Aurora states and Step Functions state machines
This section covers the process and state machines specific to failing over and failing back Amazon Aurora clusters. The clusters are configured as a global database.
Note
For demonstration purposes, this example uses Aurora MySQL-Compatible Edition. You can use similar steps for Aurora PostgreSQL-Compatible Edition.
Steady state
In the steady state, an Amazon Aurora MySQL-Compatible global database
(dr-globaldb-cluster-mysql) has been created with two DB clusters. The first DB
cluster (db-cluster-01) has been created in the primary AWS Region
(us-east-1) to serve the read/write workload. The second DB cluster
(db-cluster-02) has been created in the
secondary Region (us-west-2) to server the read-only workload.
In addition to providing the DR solution, you can reduce the load on your primary DB
cluster by routing read queries from your applications to the secondary DB cluster. Each of
these clusters contains one database instance called dbcluster-01-use1-instance-1
and dbcluster-02-usw2-instance-2, respectively.
Event state
By using an Amazon Aurora global database, you can plan for and recover from disaster fairly quickly. Recovery from disaster is typically measured using values for recovery time objective (RTO) and recovery point objective (RPO). For more information, see Using switchover or failover in an Amazon Aurora global database.
With an Aurora global database, there are two different approaches to failover:
-
Switchover (managed planned failover)
-
Failover (manual unplanned failover, or detach and promote)
Switchover
Switchover is intended for controlled environments, such as operational maintenance and other planned operational procedures. By using a managed planned failover, you can relocate the primary DB cluster of your Aurora global database to one of the secondary Regions. Because switchover waits until the secondary DB clusters are synchronized with the primary database, RPO is 0 (no data loss). To learn more, see Performing switchovers for Amazon Aurora global databases.
The dr-orchestrator-stepfunction-FAILOVER state machine is invoked during
the event state to switch your primary cluster over to your chosen
secondary Region (us-west-2).
To perform the switchover, do the following:
-
Sign in to the AWS Management Console.
-
Change the Region to the DR Region (
us-west-2). -
Navigate to Services, and choose Step Functions.
-
Navigate to the
dr-orchestrator-stepfunction-FAILOVERstate machine. -
Choose Start execution, and enter the following JSON code in the
