 예측기에 sharded_data_parallel_degree 파라미터를 추가합니다. 이 파라미터는 훈련 상태가 샤딩되는 GPU의 수를 지정합니다. sharded_data_parallel_degree 값은 1과 데이터 병렬도 사이의 정수여야 하며 데이터 병렬도를 균등하게 나누어야 합니다. 라이브러리는 GPU 수를 자동으로 감지하므로 데이터 병렬도도 감지합니다. 샤딩된 데이터 병렬 처리를 구성하는 데 다음과 같은 추가 파라미터를 사용할 수 있습니다.
-
"sdp_reduce_bucket_size"(int, default: 5e8) – PyTorch DDP 그라디언트 버킷의 크기를 기본 dtype의 요소 수로 지정합니다. -
"sdp_param_persistence_threshold"(int, default: 1e6) – 파라미터 텐서의 크기를 각 GPU에서 지속될 수 있는 요소 수로 지정합니다. 샤딩된 데이터 병렬 처리는 데이터 병렬 그룹의 GPU에 각 파라미터 텐서를 분할합니다. 파라미터 텐서의 요소 수가 이 임곗값보다 작으면 파라미터 텐서가 분할되지 않습니다. 이렇게 하면 파라미터 텐서가 데이터 병렬 GPU에 복제되므로 통신 오버헤드를 줄이는 데 도움이 됩니다. -
"sdp_max_live_parameters"(int, default: 1e9) – 순방향 및 역방향 패스 중 동시에 재조합된 훈련 상태에 있을 수 있는 최대 파라미터 수를 지정합니다. 활성 파라미터 수가 지정된 임계값에 도달하면AllGather작업을 통한 파라미터 가져오기가 일시 중지됩니다. 이 파라미터를 늘리면 메모리 사용량이 늘어납니다. -
"sdp_hierarchical_allgather"(bool, default: True) –True로 설정하면AllGather작업이 계층적으로 실행됩니다. 즉, 먼저 각 노드 내에서 실행된 후 여러 노드에서 실행됩니다. 여러 노드 분산 훈련 작업의 경우 계층적AllGather작업이 자동으로 활성화됩니다. -
"sdp_gradient_clipping"(float, default: 1.0) – 모델 파라미터를 통해 그라디언트를 역방향으로 전파하기 전에 그라디언트의 L2 규범을 클리핑하기 위한 그라디언트 임곗값을 지정합니다. 샤딩된 데이터 병렬 처리가 활성화되면 그라디언트 클리핑도 활성화됩니다. 기본 임곗값은1.0입니다. 폭발적인 그라디언트 문제가 발생할 경우 이 파라미터를 조정합니다.
다음 코드는 샤딩된 데이터 병렬 처리를 구성하는 방법의 예를 보여줍니다.
import sagemaker from sagemaker.pytorch import PyTorch smp_options = { "enabled": True, "parameters": { # "pipeline_parallel_degree": 1, # Optional, default is 1 # "tensor_parallel_degree": 1, # Optional, default is 1 "ddp": True, # parameters for sharded data parallelism "sharded_data_parallel_degree":2, # Add this to activate sharded data parallelism "sdp_reduce_bucket_size": int(5e8), # Optional "sdp_param_persistence_threshold": int(1e6), # Optional "sdp_max_live_parameters": int(1e9), # Optional "sdp_hierarchical_allgather":True, # Optional "sdp_gradient_clipping":1.0# Optional } } mpi_options = { "enabled" : True, # Required "processes_per_host" :8# Required } smp_estimator = PyTorch( entry_point="your_training_script.py", # Specify your train script role=sagemaker.get_execution_role(), instance_count=1, instance_type='ml.p3.16xlarge', framework_version='1.13.1', py_version='py3', distribution={ "smdistributed": {"modelparallel": smp_options}, "mpi": mpi_options }, base_job_name="sharded-data-parallel-job" ) smp_estimator.fit('s3://my_bucket/my_training_data/')
참조 구성
SageMaker 분산 훈련 팀은 시작점으로 사용할 수 있는 다음과 같은 참조 구성을 제공합니다. 다음 구성에서 추론하여 모델 구성의 GPU 메모리 사용량을 실험하고 추정할 수 있습니다.
