기계 번역으로 제공되는 번역입니다. 제공된 번역과 원본 영어의 내용이 상충하는 경우에는 영어 버전이 우선합니다.
RCF 작동 방식
Amazon SageMaker AI Random Cut Forest(RCF)는 데이터 세트 내에서 이상 데이터 포인트를 감지하기 위한 비지도 알고리즘입니다. 이는 구조화 또는 패턴화된 데이터로부터 벗어난 관측치입니다. 변칙은 시계열 데이터에서 예기치 않은 급증, 주기성 내의 끊어짐 또는 분류할 수 있는 데이터 지점으로 나타날 수 있습니다. 평면적으로 봤을 때 "정규" 데이터로부터 쉽게 구분할 수 있습니다. 데이터세트에 이러한 변칙이 포함되면 기계 학습 작업의 복잡성이 극적으로 증가할 수 있습니다. "정규" 데이터가 주로 단순한 모델로 설명될 수 있기 때문입니다.
RCF 알고리즘의 기본 개념은 훈련 데이터의 샘플 분할을 사용하여 얻은 각각의 트리를 통해 하나의 포레스트로 만드는 것과 같습니다. 예를 들어 입력 데이터의 임의 샘플이 우선 결정됩니다. 임의 샘플은 이후 포레스트에 있는 트리의 수에 따라 분할됩니다. 각각의 트리에 이러한 분할이 제공되고, 트리는 지점의 하위 세트를 k-d 트리로 구성합니다. 트리별 데이터 지점에 할당된 변칙 점수는 트리의 복잡성에 대한 예상된 변경으로 정의되고 그에 따라 트리에 점수를 추가합니다. 이는 평균적으로 트리 지점의 결과 깊이에 반비례합니다. Random Cut Forest는 각각을 구성하는 트리로부터 평균 점수를 컴퓨팅하고 샘플 크기에 따라 결과를 조정함으로써 이상 점수를 할당합니다. RCF 알고리즘은 참조 [1]에 설명된 것을 기반으로 합니다.
무작위 데이터 샘플링
RCF 알고리즘의 첫 번째 단계는 훈련 데이터의 임의 샘플을 얻는 것입니다. 특히 총 데이터 포인트 개수가
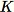 ~
~
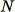 인 크기의 샘플을 원한다고 가정합니다. 훈련 데이터가 충분히 작은 경우 전체 데이터세트를 사용할 수 있고, 이 세트에서
개 요소를 무작위로 가져올 수 있습니다. 하지만 주기적으로 훈련 데이터가 한 번에 일치시키기에 너무 큰 경우 이 접근 방식은 실현 가능하지 않습니다. 대신 리저버 샘플링이라는 기법을 사용합니다.
인 크기의 샘플을 원한다고 가정합니다. 훈련 데이터가 충분히 작은 경우 전체 데이터세트를 사용할 수 있고, 이 세트에서
개 요소를 무작위로 가져올 수 있습니다. 하지만 주기적으로 훈련 데이터가 한 번에 일치시키기에 너무 큰 경우 이 접근 방식은 실현 가능하지 않습니다. 대신 리저버 샘플링이라는 기법을 사용합니다.
리저버 샘플링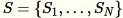 에서 무작위 샘플을 효율적으로 가져오기 위한 알고리즘으로, 여기서 데이터세트의 요소 수는 한 번에 하나씩 또는 배치로만 관측할 수 있습니다. 실제로 리저버 샘플링은
이 선험적인 것으로 알려지지 않은 경우에도 작동합니다. 단 하나의 샘플만이 요청된 경우(예:
에서 무작위 샘플을 효율적으로 가져오기 위한 알고리즘으로, 여기서 데이터세트의 요소 수는 한 번에 하나씩 또는 배치로만 관측할 수 있습니다. 실제로 리저버 샘플링은
이 선험적인 것으로 알려지지 않은 경우에도 작동합니다. 단 하나의 샘플만이 요청된 경우(예:
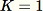 인 경우) 이 알고리즘은 다음과 같습니다.
인 경우) 이 알고리즘은 다음과 같습니다.
알고리즘: 리저버 샘플링
-
입력: 데이터세트 또는 데이터 스트림
-
임의 샘플 초기화
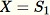
-
각 관측된 샘플
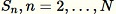 :
:-
균일한 난수 선택
![Equation in text-form: \xi \in [0,1]](images/rcf6.jpg)
-
다음의 경우,
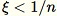
-
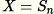 설정
설정
-
-
-
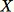 반환
반환
이 알고리즘은 모든
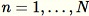 에 대해
에 대해
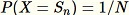 처럼 무작위 샘플을 선택합니다.