Input - optionalsection:{ "StatePayload": [ { "layer": 1, "resources": [ { "resourceType": "PlannedFailoverAurora", "resourceName": "Switchover (planned failover) of Amazon Aurora global databases (MySQL)", "parameters": { "GlobalClusterIdentifier": "!Import dr-globaldb-cluster-mysql-global-identifier", "DBClusterIdentifier": "!Import dr-globaldb-cluster-mysql-cluster-identifier" } } ] } ] } -
The
dr-orchestrator-stepfunction-FAILOVERstate machine reads the resource type asPlannedFailoverAuroraMySQL, and it calls thedr-orchestrator-stepfunction-planned-Aurora-failoverstate machine to fail over the Aurora global database.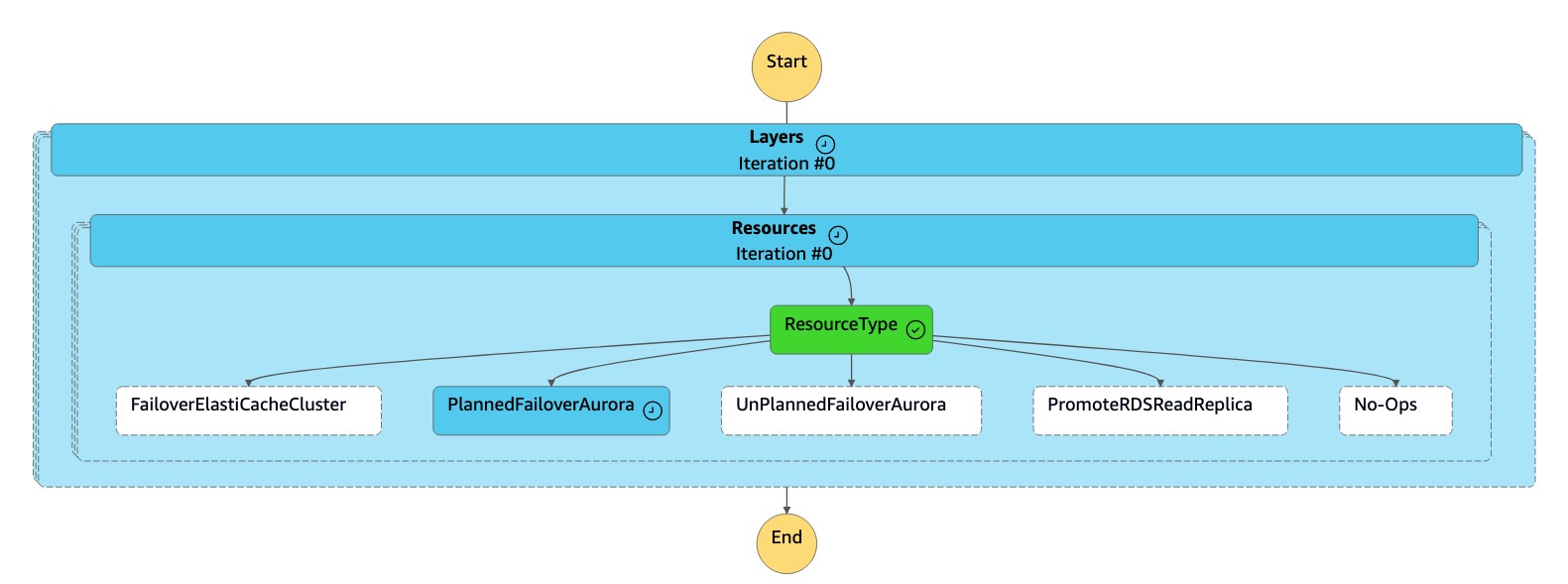
-
The
dr-orchestrator-stepfunction-planned-Aurora-failoverstate machine performs the following steps to switch over the Aurora MySQL-Compatible global database role.
Step Description Expected Values Resolve imports A Lambda function replaces !Import <variable name>values with the actual name."!Import dr-globaldb-cluster-mysql-global-identifier"is replaced by"dr-globaldb-cluster-mysql".Failover Aurora Global Cluster A Lambda function calls failover_global_cluster Boto3 APIs to fail over the Aurora global database. { 'GlobalCluster': { 'GlobalClusterIdentifier': 'dr-globaldb-cluster-mysql', 'GlobalClusterResourceId': 'cluster-cce7f9bec2846db4', 'GlobalClusterArn': 'arn:aws:rds::xxx', 'Status': 'failing-over', .... .... } }Check Failover Status A Lambda function calls describe_db_clusters Boto3 APIs to check the status of the failover. modifying, available Send success tokens A Lambda function calls send_task_success Boto3 APIs and sends a success token back to the DR Orchestrator Failoverstate machine.h7XRiCdLtd/83p1E0dMccoxlzFhglsdkzpK9mBVKZsp7d9yrT1W -
Navigate to the Amazon RDS console. Under Status, the values for the Aurora global database will change from Available to Switching over or Modifying.
-
After the
dr-orchestrator-stepfunction-planned-Aurora-failoverstate machine is completed, it sends a success token back to thedr-orchestrator-stepfunction-FAILOVERstate machine.
-
The
dr-orchestrator-stepfunction-FAILOVERstate machine is completed.
On the console, the role of the Secondary cluster
(dbcluster-02) is now Primary cluster, and the
cluster is ready to serve read/write workloads. The role of the original primary cluster
(dbcluster-01) is now listed as Secondary
cluster.
Manual unplanned failover
On rare occasions, your Aurora global database might experience an unexpected outage in its primary AWS Region. If this happens, your primary Aurora DB cluster and its writer node aren't available, and the replication between the primary cluster and the secondaries ceases. To minimize both downtime (RTO) and data loss (RPO), work quickly to perform a cross-Region failover and reconstruct your Aurora global database. For more information, see Recovering an Amazon Aurora global database from an unplanned outage.