SMDDP Collectives를 사용한 샤딩 데이터 병렬 처리
| 모델/파라미터 수 | Num 인스턴스 | 인스턴스 유형 | 시퀀스 길이 | 글로벌 배치 크기 | 미니 배치 크기 | 샤딩된 데이터 병렬도 |
|---|---|---|---|---|---|---|
| GPT-NEOX-20B | 2 | ml.p4d.24xlarge | 2048 | 64 | 4 | 16 |
| GPT-NEOX-20B | 8 | ml.p4d.24xlarge | 2048 | 768 | 12 | 32 |
예를 들어, 200억 파라미터 모델의 시퀀스 길이를 늘이거나 모델 크기를 650억 파라미터로 늘리려면 먼저 배치 크기를 줄여야 합니다. 모델이 여전히 가장 작은 배치 크기(배치 크기 1)에 맞지 않으면 모델 병렬도를 높여 봅니다.
텐서 병렬 처리 및 NCCL Collectives를 사용한 샤딩 데이터 병렬 처리
| 모델/파라미터 수 | Num 인스턴스 | 인스턴스 유형 | 시퀀스 길이 | 글로벌 배치 크기 | 미니 배치 크기 | 샤딩된 데이터 병렬도 | 텐서 병렬도 | 활성화 오프로딩 |
|---|---|---|---|---|---|---|---|---|
| GPT-NEOX-65B | 64 | ml.p4d.24xlarge | 2048 | 512 | 8 | 16 | 8 | Y |
| GPT-NEOX-65B | 64 | ml.p4d.24xlarge | 4096 | 512 | 2 | 64 | 2 | Y |
샤딩된 데이터 병렬 처리와 텐서 병렬 처리를 함께 사용하는 것은 대규모 언어 모델(LLM)을 대규모 클러스터에 맞추고 시퀀스 길이가 긴 텍스트 데이터를 사용하고 싶을 때 유용합니다. 이를 통해 더 작은 배치 크기를 사용하고 결과적으로 더 긴 텍스트 시퀀스에 대해 LLM을 훈련시키기 위한 GPU 메모리 사용량을 처리할 수 있습니다. 자세한 내용은 텐서 병렬 처리를 사용한 샤딩된 데이터 병렬 처리을 참조하십시오.
사례 연구, 벤치마크 및 기타 구성 예제는 블로그 게시물 Amazon SageMaker AI 모델 병렬 라이브러리의 새로운 성능 개선
SMDDP Collectives를 사용한 샤딩 데이터 병렬 처리
SageMaker 데이터 병렬 처리 라이브러리는 AWS 인프라에 최적화된 집합 통신 기본(SMDDP 집합체)을 제공합니다. Elastic Fabric Adapter(EFA)
참고
SMDDP Collectives를 사용한 샤딩된 데이터 병렬 처리는 SageMaker 모델 병렬 처리 라이브러리 v1.13.0 이상 및 SageMaker 데이터 병렬 처리 라이브러리 v1.6.0 이상에서 사용할 수 있습니다. Supported configurations도 참조하여 SMDDP Collectives에서 샤딩된 데이터 병렬 처리를 사용할 수 있습니다.
대규모 분산 훈련에서 일반적으로 사용되는 기법인 샤딩된 데이터 병렬 처리에서는 AllGather 집합체를 사용하여 순방향 및 역방향 패스 계산을 위해 샤딩된 계층 파라미터를 재구성하며 이때 GPU 계산이 병행됩니다. 대형 모델의 경우 GPU 병목 현상 문제와 훈련 속도 저하를 방지하려면 AllGather 작업을 효율적으로 수행하는 것이 중요합니다. 샤딩된 데이터 병렬 처리를 활성화하면 SMDDP Collectives가 성능이 중요한 AllGather 집합체에 놓이므로 훈련 처리량이 향상됩니다.
SMDDP Collectives를 사용한 훈련
훈련 작업에 샤딩된 데이터 병렬 처리가 활성화되고 Supported configurations를 충족하면 SMDDP Collectives가 자동으로 활성화됩니다. 내부적으로 SMDDP Collectives는 AWS 인프라에서 성능을 발휘하도록 AllGather 집합체를 최적화하고 다른 모든 집합체에 대해 NCCL로 돌아갑니다. 또한 지원되지 않는 구성에서는 AllGather를 포함한 모든 집합체가 자동으로 NCCL 백엔드를 사용합니다.
SageMaker 모델 병렬 처리 라이브러리 버전 1.13.0부터 "ddp_dist_backend" 파라미터가 modelparallel 옵션에 추가되었습니다. 이 구성 파라미터의 기본값은 "auto"인데, 이는 가능하면 SMDDP Collectives를 사용하고 그렇지 않으면 NCCL로 돌아갑니다. 라이브러리가 항상 NCCL을 사용하도록 하려면 "nccl"을 "ddp_dist_backend" 구성 파라미터로 지정합니다.
