Parallelization and scatter-gather patterns
Many advanced reasoning and generation tasks – such as summarizing large documents, evaluating multiple solution paths, or comparing diverse perspectives – benefit from the parallel execution of prompts. Traditional sequential workflows fall short when scalability, responsiveness, and fault tolerance are required. To overcome this, LLM-based parallelization can be reimagined using an event-driven scatter-gather pattern, where tasks are dynamically fanned out to autonomous agents and results intelligently synthesized.
The following diagram is an example of an LLM parallelization workflow:

Scatter-gather
In distributed systems, a scatter-gather pattern sends tasks to multiple services or processing units in parallel, waits for their responses, and then aggregates results into a consolidated output. Unlike fan-out, scatter-gather is coordinated because it expects responses and usually applies logic to combine, compare, and select results.
Common implementations for parallelization and scatter-gather include the following:
-
AWS Step Functions map a state for parallel task execution
-
AWS Lambda with concurrency, coordinating results from multiple invoked functions
-
Amazon EventBridge with correlation IDs and aggregation workflows
-
Custom controller pattern to manage fan-out and gather results by using Amazon Simple Storage Service (Amazon S3), Amazon DynamoDB, or queues
The following diagram is an example of scatter-gather:
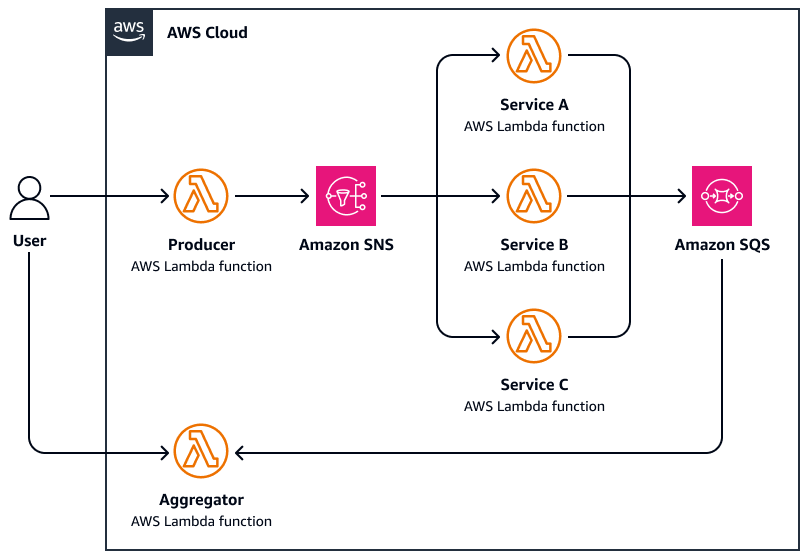
-
A user sends a request to a central coordinator function that scatters the task by publishing parallel messages to an Amazon Simple Notification Service (Amazon SNS) topic.
-
Each message includes task metadata and is routed to a specialized worker AWS Lambda.
-
Each worker AWS Lambda independently processes its assigned subtask (for example, querying an external API, processing a document, and analyzing data).
-
Results are written to a common storage layer, such as Amazon Simple Queue Service (Amazon SQS).
-
The aggregator function waits for all responses to be completed, and then it does the following:
-
Gathers and aggregates the results (for example, merges summaries, selects best matches)
-
Sends a final response or triggers a downstream workflow
-
Common use cases for scatter-gather patterns include the following:
-
Federated search
-
Price comparison engines
-
Aggregated data analysis
-
Multimodel inference
LLM-based parallelization (scatter-gather cognition)
In agentic systems, parallelization closely mirrors scatter-gather by distributing subtasks across multiple LLM calls or agents, each independently reasoning through a portion of the problem. Returned results are gathered and synthesized by an aggregation process, which is often another LLM or controller agent.
Agent parallelization
-
An agent submits a request "Summarize insights across these 10 reports."
-
It scatters the reports to 10 parallel LLM summarization tasks.
-
When it returns all summaries, the agent does the following:
-
Aggregates summaries into a unified briefing
-
Identifies themes or contradictions
-
Sends the synthesized output to the user
-
This agentic workflow enables scalable, modular, and adaptive parallel reasoning. This is ideal for use cases that require high cognitive throughput.
The following diagram is an example of agent parallelization:

-
A user submits a multipart query or document set.
-
A controller AWS Lambda or step function distributes the subtasks. Each task invokes an Amazon Bedrock LLM call or subagent with its own prompt.
-
When the calls and subtasks are complete, results are stored (for example, in Amazon S3 or memory store), and an aggregation step merges, compares, or filters the outputs.
-
The system returns the final response to the user or downstream agent.
This system has a distributed reasoning loop with traceability, fault tolerance, and optional result weighting or selection logic.
Takeaways
Agentic parallelization uses scatter-gather patterns to distribute LLM tasks, enabling parallel processing and intelligent result synthesis.