Performing an unplanned failover requires you to detach your secondary cluster from the Aurora global database. Before you perform the unplanned failover, stop application writes on your primary Aurora DB cluster. After the failover is completed successfully, reconfigure the application to write to the new primary DB cluster. This approach helps prevent data loss. It also helps avoid data inconsistencies if the primary writer node comes back online during the failover process.
To perform the unplanned failover, call the
dr-orchestrator-stepfunction-FAILOVER state machine. For this example, the
Secondary cluster
(db-cluster-02) is in the
DR Region (us-west-2) in the steady state.
To perform the failover, do the following:
-
Sign in to the console.
-
Change the Region to the DR Region (
us-west-2). -
Navigate to Services, and choose Step Functions.
-
Navigate to the
dr-orchestrator-stepfunction-FAILOVERstate machine. -
Choose Start execution, and enter the following JSON code in the
Input - optionalsection, usingUnPlannedFailoverAuroraas theresourceType:{ "StatePayload": [ { "layer": 1, "resources": [ { "resourceType": "UnPlannedFailoverAurora", "resourceName": "Performing unplanned failover for Amazon Aurora global databases (MySQL)", "parameters": { "GlobalClusterIdentifier": "!Import dr-globaldb-cluster-mysql-global-identifier", "DBClusterIdentifier": "!Import dr-globaldb-cluster-mysql-cluster-identifier", "ClusterRegion": "!Import dr-globaldb-cluster-mysql-cluster-region" } } ] } ] } -
The
dr-orchestrator-stepfunction-FAILOVERstate machine reads the resource type asUnPlannedFailoverAuroraMySQLand calls the taskDetach Cluster from Global Databasefrom thedr-orchestrator-stepfunction-unplanned-Aurora-failoverstate machine.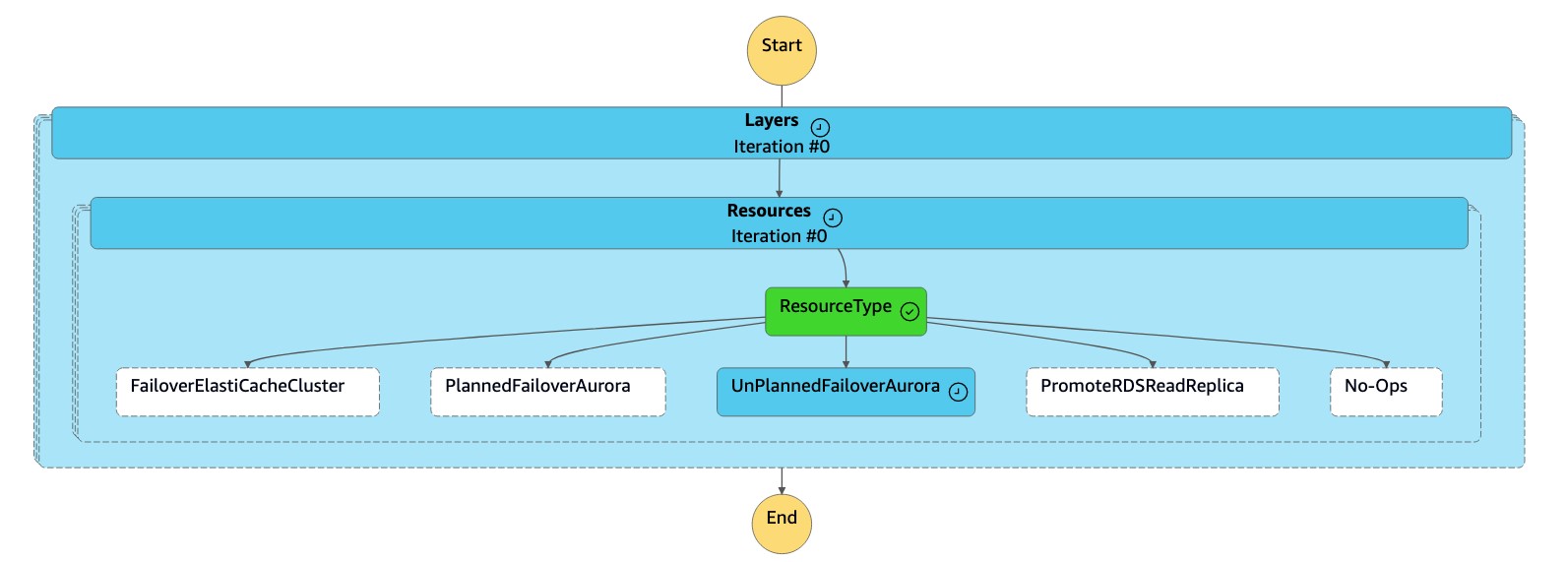
-
The
Detach Cluster from Global Databasetask detaches (removes) the secondary cluster from the global database.
