기계 번역으로 제공되는 번역입니다. 제공된 번역과 원본 영어의 내용이 상충하는 경우에는 영어 버전이 우선합니다.
다중 모델 엔드포인트
다중 모델 엔드포인트는 많은 수의 모델을 배포하도록 확장 가능하고 비용 효율적인 솔루션을 제공합니다. 이들은 동일한 리소스 플릿과 공유 제공 컨테이너를 사용하여 모든 모델을 호스팅합니다. 즉, 단일 모델 엔드포인트를 사용하는 것에 비해 엔드포인트 사용률을 높여 호스팅 비용을 절감합니다. Amazon SageMaker AI에서는 메모리에 모델 로딩 및 엔드포인트에 대한 트래픽 패턴을 기반으로 하는 모델 확장을 관리하므로 배포 오버헤드도 줄일 수 있습니다.
다음 다이어그램은 단일 모델 엔드포인트와 비교하여 다중 모델 엔드포인트의 작동 방식을 보여줍니다.
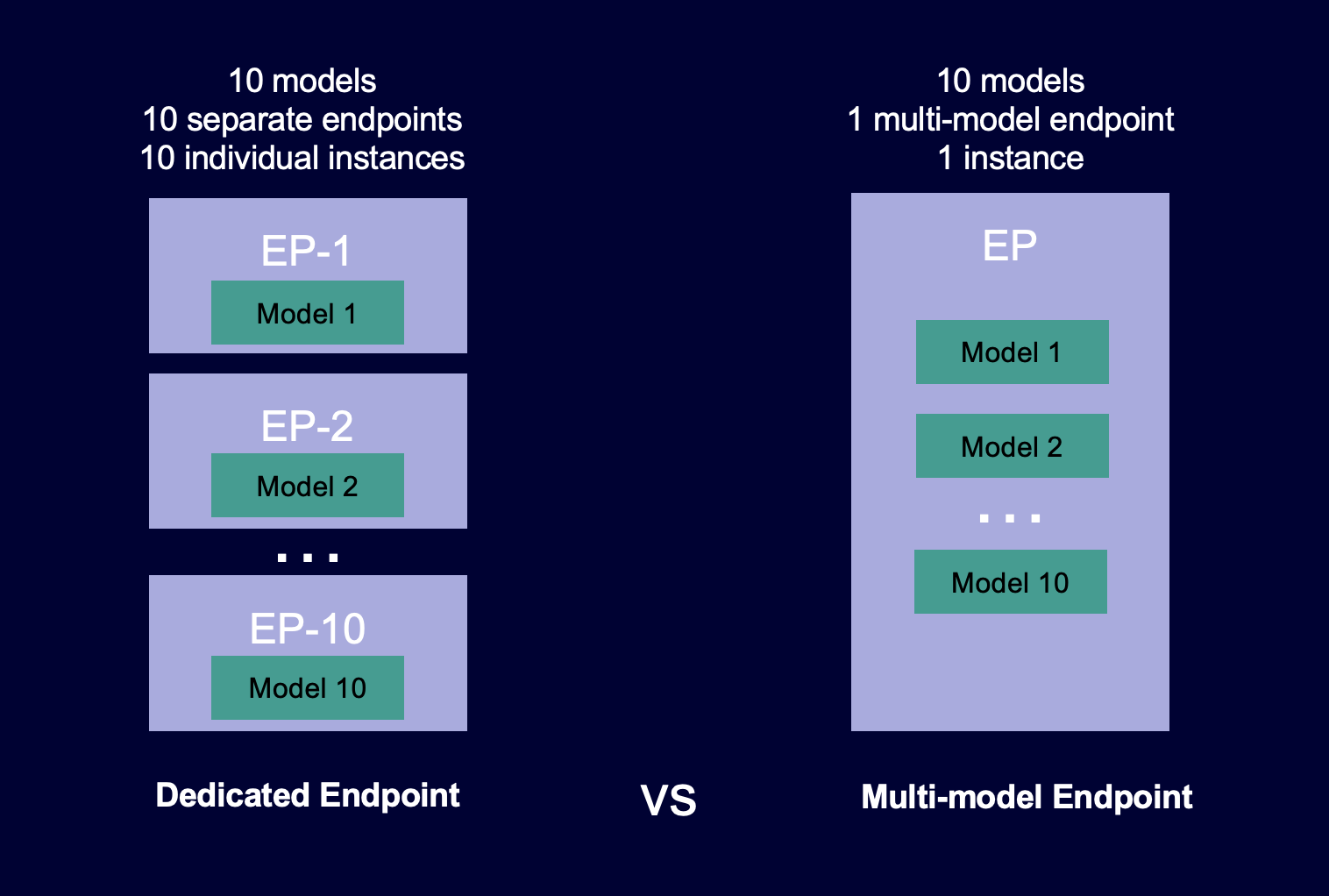
다중 모델 엔드포인트는 공유 서비스 컨테이너에서 동일한 ML 프레임워크를 사용하는 다수의 모델을 호스팅하는 데 적합합니다. 자주 액세스하는 모델과 자주 액세스하지 않는 모델이 혼합되어 있는 경우 다중 모델 엔드포인트는 더 적은 리소스와 더 큰 비용 절감으로 이러한 트래픽을 효율적으로 처리할 수 있습니다. 애플리케이션은 자주 사용하지 않는 모델을 간접 호출할 때 가끔 발생하는 콜드 스타트 관련 지연 시간 페널티를 허용할 수 있어야 합니다.
다중 모델 엔드포인트는 CPU 및 GPU 지원 모델 호스팅을 모두 지원합니다. GPU 지원 모델을 사용하면 엔드포인트와 기본 가속 컴퓨팅 인스턴스의 사용량을 늘려 모델 배포 비용을 줄일 수 있습니다.