처럼 무작위 샘플을 선택합니다.
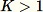 인 경우 알고리즘이 더욱 복잡합니다. 추가로 교체 및 교체되지 않은 임의 샘플링 사이에서 구별해야 합니다. RCF는 [2]에서 설명된 알고리즘을 기반으로 훈련 데이터에서 교체 없이 증강된 리저버 샘플링을 수행합니다.
인 경우 알고리즘이 더욱 복잡합니다. 추가로 교체 및 교체되지 않은 임의 샘플링 사이에서 구별해야 합니다. RCF는 [2]에서 설명된 알고리즘을 기반으로 훈련 데이터에서 교체 없이 증강된 리저버 샘플링을 수행합니다.
RCF 모델 훈련 및 추론 생성
RCF의 다음 단계는 임의 데이터 샘플을 사용하여 Random Cut Forest를 생성하는 것입니다. 우선 샘플은 포레스트에 있는 트리의 수와 동일한 파티션으로 분할됩니다. 이후 각 분할은 개별 트리로 전송됩니다. 트리는 데이터 도메인을 경계가 있는 상자로 분할하여 재귀적으로 분할을 하나의 바이너리 트리로 구성합니다.
이 절차가 예제와 함께 가장 잘 설명되었습니다. 트리에게 다음 2차원 데이터세트가 제공된다고 가정합니다. 해당 트리는 루트 노드로 초기화됩니다.
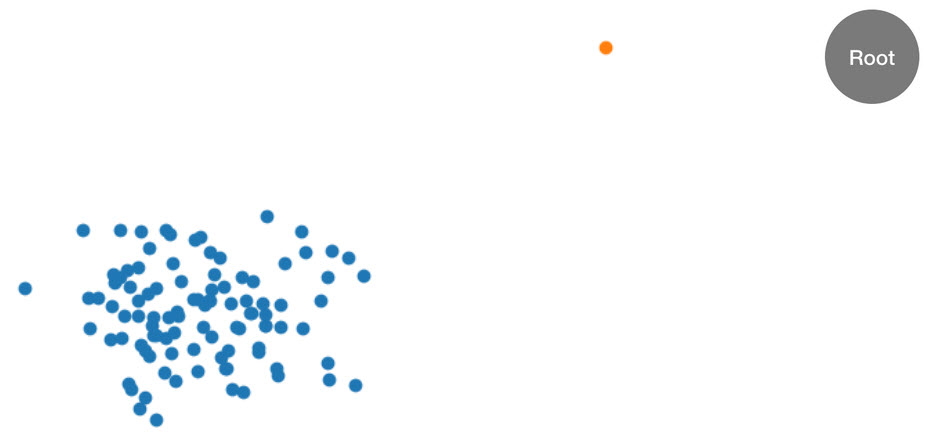
그림: 대부분의 데이터는 클러스터(파란색)에 있지만 하나의 변칙 데이터 지점(주황색)이 있는 2차원 데이터세트. 트리는 루트 노드로 초기화됩니다.
RCF 알고리즘은 데이터의 경계 상자를 컴퓨팅하고, 임의 차원을 선택하고("변수"가 더 높은 차원에 더 많은 가중치 제공), 해당 차원을 통과하는 초평면의 위치를 임의로 결정하여 트리의 데이터를 구성합니다. 결과로 나온 두 가지 하위 공간은 고유한 하위 트리를 정의합니다. 이 예제에서 샘플의 나머지로부터 단일 지점이 분할됩니다. 결과로 나온 바이너리 트리의 첫 번째 층에는 2개의 노드가 있습니다. 하나는 최초 분할의 왼쪽을 가리키는 하위 트리를 포함하고, 다른 하나는 오른쪽에 있는 단일 지점을 나타냅니다.