-
The secondary cluster (
dbcluster-02) is promoted to become a standalone cluster, and it can serve read/write workloads. -
The
dr-orchestrator-stepfunction-FAILOVERstate machine is completed.
-
The secondary cluster (
dbcluster-02) is detached from the Aurora global database, and it becomes a standalone cluster to serve the read/writer workload. -
Reconfigure your application to send all write operations to this new standalone Aurora DB cluster by using its new cluster endpoint.
Failback
A failback returns your database to the original (or new) primary location after a disaster (or a scheduled event) is resolved. When the unplanned outage has been resolved, you might want to add your former primary Region back to the Aurora global database. You must first delete the existing DB cluster from the former primary Region, create a new DB cluster from the new primary Region, and then use the managed planned failover process to switch over the new cluster's role.
This can be considered as a planned activity that you can perform during off-peak hours or on a weekend.
You must manually modify the Amazon Aurora DB
Cluster and disable the DeletionProtection before you run the DR Orchestrator FAILBACK state machine from the
former primary Region (us-east-1) because it was created with
DeletionProtection.
DR Orchestrator Framework uses the dr-orchestrator-stepfunction-FAILBACK
state machine to automate the steps to delete the existing cluster and create a new
cluster in the former primary Region.
To disable DeletionProtection, do the following:
-
Sign in to the console.
-
Change the Region to the former primary Region (
us-east-1). -
Navigate to the Amazon RDS console, select the cluster name (
dbcluster-01), and choose Modify. -
Under Deletion protection, clear the Enable deletion protection check box, and choose Continue.
-
Choose Apply immediately, and then choose Modify cluster.
The DR Orchestrator FAILBACK state machine is invoked during the failback
process from the former primary Region (us-east-1).
To perform the failback, do the following:
-
Sign in to the console.
-
Change the Region to the former primary Region (
us-east-1). -
Navigate to Services, and then choose Step Functions.
-
Navigate to the
DR Orchestrator FAILBACKstate machine. -
Choose Start execution, and enter the following JSON code in the
Input - optionalsection:{ "StatePayload": [ { "layer": 1, "resources": [ { "resourceType": "CreateAuroraSecondaryDBCluster", "resourceName": "To create secondary Aurora MySQL Global Database Cluster", "parameters": { "GlobalClusterIdentifier": "!Import dr-globaldb-cluster-mysql-global-identifier", "DBClusterIdentifier": "!Import dr-globaldb-cluster-mysql-cluster-identifier", "DBClusterName": "!Import dr-globaldb-cluster-mysql-cluster-name", "SourceDBClusterIdentifier": "!Import dr-globaldb-cluster-mysql-source-cluster-identifier", "DBInstanceIdentifier": "!Import dr-globaldb-cluster-mysql-instance-identifier", "Port": "!Import dr-globaldb-cluster-mysql-port", "DBInstanceClass": "!Import dr-globaldb-cluster-mysql-instance-class", "DBSubnetGroupName": "!Import dr-globaldb-cluster-mysql-subnet-group-name", "VpcSecurityGroupIds": "!Import dr-globaldb-cluster-mysql-vpc-security-group-ids", "Engine": "!Import dr-globaldb-cluster-mysql-engine", "EngineVersion": "!Import dr-globaldb-cluster-mysql-engine-version", "KmsKeyId": "!Import dr-globaldb-cluster-mysql-KmsKeyId", "SourceRegion": "!Import dr-globaldb-cluster-mysql-source-region", "ClusterRegion": "!Import dr-globaldb-cluster-mysql-cluster-region", "BackupRetentionPeriod": "7", "MonitoringInterval": "60", "StorageEncrypted": "True", "EnableIAMDatabaseAuthentication": "True", "DeletionProtection": "True", "CopyTagsToSnapshot": "True", "AutoMinorVersionUpgrade": "True", "MonitoringRoleArn": "!Import rds-mysql-instance-RDSMonitoringRole" } } ] } ] } -
The
DR Orchestrator FAILBACKstate machine reads the resource type asCreateAuroraSecondaryDBCluster, and it calls thedr-orchestrator-stepfunction-create-Aurora-Secondary-clusterstate machine.
