기계 번역으로 제공되는 번역입니다. 제공된 번역과 원본 영어의 내용이 상충하는 경우에는 영어 버전이 우선합니다.
Object2Vec 작동 방식
Amazon SageMaker AI Object2Vec 알고리즘을 사용하는 경우 표준 워크플로를 따릅니다. 즉, 데이터를 처리하고, 모델을 훈련하고, 추론을 생성합니다.
1단계: 데이터 처리
사전 처리 중에 데이터를 Object2Vec 훈련을 위한 데이터 형식에서 지정한 JSON 행np.random.shuffle을 사용할 수 있고, Unix의 경우 shuf를 사용할 수 있습니다.
2단계: 모델 훈련
SageMaker AI Object2Vec 알고리즘에는 다음과 같은 주요 구성 요소가 있습니다.
-
입력 채널 2개 - 입력 채널은 동일하거나 다른 유형의 객체 쌍을 입력으로 가져와 독립적이고 사용자 지정 가능한 인코더에 전달합니다.
-
인코더 2개 - 2개의 인코더 enc0 및 enc1이 각 객체를 고정된 길이의 임베딩 벡터로 변환합니다. 페어 내 객체의 인코딩된 임베딩은 비교기로 전달됩니다.
-
비교기 - 비교기는 임베딩을 여러 방식으로 비교하여 페어 객체 간의 관계 강도를 나타내는 점수를 출력합니다. 문장 페어의 출력 점수에서 예를 들어 1은 문장 페어 간의 강한 관계를 나타내고, 0은 약한 관계를 나타냅니다.
훈련 중 이 알고리즘은 객체 쌍 및 그 관계 레이블이나 점수를 입력으로 수락합니다. 앞서 설명한 대로 각 페어의 객체는 유형이 다를 수 있습니다. 두 인코더 모두의 입력이 동일한 토큰 수준 단위로 구성된 경우 훈련 작업을 생성할 때 tied_token_embedding_weight 하이퍼파라미터를 True로 설정하여 공유 토큰 임베딩 계층을 사용할 수 있습니다. 예를 들어 모두가 단어 토큰 수준 단위를 가지는 문장을 비교할 때 이것이 가능합니다. 지정된 비율로 음수 샘플을 생성하려면 negative_sampling_rate 하이퍼파라미터를 원하는 양수 샘플 대비 음수 샘플 비율로 설정합니다. 이 하이퍼파라미터는 훈련 데이터에서 관찰되는 양수 샘플과 관찰될 가능성이 없는 음수 샘플을 구별하는 학습을 촉진합니다.
객체 페어는 해당 객체의 입력 유형과 호환되는 사용자 지정 가능한 독립적 인코더를 통해 전달됩니다. 인코더는 페어의 각 객체를 길이가 같은 고정된 길이의 임베딩 벡터로 변환합니다. 벡터 페어는 비교기 연산자로 전달되고, 여기서 comparator_list 하이퍼파라미터에 지정된 값을 사용하여 단일 벡터로 연산됩니다. 연산된 벡터는 다중 계층 퍼셉트론(MLP) 계층을 통해 전달되고, 여기서 손실 함수가 생성된 출력을 제공된 레이블과 비교합니다. 이 비교는 모델이 예측한 페어 객체 간 강도를 평가합니다. 다음 그림은 이 워크플로를 보여 줍니다.