다음 코드 예제는 "ddp_dist_backend" 파라미터와 함께 샤딩된 데이터 병렬 처리를 사용하여 PyTorch 예측기를 설정하는 방법을 보여줍니다. 이는 기본적으로 "auto"로 설정되어 있으므로 선택적으로 추가할 수 있습니다.
import sagemaker from sagemaker.pytorch import PyTorch smp_options = { "enabled":True, "parameters": { "partitions": 1, "ddp": True, "sharded_data_parallel_degree":64"bf16": True, "ddp_dist_backend": "auto" # Specify "nccl" to force to use NCCL. } } mpi_options = { "enabled" : True, # Required "processes_per_host" : 8 # Required } smd_mp_estimator = PyTorch( entry_point="your_training_script.py", # Specify your train script source_dir="location_to_your_script", role=sagemaker.get_execution_role(), instance_count=8, instance_type='ml.p4d.24xlarge', framework_version='1.13.1', py_version='py3', distribution={ "smdistributed": {"modelparallel": smp_options}, "mpi": mpi_options }, base_job_name="sharded-data-parallel-demo", ) smd_mp_estimator.fit('s3://my_bucket/my_training_data/')
지원되는 구성
SMDDP Collectives를 사용한 AllGather 작업은 다음 구성 요구 사항이 모두 충족될 때 훈련 작업에서 활성화됩니다.
-
샤딩된 데이터 병렬도가 1보다 큼
-
Instance_count가 1보다 큼 -
Instance_type이ml.p4d.24xlarge와 같음 -
PyTorch용 SageMaker 훈련 컨테이너 v1.12.1 이상
-
SageMaker 데이터 병렬 처리 라이브러리 v1.6.0 이상
-
SageMaker 모델 병렬화 라이브러리 v1.13.0 이상
성능 및 메모리 조정
SMDDP Collectives는 추가 GPU 메모리를 사용합니다. 다양한 모델 훈련 사용 사례에 따라 GPU 메모리 사용량을 구성하는 두 가지 환경 변수가 있습니다.
-
SMDDP_AG_SCRATCH_BUFFER_SIZE_BYTES– SMDDPAllGather작업 중에AllGather입력 버퍼는 노드 간 통신을 위한 임시 버퍼에 복사됩니다.SMDDP_AG_SCRATCH_BUFFER_SIZE_BYTES변수는 이 임시 버퍼의 크기(바이트)를 제어합니다. 임시 버퍼의 크기가AllGather입력 버퍼 크기보다 작은 경우AllGather집합체는 NCCL을 사용하도록 돌아갑니다.-
기본값: 16 * 1024 * 1024(16MB)
-
허용되는 값: 8192의 모든 배수
-
-
SMDDP_AG_SORT_BUFFER_SIZE_BYTES–SMDDP_AG_SORT_BUFFER_SIZE_BYTES변수는 노드 간 통신에서 수집한 데이터를 보관할 임시 버퍼의 크기(바이트)입니다. 이 임시 버퍼의 크기가1/8 * sharded_data_parallel_degree * AllGather input size보다 작으면AllGather집합체는 NCCL을 사용하도록 돌아갑니다.-
기본값: 128 * 1024 * 1024(128MB)
-
허용되는 값: 8192의 모든 배수
-
버퍼 크기 변수의 조정 지침
환경 변수의 기본값은 대부분의 사용 사례에서 잘 작동합니다. 훈련 시 메모리 부족(OOM) 오류가 발생한 경우에만 이러한 변수를 조정하는 것이 좋습니다.
다음 목록에서는 성능 이득을 유지하면서 SMDDP Collectives의 GPU 메모리 사용량을 줄이기 위한 몇 가지 조정 팁을 설명합니다.
-
SMDDP_AG_SCRATCH_BUFFER_SIZE_BYTES튜닝-
모델이 작을수록
AllGather입력 버퍼 크기도 작습니다. 따라서 파라미터가 적은 모델의 경우 필요한SMDDP_AG_SCRATCH_BUFFER_SIZE_BYTES크기가 더 작을 수 있습니다. -
모델이 더 많은 GPU에 분할되므로
sharded_data_parallel_degree가 증가할수록AllGather입력 버퍼 크기는 줄어듭니다. 따라서sharded_data_parallel_degree값이 큰 훈련 작업의 경우SMDDP_AG_SCRATCH_BUFFER_SIZE_BYTES의 필수 크기가 작아도 됩니다.
