Parsing logs and structured logging
Many developers use unstructured logging in their Lambda functions by using commands such as Python’s print
In the logsInsightsUnstructured example, this function generates an unstructured log line with an embedded value. Over multiple invocations, this appears as follows in CloudWatch Logs:

You can use the parse command in CloudWatch Logs Insights to extract data from a log field for further processing, by using either a glob or regular expression. In the example, the following query extracted the UploadedBytes value and then uses this to create minimum, maximum and average statistics:

While this approach is useful for handling logs from existing systems that may be difficult to change, it can be time-consuming and awkward to build custom parsing filters for each type of unstructured log file. To apply monitoring to production systems, it’s generally easier to implement structured logging throughout your applications. You can achieve this in Python with libraries like structlog
Using log levels is an important first step in generating filter-friendly logs files that separate informational messages from warnings or errors. The logsInsightsLogLevels example shows the effect of providing log levels in Node.js with this code:
exports.handler = async (event) => {
console.log("console.log - Application is fine")
console.info("console.info - This is the same as console.log")
console.warn("console.warn - Application provides a warning")
console.error("console.error - An error occurred")
}The CloudWatch log file contains a separate field specifying the log level:

A CloudWatch Logs Insights query can then filter on log level, making it simpler to generate queries based only on errors, for example:
fields @timestamp, @message | filter @message like /ERROR/ | sort @timestamp desc
JSON is commonly used to provide structure for application logs. In the logsInsightsJSON example, the logs have been converted to JSON to output three distinct values. The output now looks like:

The CloudWatch Logs Insights feature automatically discovers values in JSON output and parses the messages as fields, without the need for custom glob or regular expression. By using the JSON-structured logs, the following query finds invocations where the uploaded file was larger than 1 MB, the upload time was more than 1 second, and the invocation was not a cold start:
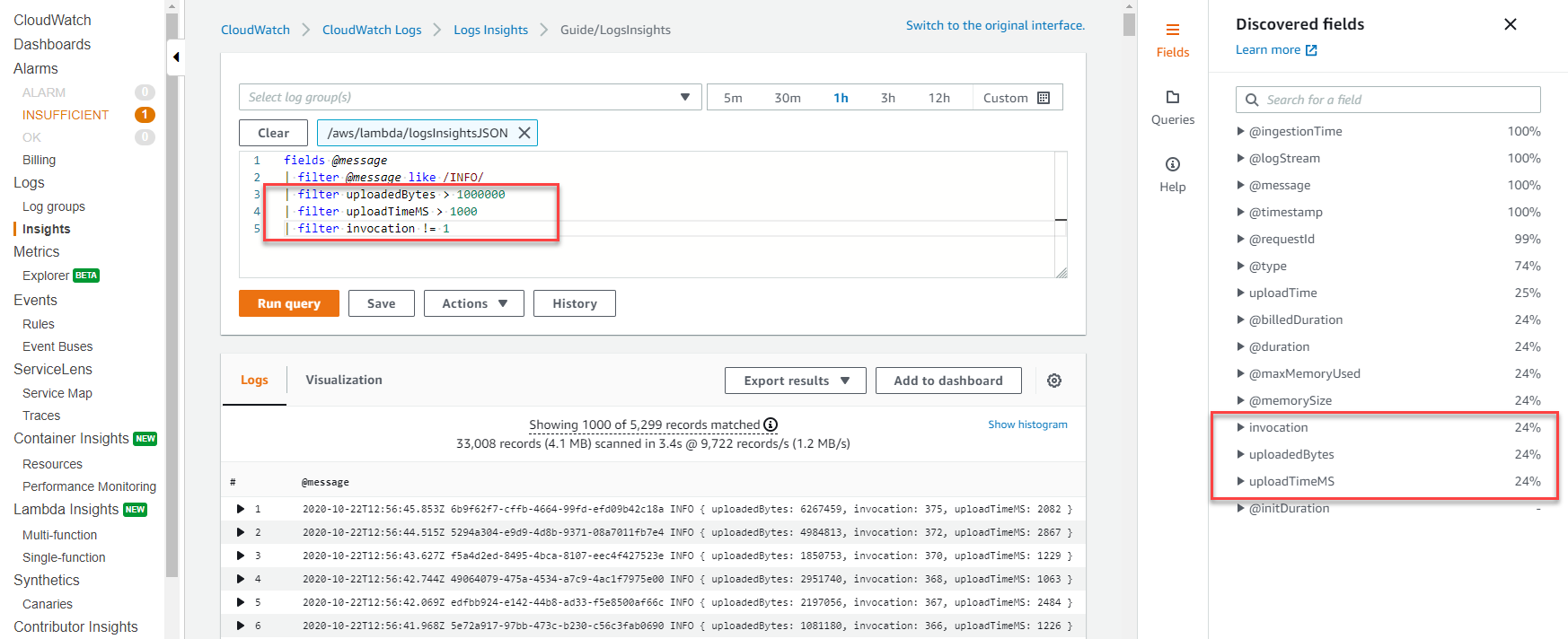
The discovered fields in JSON are automatically populated on the Fields drawer on the right side. Standard fields emitted by the Lambda service are prefixed with '@' and you can query on these fields in the same way. Lambda logs always include the fields @timestamp, @logStream, @message, @requestId, @duration, @billedDuration, @type, @maxMemoryUsed, @memorySize. If X-Ray is enabled for a function, logs also include @xrayTraceId and @xraySegmentId.
