This whitepaper is for historical reference only. Some content might be outdated and some links might not be available.
AWS for data
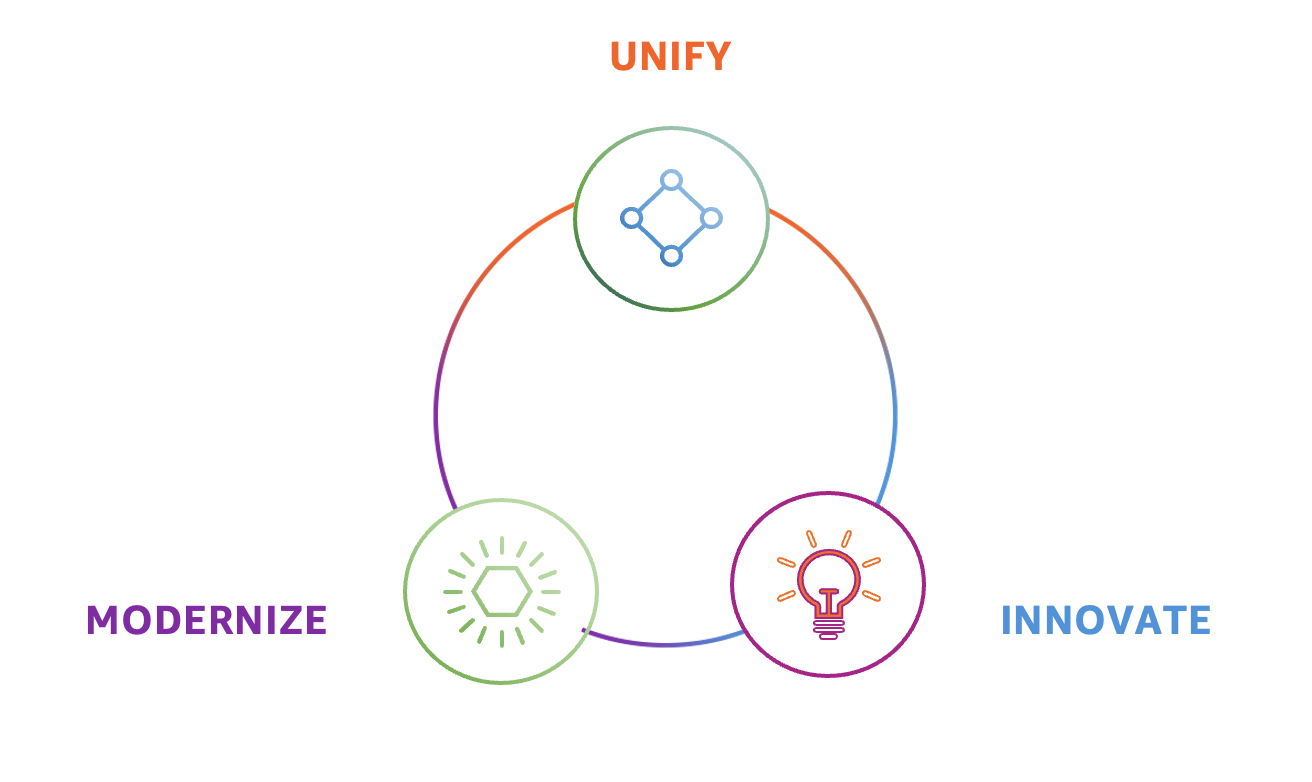
There are three different stages to building a modern data strategy. These stages are not sequential, and you can start at any stage, depending on your data journey.
-
Modernize — You can modernize your data infrastructure with the most scalable, trusted, and secure cloud provider.
-
Unify — You can unify your data by putting it to work in the best data lakes and purpose-built data stores.
-
Innovate — You can create new experiences and reimagine old processes with AI and ML.
These three stages in turn lead to the development of a modern data strategy on AWS, as illustrated in the following figure. This strategy gives you the best of both data lakes and purpose-built stores. It enables you to store any amount of data at a low cost, and in open-standards data formats. This helps you avoid the risks of getting locked into a proprietary format. It helps you break down data silos and empower your teams to run analytics or ML at scale, using your preferred tools and techniques.