-
-
SMDDP_AG_SORT_BUFFER_SIZE_BYTES튜닝-
파라미터가 적은 모델의 경우 노드 간 통신에서 수집되는 데이터 양이 더 적습니다. 따라서 파라미터 수가 적은 모델의 경우 필요한
SMDDP_AG_SORT_BUFFER_SIZE_BYTES크기가 더 작을 수 있습니다.
-
일부 집합체는 NCCL을 사용하도록 돌아갈 수도 있습니다. 따라서 최적의 SMDDP 집합체를 통해 성능 이득을 얻지 못할 수도 있습니다. 추가 GPU 메모리를 사용할 수 있는 경우 SMDDP_AG_SCRATCH_BUFFER_SIZE_BYTES 및 SMDDP_AG_SORT_BUFFER_SIZE_BYTES 값을 높여 성능 이득을 얻는 것을 고려해 봅니다.
다음 코드는 PyTorch 예측기용 배포 파라미터의 mpi_options에 환경 변수를 추가하여 환경 변수를 구성하는 방법을 보여줍니다.
import sagemaker from sagemaker.pytorch import PyTorch smp_options = { .... # All modelparallel configuration options go here } mpi_options = { "enabled" : True, # Required "processes_per_host" : 8 # Required } # Use the following two lines to tune values of the environment variables for buffer mpioptions += " -x SMDDP_AG_SCRATCH_BUFFER_SIZE_BYTES=8192" mpioptions += " -x SMDDP_AG_SORT_BUFFER_SIZE_BYTES=8192" smd_mp_estimator = PyTorch( entry_point="your_training_script.py", # Specify your train script source_dir="location_to_your_script", role=sagemaker.get_execution_role(), instance_count=8, instance_type='ml.p4d.24xlarge', framework_version='1.13.1', py_version='py3', distribution={ "smdistributed": {"modelparallel": smp_options}, "mpi": mpi_options }, base_job_name="sharded-data-parallel-demo-with-tuning", ) smd_mp_estimator.fit('s3://my_bucket/my_training_data/')
샤딩된 데이터 병렬 처리를 사용한 혼합 정밀도 훈련
반정밀도 부동 소수점 숫자 및 샤딩된 데이터 병렬 처리로 GPU 메모리를 더욱 절약하려면 분산 훈련 구성에 파라미터 하나를 추가하여 16비트 부동 소수점 형식(FP16) 또는 브레인 부동 소수점 형식
참고
샤딩된 데이터 병렬 처리를 사용한 혼합 정밀도 훈련은 SageMaker 모델 병렬 처리 라이브러리 v1.11.0 이상에서 사용할 수 있습니다.
샤딩된 데이터 병렬 처리를 사용한 FP16 훈련의 경우
샤딩된 데이터 병렬 처리를 사용한 FP16 훈련을 실행하려면 "fp16": True"를 smp_options 구성 사전에 추가하세요. 훈련 스크립트에서 smp.DistributedOptimizer 모듈을 통해 정적 손실 스케일링 옵션과 동적 손실 스케일링 옵션 중 선택할 수 있습니다. 자세한 내용은 모델 병렬 처리를 사용한 FP16 훈련 섹션을 참조하세요.
smp_options = { "enabled":True, "parameters": { "ddp":True, "sharded_data_parallel_degree":2, "fp16":True} }
샤딩된 데이터 병렬 처리를 사용한 BF16 훈련의 경우
SageMaker AI의 샤딩된 데이터 병렬 처리 기능은 BF16 데이터 형식 훈련을 지원합니다. BF16 데이터 유형은 8비트를 사용하여 부동 소수점 숫자의 지수를 나타내는 반면 FP16 데이터 유형은 5비트를 사용합니다. 지수로 8비트를 보존하면 32비트 단정밀도 부동 소수점(FP32) 숫자의 지수를 동일하게 표현할 수 있습니다. 따라서 FP32 및 BF16 간 변환이 더 간단해지며, 특히 대형 모델을 훈련할 때 FP16 훈련에서 자주 발생하는 오버플로 및 언더플로 문제가 크게 줄어듭니다. 두 데이터 유형 모두 총 16비트를 사용하지만 BF16 형식에서 지수의 표현 범위가 넓어지면 정밀도가 떨어집니다. 대형 모델을 훈련시키는 경우 이러한 정밀도 감소는 범위와 훈련 안정성의 적절한 절충안으로 고려됩니다.