-
The
dr-orchestrator-stepfunction-create-Aurora-Secondary-clusterstate machine deletes the existing cluster (dbcluster-01) from the former primary Region (us-east-1).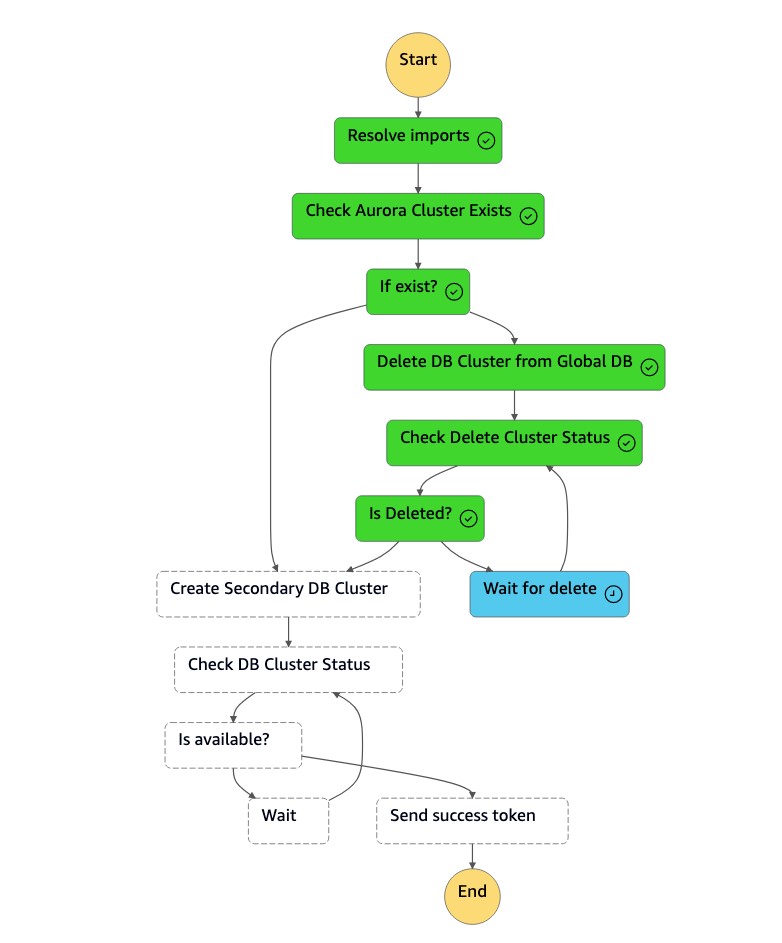
-
After the cluster (
dbcluster-01) is deleted, the state machine creates a new cluster (dbcluster-01) along with the DB instance, and it joins the Aurora global database as the secondary cluster to serve read-only workloads.
-
After the secondary cluster is available, the
dr-orchestrator-stepfunction-create-Aurora-Secondary-clusterstate machine is completed, and it sends a success token back to theDR Orchestrator Failbackstate machine.
-
The
dr-orchestrator-stepfunction-FAILBACKstate machine is completed.
-
You can verify the Aurora global database on the Amazon RDS console.
If you want to relocate the primary DB cluster to us-east-1 then you can follow the steps mentioned in the Switchover section.