Modern data strategy on AWS
Modern data architecture
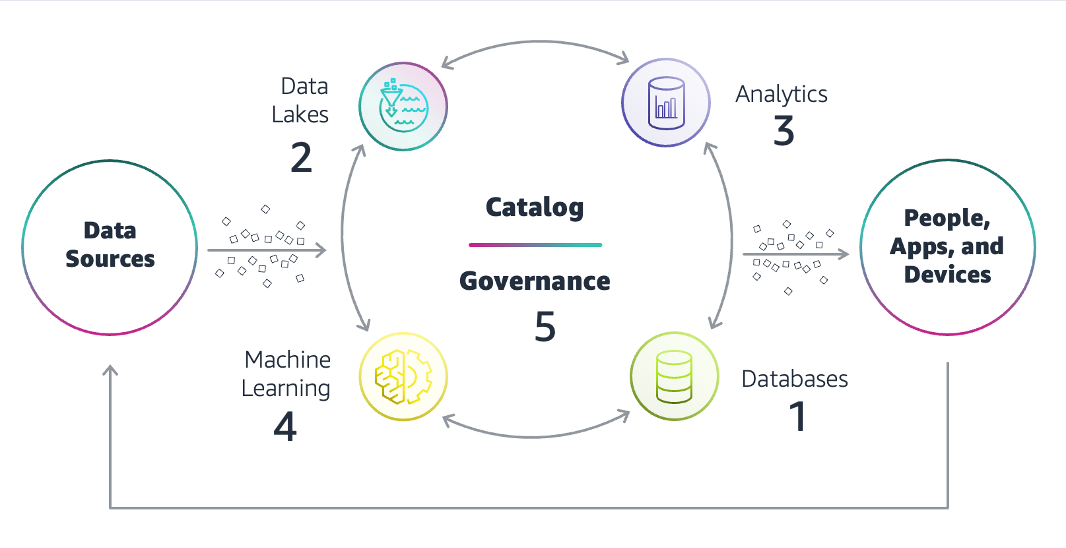
AWS modern data architecture connects your data lake, your data warehouse, and all other purpose-built stores into a coherent whole. The following figure depicts a modern data architecture on AWS.
Modern data architecture on AWS
Key:
-
Store data in a purpose-built database that can support a modern application and its different features. It no longer needs to be a single type of relational database, but could be a NoSQL database, cache store, or anything else which works for the application. The focus is on application empowerment, not analytics.
-
Use the data lake, which uses a storage service such as Amazon Simple Storage Service
(Amazon S3), to store data from all those purpose-built databases and native open-file formats. Open formats give more power to organizations to use the data however they need to. -
Once the data lake is hydrated with data, you can build analytics of any kind easily, and use any technology customers want to use for their use cases. This can range from traditional data warehousing and batch reporting to more near real-time alerting and reporting. This can even be ad-hoc querying of data, or more advanced ML-based analytics use cases. Data is now stored in a layer that’s more open and provides more freedom of analytics choices.
-
ML and AI are also critical for a modern data strategy, to help you predict what will happen in the future, and to build intelligence into your systems and applications. Customers have varied needs when it comes to AI/ML, and require a broad set of AI/ML services. This is true for expert ML practitioners, for everyday developers, and for customers who don’t want to build and train models.
-
Finally, data governance is a critical element to combining and sharing data from different sources so you can put data in the hands of people at all levels of your organization. There are data residency compliance needs which come with globalization. There is need for granular control over who has permission to access data, and standard security needs such as encryption, auditability, monitoring, alerting, and so on.
Purpose-built databases
Organizations are breaking free from legacy databases. They are moving to fully managed databases and analytics, modernizing data warehouse databases, and building modern applications with purpose-built databases to get more out of their data. Organizations want to move away from old-guard databases because they are expensive, proprietary, lock you in, offer punitive licensing terms, and come with frequent audits from their vendors. Organizations that are moving to open-source databases are looking for the performance of commercial-grade databases with the pricing, freedom, and flexibility of open-source databases.
