Event sourcing pattern
Intent
In event-driven architectures, the event sourcing pattern stores the events that result in a state change in a data store. This helps to capture and maintain a complete history of state changes, and promotes auditability, traceability, and the ability to analyze past states.
Motivation
Multiple microservices can collaborate to handle requests, and they communicate through events. These events can result in a change in state (data). Storing event objects in the order in which they occur provides valuable information on the current state of the data entity and additional information about how it arrived at that state.
Applicability
Use the event sourcing pattern when:
-
An immutable history of the events that occur in an application is required for tracking.
-
Polyglot data projections are required from a single source of truth (SSOT).
-
Point-in time reconstruction of the application state is needed.
-
Long-term storage of application state isn't required, but you might want to reconstruct it as needed.
-
Workloads have different read and write volumes. For example, you have write-intensive workloads that don't require real-time processing.
-
Change data capture (CDC) is required to analyze the application performance and other metrics.
-
Audit data is required for all events that happen in a system for reporting and compliance purposes.
-
You want to derive what-if scenarios by changing (inserting, updating, or deleting) events during the replay process to determine the possible end state.
Issues and considerations
-
Optimistic concurrency control: This pattern stores every event that causes a state change in the system. Multiple users or services can try to update the same piece of data at the same time, causing event collisions. These collisions happen when conflicting events are created and applied at the same time, which results in a final data state that doesn't match reality. To solve this issue, you can implement strategies to detect and resolve event collisions. For example, you can implement an optimistic concurrency control scheme by including versioning or by adding timestamps to events to track the order of updates.
-
Complexity: Implementing event sourcing necessitates a shift in mindset from traditional CRUD operations to event-driven thinking. The replay process, which is used to restore the system to its original state, can be complex in order to ensure data idempotency. Event storage, backups, and snapshots can also add additional complexity.
-
Eventual consistency: Data projections derived from the events are eventually consistent because of the latency in updating data by using the command query responsibility segregation (CQRS) pattern or materialized views. When consumers process data from an event store and publishers send new data, the data projection or the application object might not represent the current state.
-
Querying: Retrieving current or aggregate data from event logs can be more intricate and slower compared to traditional databases, particularly for complex queries and reporting tasks. To mitigate this issue, event sourcing is often implemented with the CQRS pattern.
-
Size and cost of the event store: The event store can experience exponential growth in size as events are continuously persisted, especially in systems that have high event throughput or extended retention periods. Consequently, you must periodically archive event data to cost-effective storage to prevent the event store from becoming too large.
-
Scalability of the event store: The event store must efficiently handle high volumes of both write and read operations. Scaling an event store can be challenging, so it's important to have a data store that provides shards and partitions.
-
Efficiency and optimization: Choose or design an event store that handles both write and read operations efficiently. The event store should be optimized for the expected event volume and query patterns for the application. Implementing indexing and query mechanisms can speed up the retrieval of events when reconstructing the application state. You can also consider using specialized event store databases or libraries that offer query optimization features.
-
Snapshots: You must back up event logs at regular intervals with time-based activation. Replaying the events on the last known successful backup of the data should lead to point-in-time recovery of the application state. The recovery point objective (RPO) is the maximum acceptable amount of time since the last data recovery point. RPO determines what is considered an acceptable loss of data between the last recovery point and the interruption of service. The frequency of the daily snapshots of the data and event store should be based on the RPO for the application.
-
Time sensitivity: The events are stored in the order in which they occur. Therefore, network reliability is an important factor to consider when you implement this pattern. Latency issues can lead to an incorrect system state. Use first in, first out (FIFO) queues with at-most-once delivery to carry the events to the event store.
-
Event replay performance: Replaying a substantial number of events to reconstruct the current application state can be time-consuming. Optimization efforts are required to enhance performance, particularly when replaying events from archived data.
-
External system updates: Applications that use the event sourcing pattern might update data stores in external systems, and might capture these updates as event objects. During event replays, this might become an issue if the external system doesn't expect an update. In such cases, you can use feature flags to control external system updates.
-
External system queries: When external system calls are sensitive to the date and time of the call, the received data can be stored in internal data stores for use during replays.
-
Event versioning: As the application evolves, the structure of the events (schema) can change. Implementing a versioning strategy for events to ensure backward and forward compatibility is necessary. This can involve including a version field in the event payload and handling different event versions appropriately during replay.
Implementation
High-level architecture
Commands and events
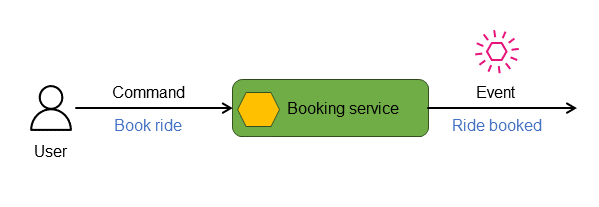
In distributed, event-driven microservices applications, commands represent the instructions or requests sent to a service, typically with the intent of initiating a change in its state. The service processes these commands and evaluates the command's validity and applicability to its current state. If the command runs successfully, the service responds by emitting an event that signifies the action taken and the relevant state information. For example, in the following diagram, the booking service responds to the Book ride command by emitting the Ride booked event.
