Basic reasoning agents
A basic reasoning agent is the simplest form of agentic AI that performs logical inference or decision-making in response to a query. It accepts input from a user or system and processes queries and generates responses using structured prompts.
This pattern is useful for tasks that require single-step reasoning, classification, or summarization based on a given context. It doesn't use memory, tools, or state management, which makes it stateless, lightweight, and highly composable across large workflows.
Architecture
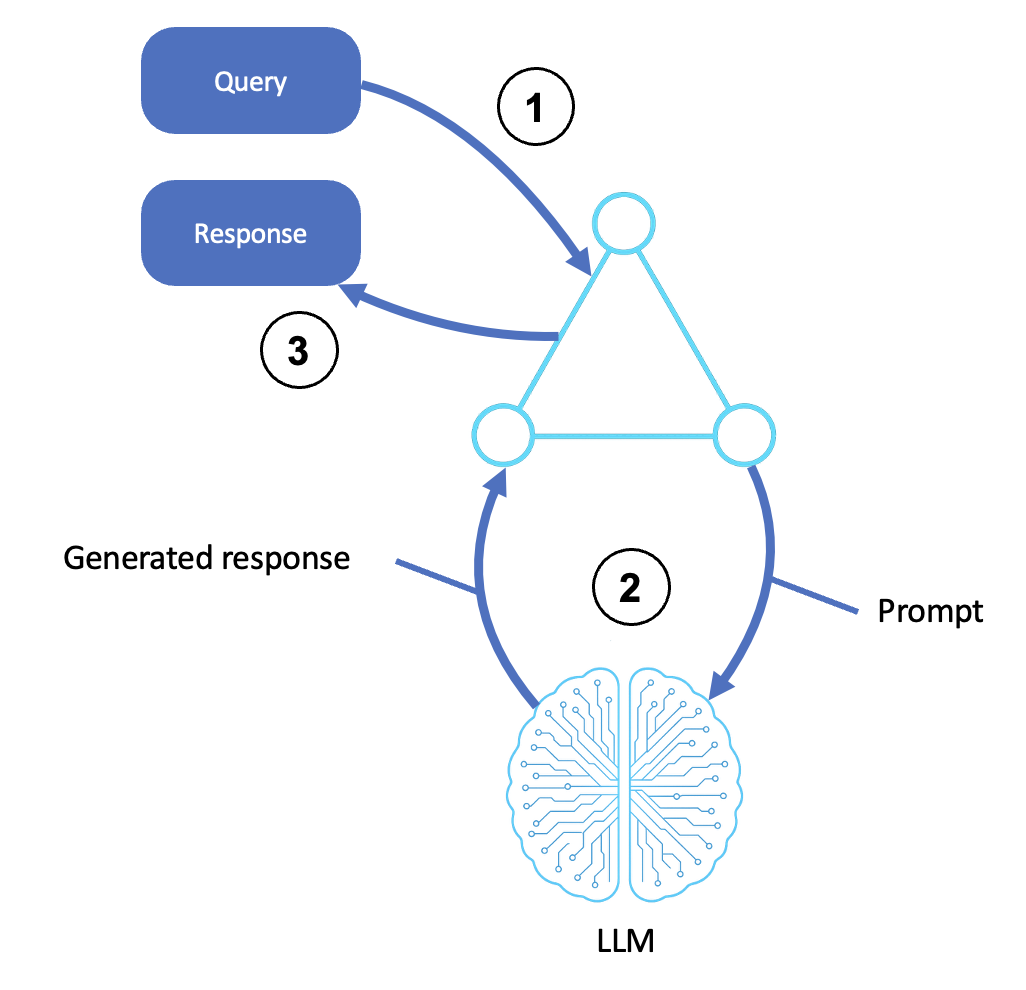
The flow of a basic reasoning agent is shown in the following diagram:
Description
-
Receives an input
-
A user, system, or upstream agent submits a query or instruction.
-
The input is handed off to the agent shell or orchestration layer.
-
This step includes any preprocessing, prompt templating, and goals identification.