AWS provides purpose-built database services to overcome these
challenges with on-premises database solutions. The most
straightforward and simple solution for many organizations that
are struggling to maintain their own relational databases at scale
is a move to a managed database service, such as
Amazon Relational Database Service
Many organizations also use non-relational databases such as
MongoDB and Redis as document and in-memory databases for use
cases such as content management, personalization, mobile apps,
catalogs, and near real-time use cases such as caching, gaming
leaderboards, and session stores. The most straightforward and
simple solution for many organizations who are struggling to
maintain their own non-relational databases at scale is a move to
a managed database service (for example, moving self-managed
MongoDB databases to Amazon DocumentDB or moving self-managed
in-memory databases such as Redis and ElastiCache to
Amazon ElastiCache
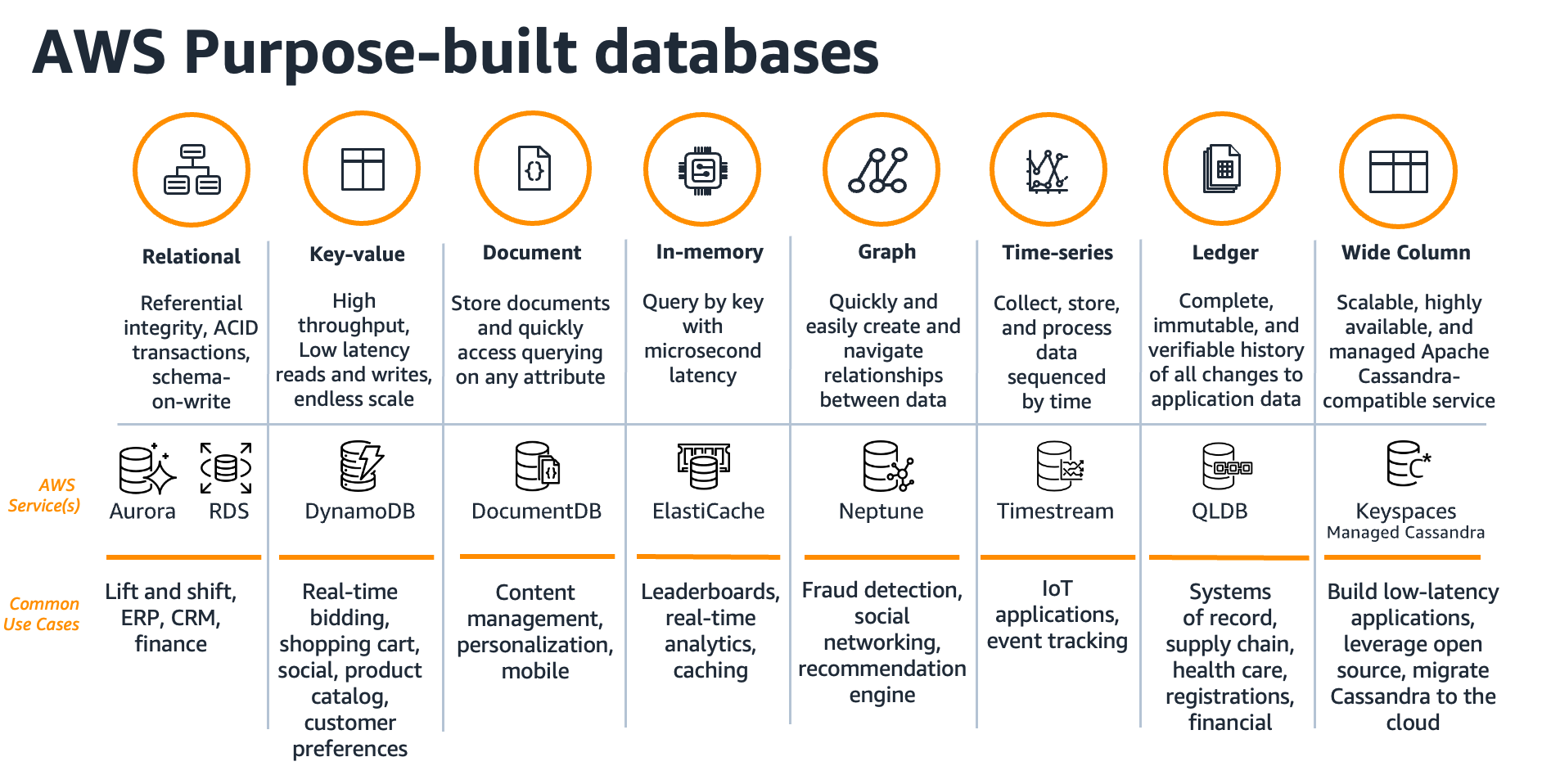
Purpose-built database services on AWS
Purpose-built data analytics services
Purpose-built data analytics services enable you to use the right tool for the right job, and provides the agility to iteratively and incrementally build out the modern data architecture. You gain the flexibility to evolve the data lake house to meet current and future needs as you add new data sources, discover new use cases and their requirements, and develop newer analytics methods.