Event stores
Events are logged into an immutable, append-only, chronologically ordered repository or data store known as the event store. Each state change is treated as an individual event object. An entity object or a data store with a known initial state, its current state, and any point-in-time view can be reconstructed by replaying the events in the order of their occurrence.
The event store acts as a historical record of all actions and state changes, and serves as a valuable single source of truth. You can use the event store to derive the final, up-to-date state of the system by passing the events through a replay processor, which applies these events to produce an accurate representation of the latest system state. You can also use the event store to generate the point-in-time perspective of the state by replaying the events through a replay processor. In the event sourcing pattern, the current state might not be entirely represented by the most recent event object. You can derive the current state in one of three ways:
-
By aggregating related events. The related event objects are combined to generate the current state for querying. This approach is often used in conjunction with the CQRS pattern, in that the events are combined and written into the read-only data store.
-
By using materialized views. You can employ event sourcing with the materialized view pattern to compute or summarize the event data and obtain the current state of related data.
-
By replaying events. Event objects can be replayed to carry out actions for generating the current state.
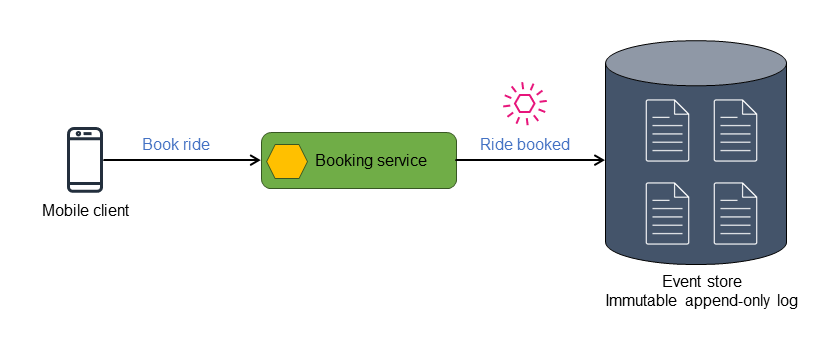
The following diagram shows the Ride booked event being stored in an event
store.
The event store publishes the events it stores, and the events can be filtered and routed to the appropriate processor for subsequent actions. For example, events can be routed to a view processor that summarizes the state and shows a materialized view. The events are transformed to the data format of the target data store. This architecture can be extended to derive different types of data stores, which leads to polyglot persistence of the data.
The following diagram describes the events in a ride booking application. All the events that occur within the application are stored in the event store. Stored events are then filtered and routed to different consumers.
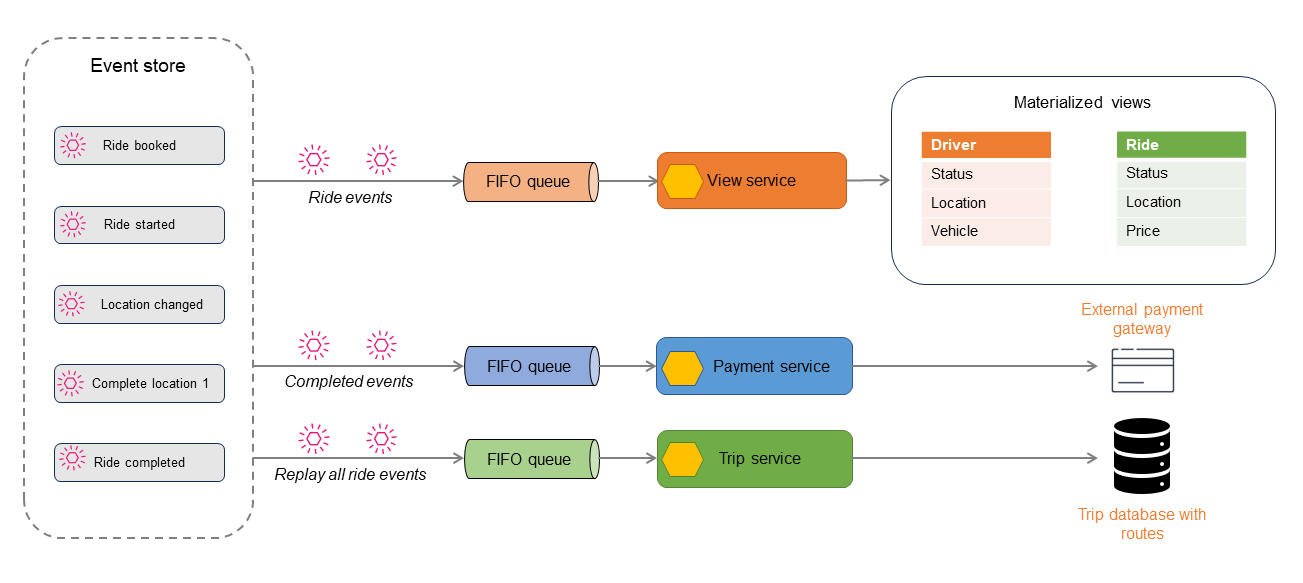
The ride events can be used to generate read-only data stores by using the CQRS or
materialized view pattern. You can obtain the current state of the ride, the driver, or the
booking by querying the read stores. Some events, such as Location changed or
Ride completed, are published to another consumer for payment processing. When the
ride is complete, all ride events are replayed to build a history of the ride for auditing or
reporting purposes.