-
-
Invokes the LLM
-
The agent transforms the query into a structured prompt and sends it to an LLM (for example, through Amazon Bedrock).
-
The LLM generates a response based on the prompt using pretrained knowledge and context.
-
The generated output may include reasoning steps (chain-of-thought), final answers, or ranked options.
-
-
Returns a response
-
The generated output is relayed to the agent's interface.
-
This may include formatting, postprocessing, or an API response.
-
Capabilities
-
Supports natural language or structured input
-
Uses prompt engineering to guide behavior
-
Stateless and scalable
-
Can be embedded into UI, CLI, APIs, and pipelines
Limitations
-
No memory or historical awareness
-
No interaction with external tools or data sources
-
Limited to what the LLM knows at the time of inference
Common use cases
-
Conversational questions and answers
-
Policy explanations and summaries
-
Guidance for making decisions
-
Lightweight and automated chatbot flows
-
Classification, labeling, and scoring
Implementation guidance
You can use the following tools and services to create a basic reasoning agent:
-
Amazon Bedrock for LLM invocation (Anthropic, AI21, Meta)
-
Amazon API Gateway or AWS Lambda to expose it as a stateless microservice
-
Prompt templates stored in Parameter Store, AWS Secrets Manager, or as code
Summary
The basic reasoning agent is foundational because of its simple structure. It has core capabilities that turn goals into reasoning paths that lead to intelligent outputs. This pattern is often a starting point for advanced patterns, such as tool-based agents and agents that use retrieval-augmented generation (RAG). It's also a reliable and modular component of large workflows.
Agent RAG
Retrieval-augmented generation (RAG) is a technique that combines information retrieval with text generation to create accurate and contextual responses. RAG enables agents to retrieve relevant external information before engaging the LLM. It extends an agent's effective memory and reasoning accuracy by grounding its decisions in up-to-date, factual, or domain-specific information. In contrast to stateless LLMs that rely solely on pretrained weights, RAG has an external knowledge search layer that dynamically enhances prompts with context.
Architecture
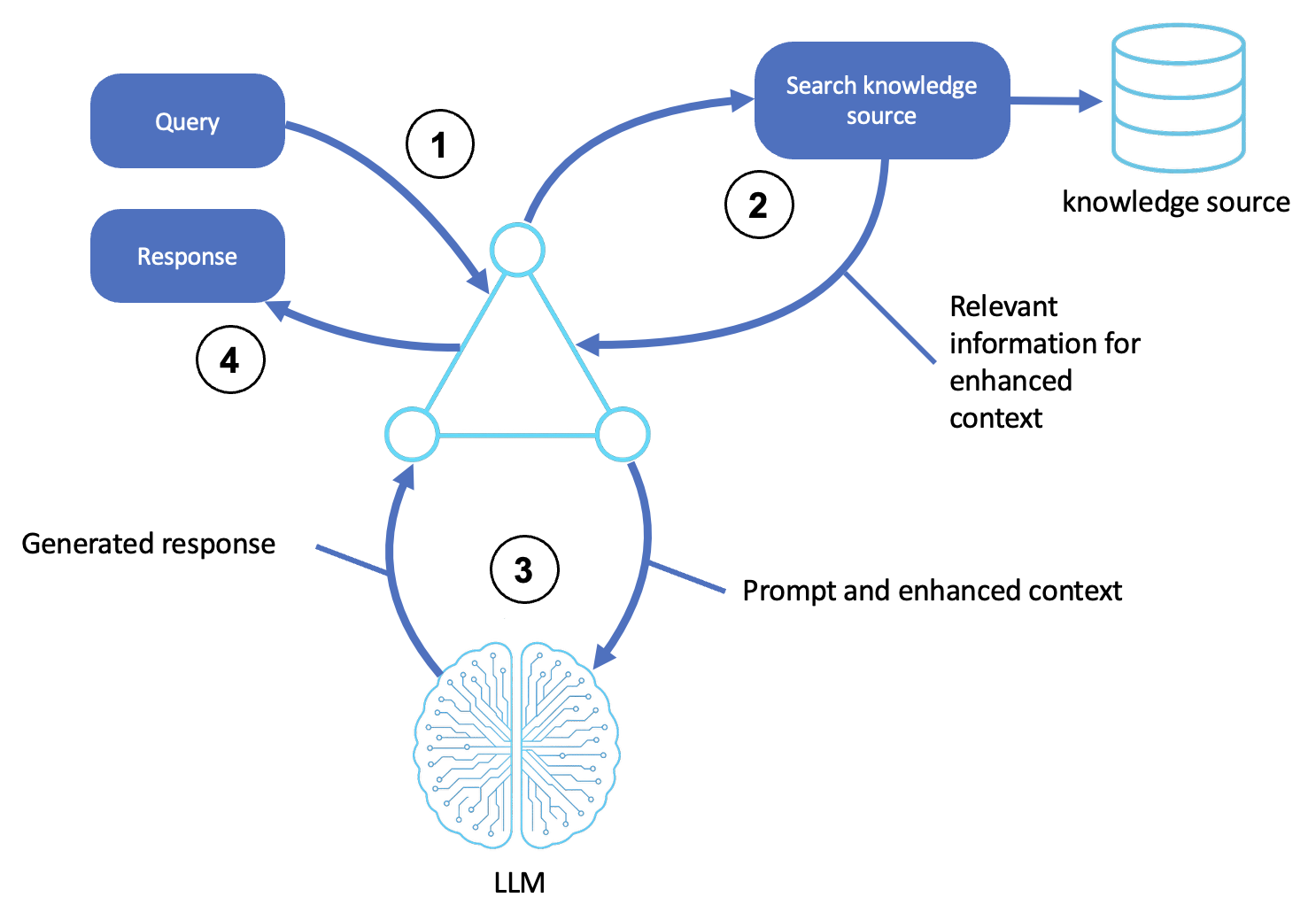
The logic of the RAG pattern is illustrated in the following diagram:
Description