참고
현재 BF16 훈련은 샤딩된 데이터 병렬 처리가 활성화된 경우에만 작동합니다.
샤딩된 데이터 병렬 처리를 사용한 BF16 훈련을 실행하려면 "bf16": True를 smp_options 구성 사전에 추가하세요.
smp_options = { "enabled":True, "parameters": { "ddp":True, "sharded_data_parallel_degree":2, "bf16":True} }
텐서 병렬 처리를 사용한 샤딩된 데이터 병렬 처리
샤딩된 데이터 병렬 처리를 사용하고 글로벌 배치 크기도 줄여야 하는 경우 샤딩된 데이터 병렬 처리와 함께 텐서 병렬 처리를 사용하는 것을 고려해 보세요. 초대형 컴퓨팅 클러스터(일반적으로 노드 128개 이상)에서 샤딩된 데이터 병렬 처리를 사용하여 대규모 모델을 훈련시키는 경우 GPU당 배치 크기가 작아도 글로벌 배치 크기가 매우 커집니다. 이로 인해 컨버전스 문제나 낮은 컴퓨팅 성능 문제가 발생할 수 있습니다. 단일 배치 크기가 이미 커서 더 이상 줄일 수 없는 경우 샤딩된 데이터 병렬 처리만으로는 GPU당 배치 크기를 줄일 수 없는 경우가 있습니다. 이러한 경우 샤딩된 데이터 병렬 처리를 텐서 병렬 처리와 함께 사용하면 글로벌 배치 크기를 줄이는 데 도움이 됩니다.
최적의 샤딩된 데이터 병렬도와 텐서 병렬도를 선택하는 것은 모델의 규모, 인스턴스 유형, 모델이 수렴하기에 적합한 글로벌 배치 크기에 따라 달라집니다. CUDA 메모리 부족 오류를 해결하고 최상의 성능을 얻으려면 낮은 텐서 병렬 수준에서 시작하여 글로벌 배치 크기를 컴퓨팅 클러스터에 맞추는 것이 좋습니다. 텐서 병렬 처리와 샤딩된 데이터 병렬 처리를 조합하여 모델 병렬 처리용 GPU를 그룹화해 모델 복제본 수 및 글로벌 배치 크기를 줄임으로써 글로벌 배치 크기를 조정하는 방법을 알아보려면 다음 두 가지 예제 사례를 참조하세요.
참고
이 기능은 SageMaker 모델 병렬 처리 라이브러리 v1.15에서 사용할 수 있으며, PyTorch v1.13.1을 지원합니다.
참고
이 기능은 라이브러리의 텐서 병렬 처리 기능을 통해 지원되는 모델에 사용할 수 있습니다. 지원 모델 목록은 Hugging Face Transformer 모델 지원을 참조하세요. 또한 훈련 스크립트를 수정할 때는 tensor_parallelism=True를 smp.model_creation 인수에 전달해야 합니다. 자세한 내용은 SageMaker AI 예제 GitHub 리포지토리train_gpt_simple.py
예시 1
샤딩된 데이터 병렬도를 32(sharded_data_parallel_degree=32)로 설정하고 GPU당 배치 크기를 1로 설정하여 1536개의 GPU 클러스터(각각 8개의 GPU가 있는 192개 노드)에서 모델을 훈련하고 싶다고 가정해 봅니다. 여기서 각 배치의 시퀀스 길이는 4096개 토큰입니다. 이 경우 모델 복제본은 1536개이고 글로벌 배치 크기는 1536이 되며 각 글로벌 배치에는 약 600만 개의 토큰이 포함됩니다.
(1536 GPUs) * (1 batch per GPU) = (1536 global batches) (1536 batches) * (4096 tokens per batch) = (6,291,456 tokens)
여기에 텐서 병렬 처리를 추가하면 글로벌 배치 크기를 줄일 수 있습니다. 한 가지 구성 예는 텐서 병렬도를 8로 설정하고 GPU당 배치 크기를 4로 설정하는 것입니다. 이는 192개의 텐서 병렬 그룹 또는 192개의 모델 복제본을 형성하며 각 모델 복제본은 8개 GPU에 분산됩니다. 배치 크기 4는 반복당 및 텐서 병렬 그룹당 훈련 데이터의 양입니다. 즉, 각 모델 복제본은 반복당 4개의 배치를 소비합니다. 이 경우 글로벌 배치 크기는 768이 되고 각 글로벌 배치에는 약 300만 개의 토큰이 포함됩니다. 따라서 샤딩된 데이터 병렬 처리만 사용하는 이전 사례에 비해 글로벌 배치 크기가 절반으로 줄어듭니다.
