On-premises DR to AWS
Using AWS as an offsite disaster recovery (DR) environment for on-premises workloads
is a common hybrid scenario. Define your DR objectives, including the required recovery
time and recovery point objectives, before selecting technologies to use. To help with
this definition, you can use the DR plan checklist
There are a number of options available to help you quickly set up and provision a DR environment on AWS. Be sure that you account for all your workload dependencies, and test your DR plan and solution thoroughly and regularly to verify its integrity.
AWS provides AWS Elastic Disaster Recovery for creating a full replica of your on-premises servers, including the root volume and operating system, on AWS. Elastic Disaster Recovery continuously replicates your machines into a low-cost staging area in your target AWS account and preferred AWS Region. The block level replication is an exact replica of your servers’ storage including the operating system, system state configuration, databases, applications, and files. If there is a disaster, you can instruct Elastic Disaster Recovery to quickly launch thousands of your machines in their fully provisioned state within minutes.
Elastic Disaster Recovery uses an agent installed on each of your on-premises servers. The agents synchronize the state of your on-premises servers with lower-powered Amazon EC2 equivalents running on AWS. You can also automate your DR failover and failback process with Elastic Disaster Recovery. Automating your failover and failback process can help you achieve a lower and more consistent recovery time objective (RTO).
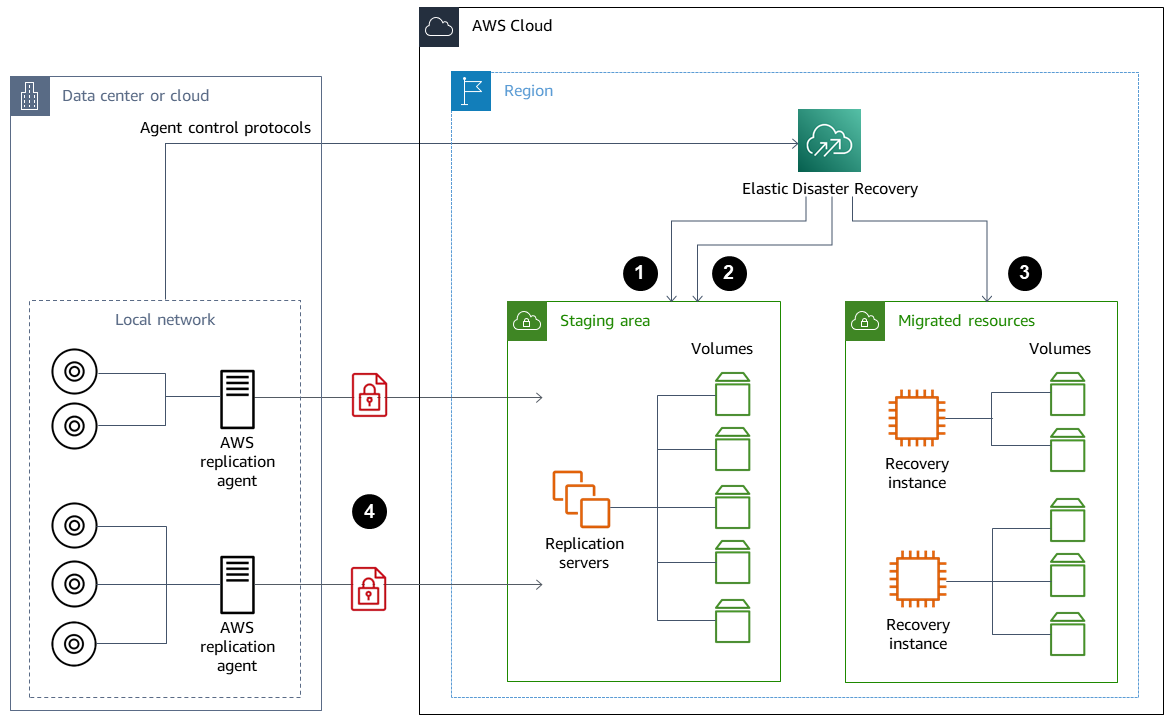
-
Replication server status reporting
-
Staging area resources automatically created and terminated
-
Recovery instances launched with RTO of minutes and RPO of seconds
-
Continuous block-level replication (compressed and encrypted)
It’s important to test the DR process and to verify that the live staging environment
doesn’t create conflicts with the on-premises environment. For example, confirm that the
appropriate licenses are available and functioning in your on-premises, staging, and
initiated DR environment. Also confirm that any worker type processes that might poll
and pull work from a central database are configured appropriately to avoid overlaps or
conflicts. In your DR process, include any necessary steps that must be performed before
your recovery server instances come online. Also include the steps to perform after the
recovery server instances are online and available. You can use solutions such as the
AWS Elastic Disaster Recovery Plan Automation solution
You can use a Storage Gateway volume gateway to provide your on-premises servers with cloud-based volumes. These volumes can also be quickly provisioned for use with Amazon EC2 using Amazon EBS snapshots. In particular, stored volume gateways provide your on-premises applications with low-latency access to their entire datasets. The volume gateways also provide durable snapshot-based backups that can be restored for on premises use or for use with Amazon EC2. You can schedule point-in-time snapshots based on the recovery point objective (RPO) for your workload.
Important
Volume gateway volumes are intended to be used as data volumes and not as boot volumes.
You can use an Amazon EC2 Amazon Machine Image (AMI) with a configuration that matches your on-premises servers and specifies your data volumes separately. After you configure and test the AMI, provision the EC2 instances from the AMI along with the data volumes based on the volume gateway snapshots. This approach requires you to test your environment thoroughly to verify that your EC2 instance is operating properly, especially for Windows workloads.