다중 모델 엔드포인트를 사용하면 모델 전체에서 메모리 리소스도 시분할할 수 있습니다. 모델들의 크기와 호출 지연 시간이 상당히 비슷한 경우에 가장 효과적입니다. 이 경우 다중 모델 엔드포인트는 모든 모델에서 인스턴스를 효과적으로 사용할 수 있습니다. 초당 트랜잭션 수(TPS) 또는 지연 시간 요구 사항이 상당히 높은 모델을 사용하는 경우에는 전용 엔드포인트에 이들을 호스팅하는 것이 좋습니다.
다음과 같은 기능을 가진 다중 모델 엔드포인트를 사용할 수 있습니다.
-
AWS PrivateLink 및 VPCs
-
직렬 추론 파이프라인(단, 다중 모델 지원 컨테이너는 하나만 추론 파이프라인에 포함될 수 있음)
-
A/B 테스트
AWS SDK for Python (Boto) 또는 SageMaker AI 콘솔을 사용하여 다중 모델 엔드포인트를 생성할 수 있습니다. CPU 지원 다중 모델 엔드포인트의 경우 다중 모델 서버
주제
다중 모델 엔드포인트 작동 방식
SageMaker AI는 컨테이너 메모리의 다중 모델 엔드포인트에서 호스팅되는 모델의 수명 주기를 관리합니다. SageMaker AI는 엔드포인트를 만들 때 Amazon S3 버킷에서 컨테이너로 모든 모델을 다운로드하는 대신 모델을 간접적으로 호출할 때 동적으로 모델을 로드하고 캐시합니다. SageMaker AI는 특정 모델에 대한 간접 호출 요청을 수신하면 다음 작업을 수행합니다.
-
엔드포인트 뒤의 인스턴스로 요청을 라우팅합니다.
-
S3 버킷에서 해당 인스턴스의 스토리지 볼륨으로 모델을 다운로드합니다.
-
해당 가속 컴퓨팅 인스턴스의 컨테이너 메모리(CPU 또는 GPU 지원 인스턴스가 있는지 여부에 따라 CPU 또는 GPU)로 모델을 로드합니다. 모델이 이미 컨테이너 메모리에 로드된 경우 SageMaker AI는 모델을 다운로드 및 로드할 필요가 없기 때문에 간접 호출이 더 빨라집니다.