(1536 GPUs) / (8 tensor parallel degree) = (192 tensor parallelism groups) (192 tensor parallelism groups) * (4 batches per tensor parallelism group) = (768 global batches) (768 batches) * (4096 tokens per batch) = (3,145,728 tokens)
예시 2
샤딩된 데이터 병렬 처리와 텐서 병렬 처리가 모두 활성화되면 라이브러리는 먼저 텐서 병렬 처리를 적용하고 이 차원에 모델을 샤딩합니다. 각 텐서 병렬 랭크의 경우 데이터 병렬 처리가 sharded_data_parallel_degree에 따라 적용됩니다.
예를 들어 텐서 병렬도가 4(GPU 4개로 구성된 그룹 형성), 샤딩된 데이터 병렬도가 4인 32개의 GPU를 설정하여 복제도가 2가 된다고 가정해 봅시다. 이 할당은 텐서 병렬도를 기반으로 다음과 같이 8개의 (0,1,2,3), (4,5,6,7), (8,9,10,11), (12,13,14,15), (16,17,18,19), (20,21,22,23), (24,25,26,27), (28,29,30,31) GPU 그룹을 생성합니다. 즉, 4개의 GPU가 하나의 텐서 병렬 그룹을 형성합니다. 이 경우 텐서 병렬 그룹 0순위 GPU의 감소된 데이터 병렬 그룹은 (0,4,8,12,16,20,24,28)입니다. 축소된 데이터 병렬 그룹은 샤딩된 데이터 병렬도 4를 기준으로 샤딩되므로 데이터 병렬 처리를 위한 두 개의 복제 그룹이 생성됩니다. GPU (0,4,8,12)는 0번째 텐서 병렬 랭크의 모든 파라미터 전체 사본을 집합적으로 보유하는 하나의 샤딩 그룹을 형성하고 GPU (16,20,24,28)은 이러한 또 다른 그룹을 형성합니다. 다른 텐서 병렬 랭크에도 유사한 샤딩 및 복제 그룹이 있습니다.
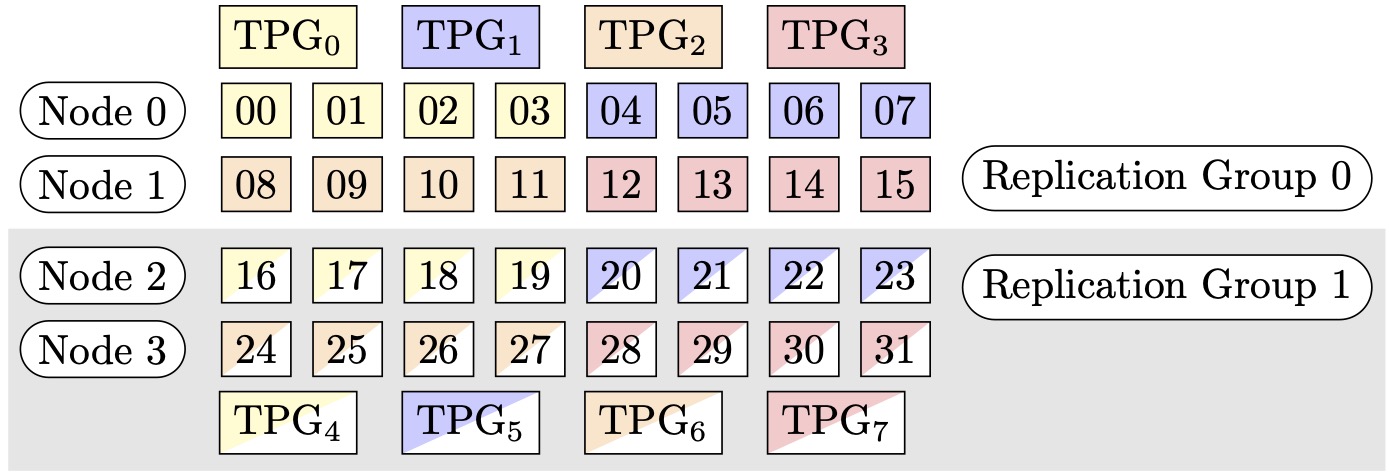
그림 1: (노드, 샤딩된 데이터 병렬도, 텐서 병렬도) = (4, 4, 4)에 대한 Tensor 병렬 처리 그룹. 여기서 각 사각형은 인덱스가 0~31인 GPU를 나타냅니다. GPUs는 TPG0에서 TPG7로 텐서 병렬 그룹을 구성합니다. 복제 그룹은 ({TPG0, TPG4}, {TPG1, TPG5}, {TPG2, TPG6} 및 {TPG3, TPG7})입니다. 각 복제 그룹 페어는 동일한 색상을 공유하지만 다르게 채워집니다.