AWS provides a portfolio of purpose-built data analytics services,
which include AWS Glue
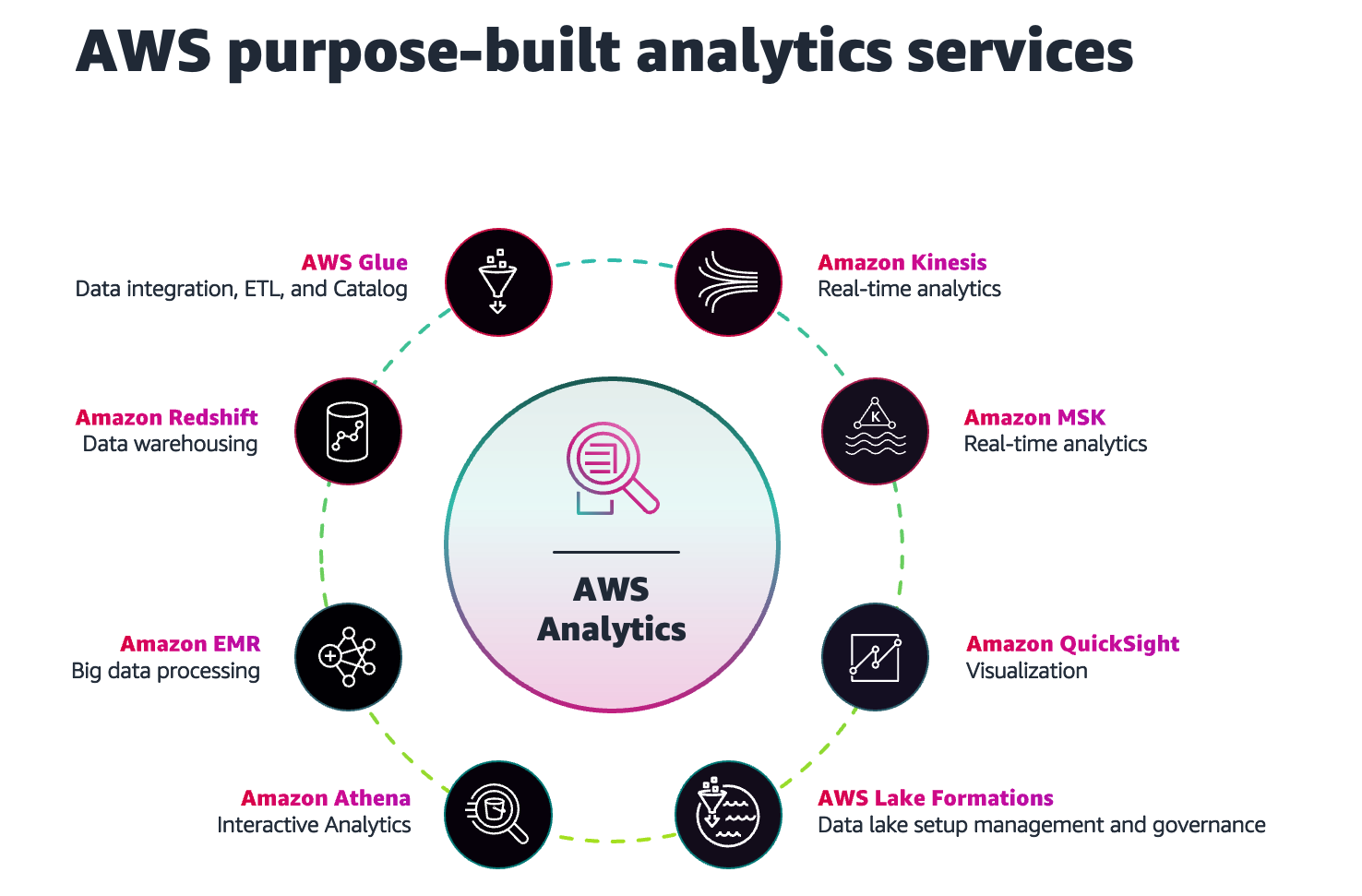
Purpose-built data analytics services on AWS
ML and AI services
In the past, ML technology was limited to a few major tech companies and hardcore academic researchers, but things began to change when cloud computing entered into the mainstream. Compute power and data became more available, and ML is now making an impact across almost every industry, including finance, retail, fashion, real estate, healthcare, and more. ML is moving from the peripheral to a core part of most every business and industry. In time, virtually every application will be infused with ML and AI.
AWS provides the broadest and deepest set ML and AI services, in three different levels, for builders of all levels of expertise in their ML journey:
-
For expert practitioners, AWS supports all the major ML frameworks ,including TensorFlow, MXNet, PyTorch, Caffe 2, and so on. We offer the highest performance instances for ML training in the cloud with Amazon EC2 P4d instances, powered by the latest NVIDIA A100 Tensor Core GPUs, and coupled with first-in-the-cloud 400 Gbps instance networking. P4d instances are deployed in hyperscale clusters, called EC2 UltraClusters
, offering supercomputer-class performance for the most complex ML training jobs. For inference, which represents 90% of the cost of ML, we provide the lowest cost for ML inference in the cloud with Amazon EC2 Inf1 instances , powered by AWS Inferentia chips . -
For data scientists and ML developers, AWS provides Amazon SageMaker AI
. SageMaker AI was built from the ground up to simplify the process of ML with tools for every step of the ML development, including labeling, data preparation, feature engineering, statistical bias detection, auto-ML, training, tuning, hosting, explainability, monitoring, and workflows. -
For developers and business users, AWS provides pre-trained AI services that provide ready-made intelligence for applications and workflows, and end-to-end solutions that can solve business needs right out of the box using AutoML technology. These services address common use cases such as personalized recommendations, contact center intelligence, document processing, intelligent search, business metrics analysis, and more. AWS also provides industry-specific AI services for both industrial and healthcare industries.