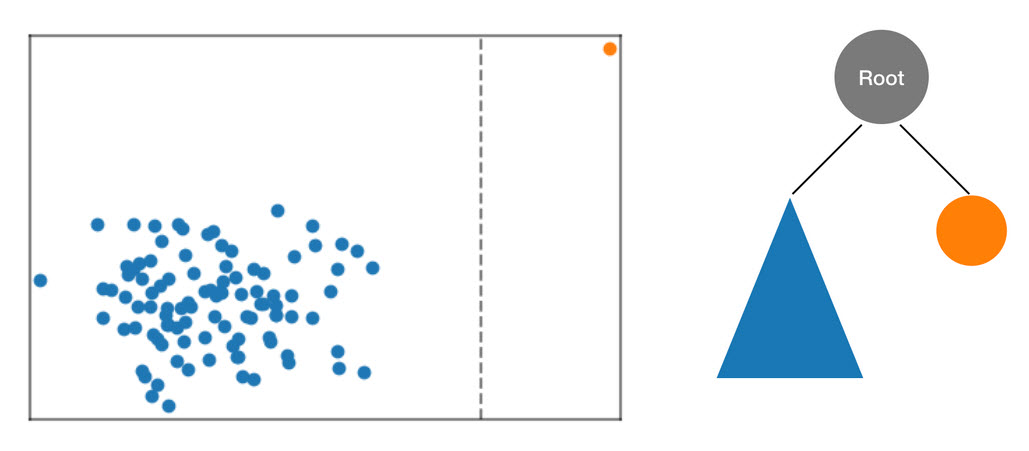
그림: 2차원 데이터세트의 임의 분할. 변칙 데이터 지점은 다른 지점에 비해 작은 트리에 있는 경계 상자에 고립될 가능성이 높습니다.
경계 상자는 데이터의 왼쪽과 오른쪽 절반에 대해 컴퓨팅되고, 트리의 모든 리프가 샘플로부터 단일 데이터 지점을 나타낼 때까지 반복됩니다. 단일 지점이 효율적으로 멀리 떨어진 경우 임의 분할로 인해 지점 고립이 발생할 수 있습니다. 이 관측치는 트리의 깊이가 변칙 점수에 반비례한다는 직관을 제공합니다.
교육된 RCF 모델을 사용하여 추론을 수행할 때 최종 변칙 점수는 각 트리에 보고된 평균 점수에 따라 보고됩니다. 새 데이터 지점이 이미 트리 내에 존재하지 않는 경우도 있습니다. 새 지점과 연결된 점수를 확인하기 위해 데이터 지점이 특정 트리에 삽입됩니다. 그리고 트리는 효율적으로(그리고 일시적으로) 위에 설명한 훈련 프로세스와 동일한 방식으로 재결합됩니다. 결과로 나온 트리는 입력 데이터 지점이 처음 트리를 생성하는 데 사용하는 샘플의 멤버입니다. 보고된 점수는 트리 내 입력 지점의 깊이와 반비례합니다.
하이퍼파라미터 선택
RCF 모델 조정에 사용되는 기본 하이퍼파라미터는 num_trees 및 num_samples_per_tree입니다. num_trees가 증가하면 변칙 점수에 관측된 노이즈가 감소합니다. 최종 점수가 각 트리에서 보고하는 점수의 평균이기 때문입니다. 최적값은 사례에 따라 다르기 때문에 점수 노이즈 및 모델 복잡성 사이의 균형을 위해 100개의 트리를 사용하여 시작하는 것이 좋습니다. 추론 시간은 트리의 수에 비례합니다. 훈련 시간이 영향을 받기는 하지만 위에 설명하는 리저버 샘플링 알고리즘이 주를 이룹니다.
파라미터 num_samples_per_tree는 데이터세트의 예상 변칙 밀도와 관련이 있습니다. 특히 num_samples_per_tree가 정상 데이터 대비 변칙 데이터의 비율을 계산하도록 1/num_samples_per_tree를 선택해야 합니다. 예를 들어 각 트리에서 256개의 샘플을 사용하는 경우 데이터에 1/256, 0.4%의 변칙이 있다고 예상합니다. 이번에도 이 하이퍼파라미터의 최적값은 애플리케이션에 따라 다릅니다.
참조
-
Sudipto Guha, Nina Mishra, Gourav Roy, and Okke Schrijvers. "Robust random cut forest based anomaly detection on streams." In International Conference on Machine Learning, pp. 2712-2721. 2016.
-
Byung-Hoon Park, George Ostrouchov, Nagiza F. Samatova, and Al Geist. "Reservoir-based random sampling with replacement from data stream." In Proceedings of the 2004 SIAM International Conference on Data Mining, pp. 492-496. Society for Industrial and Applied Mathematics, 2004.