SageMaker AI에서는 모델에 대한 요청을 모델이 이미 로드된 인스턴스로 계속 라우팅합니다. 그러나 모델이 많은 간접 호출 요청을 수신했는데 다중 모델 엔드포인트에 대한 추가 인스턴스가 있는 경우 SageMaker AI에서는 트래픽을 수용하기 위해 일부 요청을 다른 인스턴스로 라우팅합니다. 모델이 두 번째 인스턴스에 아직 로드되지 않은 경우 해당 인스턴스의 스토리지 볼륨으로 모델이 다운로드되고 컨테이너 메모리에 로드됩니다.
인스턴스의 메모리 사용률이 높은데 SageMaker AI에서 다른 모델을 메모리로 로드해야 하는 경우 해당 인스턴스의 컨테이너에서 사용되지 않는 모델을 로드 해제하여 모델을 로드하기 위한 충분한 메모리를 확보합니다. 언로드된 모델은 인스턴스의 스토리지 볼륨에 남아 있으며 나중에 S3 버킷에서 다시 다운로드하지 않고도 컨테이너 메모리로 로드할 수 있습니다. 인스턴스의 스토리지 볼륨 용량이 부족해지면 SageMaker AI에서 사용되지 않는 모델을 스토리지 볼륨에서 모두 삭제합니다.
모델을 삭제하려면 요청 전송을 중지하고 S3 버킷에서 삭제합니다. SageMaker AI는 사용 중인 컨테이너에서 다중 모델 엔드포인트 기능을 제공합니다. 다중 모델 엔드포인트에 모델을 추가하고 삭제할 때 엔드포인트 자체를 업데이트할 필요가 없습니다. 모델을 추가하려면 S3 버킷에 모델을 업로드하고 호출합니다. 사용하기 위해 코드 변경을 수행할 필요가 없습니다.
참고
다중 모델 엔드포인트를 업데이트하면 다중 모델 엔드포인트의 스마트 라우팅이 트래픽 패턴에 맞게 조정되므로 엔드포인트의 초기 간접 호출 요청의 지연 시간이 길어질 수 있습니다. 하지만 트래픽 패턴을 학습하고 나면 가장 자주 사용되는 모델에서 지연 시간이 짧아질 수 있습니다. 사용 빈도가 낮은 모델은 인스턴스에 동적으로 로드되므로 콜드 스타트 지연 시간이 약간 발생할 수 있습니다.
다중 모델 엔드포인트를 위한 샘플 노트북
다중 모델 엔드포인트 사용 방법을 자세히 알아보려면 다음 샘플 노트북을 사용해 보세요.
-
CPU 기반 인스턴스를 사용하는 다중 모델 엔드포인트의 예제:
-
다중 모델 엔드포인트 XGBoost 샘플 노트북
– 이 노트북은 여러 XGBoost 모델을 엔드포인트에 배포하는 방법을 보여줍니다. -
다중 모델 엔드포인트 BYOC 샘플 노트북
- 이 노트북은 SageMaker AI에서 다중 모델 엔드포인트를 지원하는 고객 컨테이너를 설정하고 배포하는 방법을 보여줍니다.
-
-
GPU 기반 인스턴스를 사용하는 다중 모델 엔드포인트의 예제:
-
Amazon SageMaker AI 다중 모델 엔드포인트(MME)를 사용하여 GPU에서 다중 딥 러닝 모델 실행
– 이 노트북은 NVIDIA Triton Inference 컨테이너를 사용하여 ResNet–50 모델을 다중 모델 엔드포인트에 배포하는 방법을 보여줍니다.
-
SageMaker AI에서 이전 예시의 실행에 사용할 수 있는 Jupyter Notebook 인스턴스를 만들고 액세스하는 방법은 Amazon SageMaker 노트북 인스턴스 섹션을 참조하세요. 노트북 인스턴스를 만들고 연 후 SageMaker AI 예시 탭을 선택하여 모든 SageMaker AI 예시 목록을 볼 수 있습니다. 다중 모델 엔드포인트 노트북은 ADVANCED FUNCTIONALITY(고급 특성) 섹션에 있습니다. 노트북을 열려면 사용 탭을 선택한 후 사본 생성을 선택합니다.
다중 모델 엔드포인트의 사용 사례에 대한 자세한 내용은 다음 블로그 및 리소스를 참조하세요.
-
사례 연구: Veeva Systems