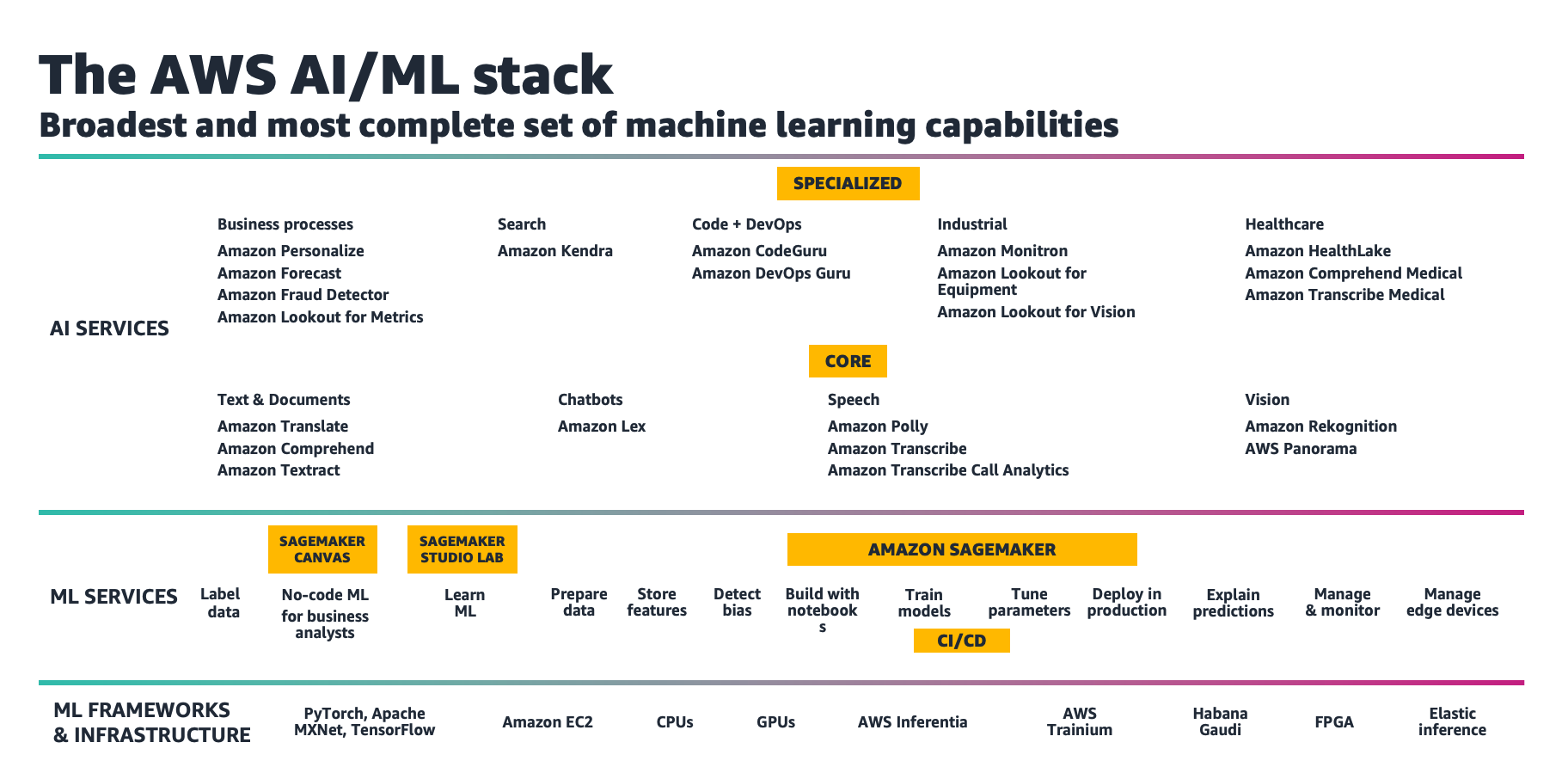
AWS ML and AI services