-
Receives a query
-
A user or upstream system submits a query or goal to the agent.
-
The agent shell accepts the request and formats it as a prompt for reasoning.
-
-
Searches an external source
-
The agent identifies concepts and intent from the query.
-
It queries a knowledge source, such as a vector store, database, or document index using semantic search or keyword matching.
-
The most relevant passages, documents, or entities are retrieved for use in the next step.
-
-
Generates a contextual response
-
The agent augments the prompt with the retrieved information, forming a context-enhanced input for the LLM.
-
The LLM processes any inputs using generative reasoning (for example, chain-of-thought or reflection) to produce an accurate response.
-
-
Returns the final output
-
The agent prepares the output by wrapping it in any communication headers or required formatting and then returns it to the user or calling system.
-
(Optional) The retrieved documents and LLM output may be logged, scored, and stored in memory for future queries.
-
Capabilities
-
Fact-grounded output even in long-tail or enterprise-specific domains
-
Memory extension without fine-tuning the model
-
Dynamic context based on each query and user state
-
Fully compatible with vector databases, semantic indexes, and metadata filtering
Common use cases
-
Enterprise knowledge assistants
-
Regulatory compliance bots
-
Customer support copilots
-
Search-enhanced chatbots
-
Developer documentation agents
Implementation guidance
Use the following tools and services to create an agent that uses RAG:
-
Amazon Bedrock for LLM invocation
-
Amazon Kendra, OpenSearch, or Amazon Aurora for documentation or a structured data search
-
Amazon Simple Storage Service (Amazon S3) for document storage
-
AWS Lambda to orchestrate search, prompt, and LLM inference
-
Knowledge-based integrations with agents (by using memory plugins, semantic retrievers, or Amazon Bedrock)
Summary
Agent RAG connects static model reasoning to dynamic, real-world intelligence. It equips agents with the ability to look up what they don't know, synthesize answers from retrieved knowledge, and produce high-confidence, auditable responses.
RAG patterns are a foundation for building intelligent agents that scale knowledge access without retraining. It is often a precursor to more complex orchestration patterns involving tool use, planning, and long-term memory.