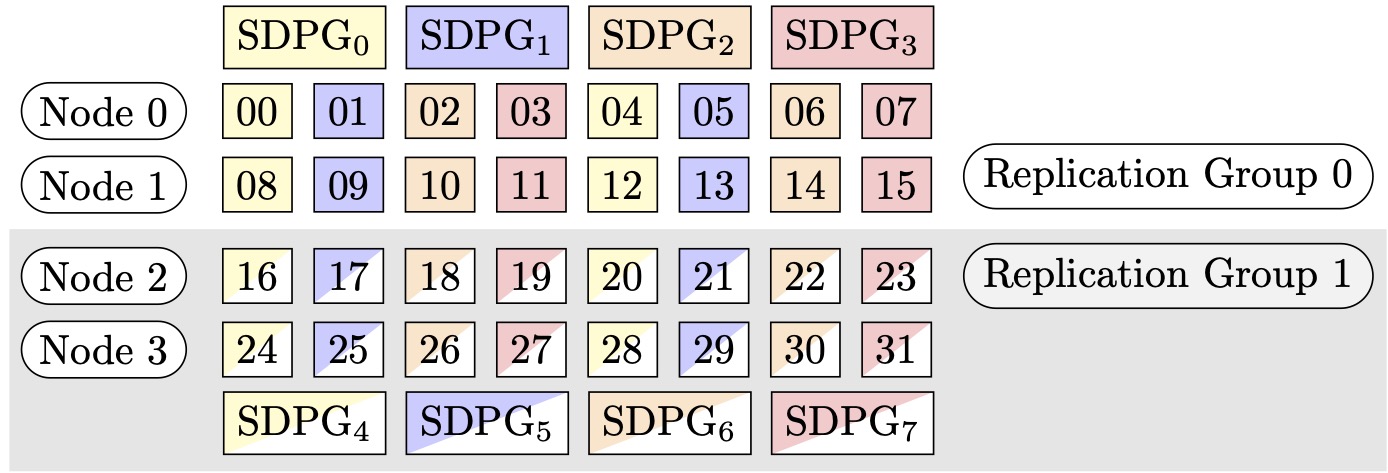
그림 2: (노드, 샤딩된 데이터 병렬 정도, 텐서 병렬 정도) = (4, 4, 4)에 대한 샤딩된 데이터 병렬 처리 그룹. 여기서 각 사각형은 인덱스가 0~31인 GPU를 나타냅니다. GPUs는 SDPG0에서 SDPG7로 샤딩된 데이터 병렬 그룹을 구성합니다. 복제 그룹은 ({SDPG0, SDPG4}, {SDPG1, SDPG5}, {SDPG2, SDPG6} 및 {SDPG3, SDPG7})입니다. 각 복제 그룹 페어는 동일한 색상을 공유하지만 다르게 채워집니다.
텐서 병렬 처리를 사용하여 샤딩된 데이터 병렬 처리를 활성화하는 방법
텐서 병렬 처리와 함께 샤딩된 데이터 병렬 처리를 사용하려면 SageMaker PyTorch 예측기 클래스의 객체를 생성할 구성의 sharded_data_parallel_degree 및 tensor_parallel_degree를 모두 distribution으로 설정해야 합니다.
또한 prescaled_batch를 활성화해야 합니다. 즉, 각 GPU가 자체 데이터 배치를 읽는 대신 각 텐서 병렬 그룹이 선택한 배치 크기의 결합된 배치를 집합적으로 읽습니다. 실질적으로 데이터세트를 GPU 개수(또는 데이터 병렬 크기 smp.dp_size())와 동일한 개수로 부분을 나누는 대신 GPU 개수를 tensor_parallel_degree로 나눈 개수(축소된 데이터 병렬 크기 smp.rdp_size()라고도 함)와 동일한 개수로 부분을 나눕니다. 프리스케일 배치에 대한 자세한 내용은 SageMaker Python SDK 설명서에서 프리스케일 배치train_gpt_simple.py
다음 코드 조각에서는 예시 2에서 앞서 언급한 시나리오를 기반으로 PyTorch 예측기 객체를 생성하는 예제를 보여줍니다.