The event sourcing pattern is frequently used in applications that require a point-in-time recovery, and also when the data has to be projected in different formats by using a single source of truth. Both of these operations require a replay process to run the events and derive the required end state. The replay processor might also require a known starting point—ideally not from application launch, because that would not be an efficient process. We recommend that you take regular snapshots of the system state and apply a smaller number of events to derive an up-to-date state.
Implementation using AWS services
In the following architecture, Amazon Kinesis Data Streams is used as the event store. This service captures and manages application changes as events, and offers a high-throughput and real-time data streaming solution. To implement the event sourcing pattern on AWS, you can also use services such as Amazon EventBridge and Amazon Managed Streaming for Apache Kafka (Amazon MSK) based on your application's needs.
To enhance durability and enable auditing, you can archive the events that are captured by Kinesis Data Streams in Amazon Simple Storage Service (Amazon S3). This dual-storage approach helps retain historical event data securely for future analysis and compliance purposes.
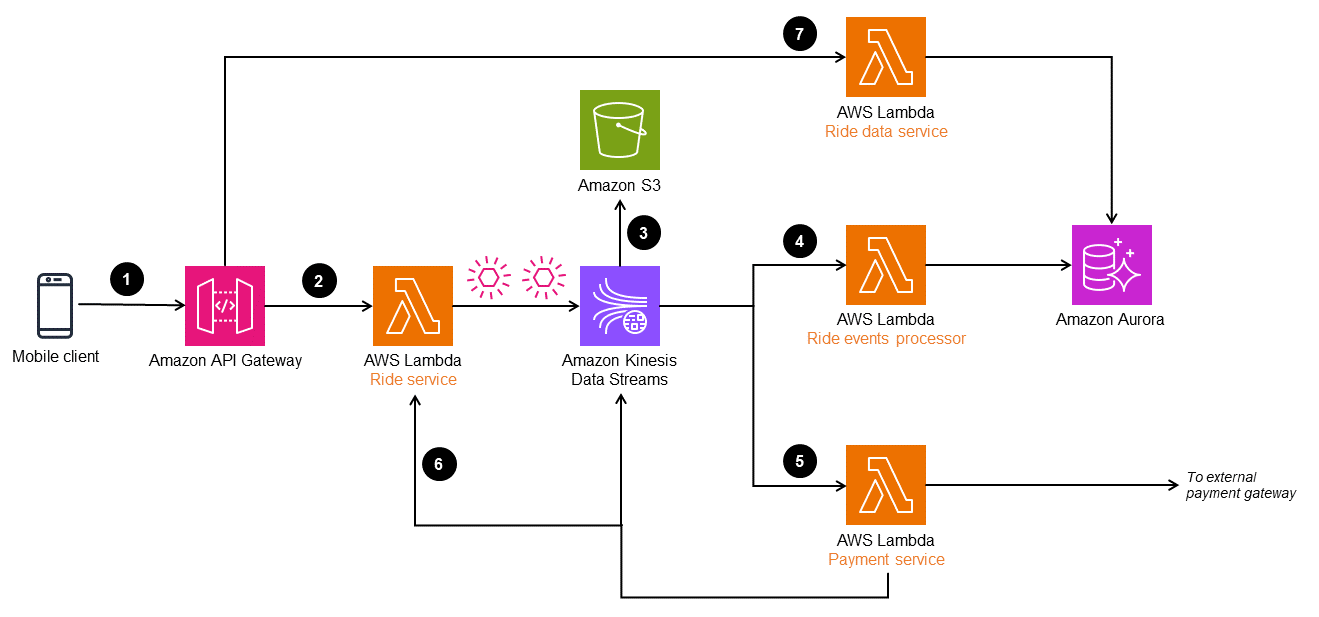
The workflow consists of the following steps:
-
A ride booking request is made through a mobile client to an Amazon API Gateway endpoint.
-
The ride microservice (
Ride serviceLambda function) receives the request, transforms the objects, and publishes to Kinesis Data Streams. -
The event data in Kinesis Data Streams is stored in Amazon S3 for compliance and audit history purposes.
-
The events are transformed and processed by the
Ride event processorLambda function and stored in an Amazon Aurora database to provide a materialized view for the ride data. -
The completed ride events are filtered and sent for payment processing to an external payment gateway. When payment is completed, another event is sent to Kinesis Data Streams to update the Ride database.
-
When the ride is complete, the ride events are replayed to the
Ride serviceLambda function to build routes and the history of the ride. -
Ride information can be read through the
Ride data service, which reads from the Aurora database.
API Gateway can also send the event object directly to Kinesis Data Streams without the
Ride service Lambda function. However, in a complex system such as a ride hailing
service, the event object might need to be processed and enriched before it gets ingested into
the data stream. For this reason, the architecture has a Ride service that processes
the event before sending it to Kinesis Data Streams.
Blog references