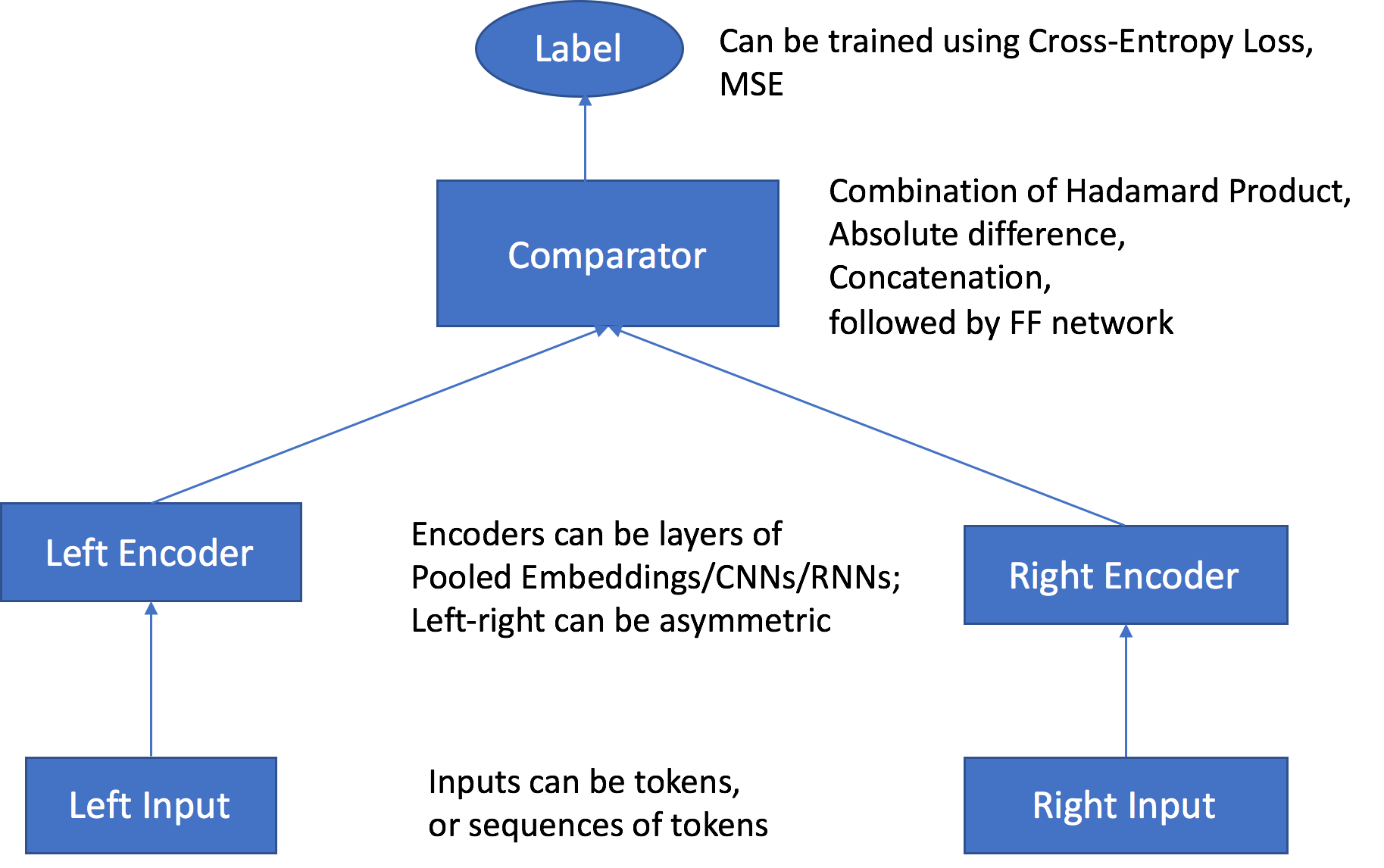
Object2Vec 알고리즘 아키텍처 - 데이터 입력에서 점수까지
3단계: 추론 생성
모델 훈련 후, 훈련된 인코더를 사용하여 입력 객체를 사전 처리하거나 두 가지 유형의 추론을 수행할 수 있습니다.
-
해당 인코더를 사용하여 singleton 입력 객체를 길이가 고정된 임베딩으로 변환
-
쌍을 이루는 입력 객체 간 관계 레이블 또는 점수 예측
추론 서버는 입력 데이터를 기반으로 어떤 유형이 요청되는지 자동으로 파악합니다. 임베딩을 출력으로 가져오려면 입력을 하나만 제공합니다. 관계 레이블 또는 점수를 예측하려면 두 입력을 페어로 제공합니다.