mpi_options = "-verbose --mca orte_base_help_aggregate 0 " smp_parameters = { "ddp": True, "fp16": True, "prescaled_batch": True, "sharded_data_parallel_degree":4, "tensor_parallel_degree":4} pytorch_estimator = PyTorch( entry_point="your_training_script.py", role=role, instance_type="ml.p4d.24xlarge", volume_size=200, instance_count=4, sagemaker_session=sagemaker_session, py_version="py3", framework_version="1.13.1", distribution={ "smdistributed": { "modelparallel": { "enabled": True, "parameters": smp_parameters, } }, "mpi": { "enabled": True, "processes_per_host": 8, "custom_mpi_options": mpi_options, }, }, source_dir="source_directory_of_your_code", output_path=s3_output_location)
샤딩된 데이터 병렬 처리 사용에 대한 팁과 고려 사항
SageMaker 모델 병렬 처리 라이브러리의 샤딩된 데이터 병렬 처리를 사용할 때는 다음 사항을 고려합니다.
-
샤딩된 데이터 병렬 처리는 FP16 훈련과 호환됩니다. FP16 훈련을 실행하려면 모델 병렬 처리를 사용한 FP16 훈련 섹션을 참조하세요.
-
샤딩된 데이터 병렬 처리는 텐서 병렬 처리와 호환됩니다. 텐서 병렬 처리와 함께 샤딩된 데이터 병렬 처리를 사용할 때 고려해야 할 사항은 다음과 같습니다.
-
텐서 병렬 처리와 함께 샤딩된 데이터 병렬 처리를 사용하는 경우 임베딩 레이어도 텐서 병렬 그룹 전체에 자동으로 분산됩니다. 즉,
distribute_embedding파라미터는 자동으로True로 설정됩니다. 텐서 병렬 처리에 대한 자세한 내용은 텐서 병렬 처리을 참조하세요. -
텐서 병렬 처리가 있는 샤딩된 데이터 병렬 처리는 현재 NCCL 집합체를 분산 훈련 전략의 백엔드로 사용합니다.
자세한 내용은 텐서 병렬 처리를 사용한 샤딩된 데이터 병렬 처리 섹션을 참조하세요.
-
-
샤딩된 데이터 병렬 처리는 현재 파이프라인 병렬 처리 또는 옵티마이저 상태 샤딩과 호환되지 않습니다. 샤딩된 데이터 병렬 처리를 활성화하려면 옵티마이저 상태 샤딩을 끄고 파이프라인 병렬도를 1로 설정합니다.
-
그라디언트 누적과 함께 샤딩된 데이터 병렬 처리를 사용하려면 모델을
smdistributed.modelparallel.torch.DistributedModel모듈로 래핑하는 동안 backward_passes_per_step인수를 누적 단계 수로 설정합니다. 이렇게 하면 모델 복제 그룹(샤딩 그룹 )전반의 그라디언트AllReduce연산이 그라디언트 누적 경계에서 이루어지도록 할 수 있습니다. -
라이브러리 체크포인트 API인
smp.save_checkpoint및smp.resume_from_checkpoint를 사용하여 샤딩된 데이터 병렬 처리로 훈련한 모델을 체크포인트할 수 있습니다. 자세한 내용은 분산 PyTorch 모델 체크포인트 지정(SageMaker 모델 병렬 처리 라이브러리 v1.10.0 이상 전용) 섹션을 참조하세요. -
delayed_parameter_initialization구성 파라미터 동작은 샤딩된 데이터 병렬 처리에서 변경됩니다. 이 두 기능을 동시에 켜면 모델 생성 시 파라미터 초기화를 지연시키는 대신 샤딩 방식으로 파라미터를 즉시 초기화하므로 각 랭크가 파라미터의 샤드를 초기화하고 저장합니다. -
샤딩된 데이터 병렬 처리가 활성화되면
optimizer.step()호출이 실행될 때 라이브러리가 내부적으로 그라디언트 클리핑을 수행합니다. 예를 들어 그라디언트 클리핑에는torch.nn.utils.clip_grad_norm_()등의 유틸리티 API를 사용할 필요가 없습니다. 그라디언트 클리핑의 임곗값을 조정하려면 샤딩된 데이터 병렬 처리를 훈련 작업에 적용하는 방법 섹션에 표시된 대로 SageMaker PyTorch 예측기를 구성할 때 배포 파라미터 구성의 sdp_gradient_clipping파라미터를 통해 임곗값을 설정할 수 있습니다.
