Common scaling challenges
A data lake goes through several stages when its data grows after the initial deployment. If you didn't use scalable architecture to design your data lake, your organization might encounter challenges and can be disadvantaged by the data lake’s growth.
The following sections explain how a typical data lake’s growth can cause scaling challenges.
Initial data lake deployment
The following diagram shows a data lake's architecture after its initial deployment by Line of business A.
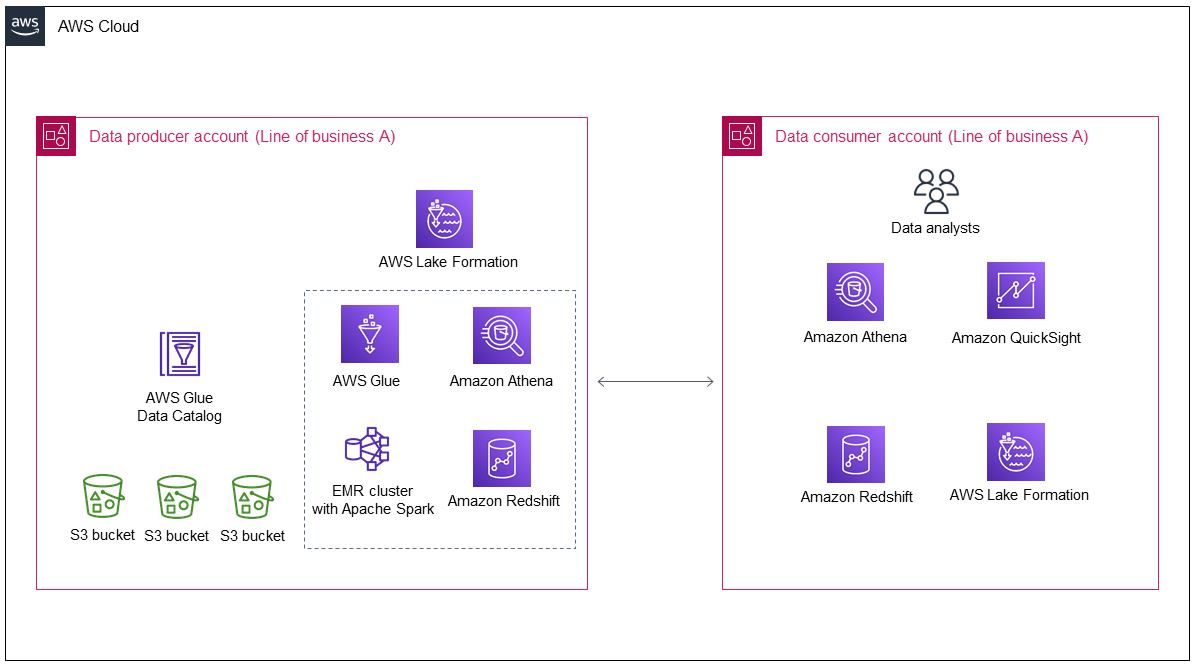
The diagram shows the following components:
-
The data producer account collects and processes data, stores the processed data, and prepares it for consumption.
-
Data in the data producer account is stored in Amazon Simple Storage Service (Amazon S3) buckets, which can have multiple data layers.
-
You can use AWS services for data processing (for example, AWS Glue and Amazon EMR).
-
The data producer not only produces and stores data in the data lake but then also needs to decide what data to share with a data consumer and how to share it. AWS Lake Formation manages the data lake in the data producer account, in addition to managing cross-account data sharing from the data producer to the data consumer.
-
The data consumer account consumes shared data from the data producer account for specific business use cases.
Data consumers increase
The following diagram shows that more data is brought into the data lake when Line of business A's data grows. The data lake then attracts more data consumers to leverage and gain value from the data.
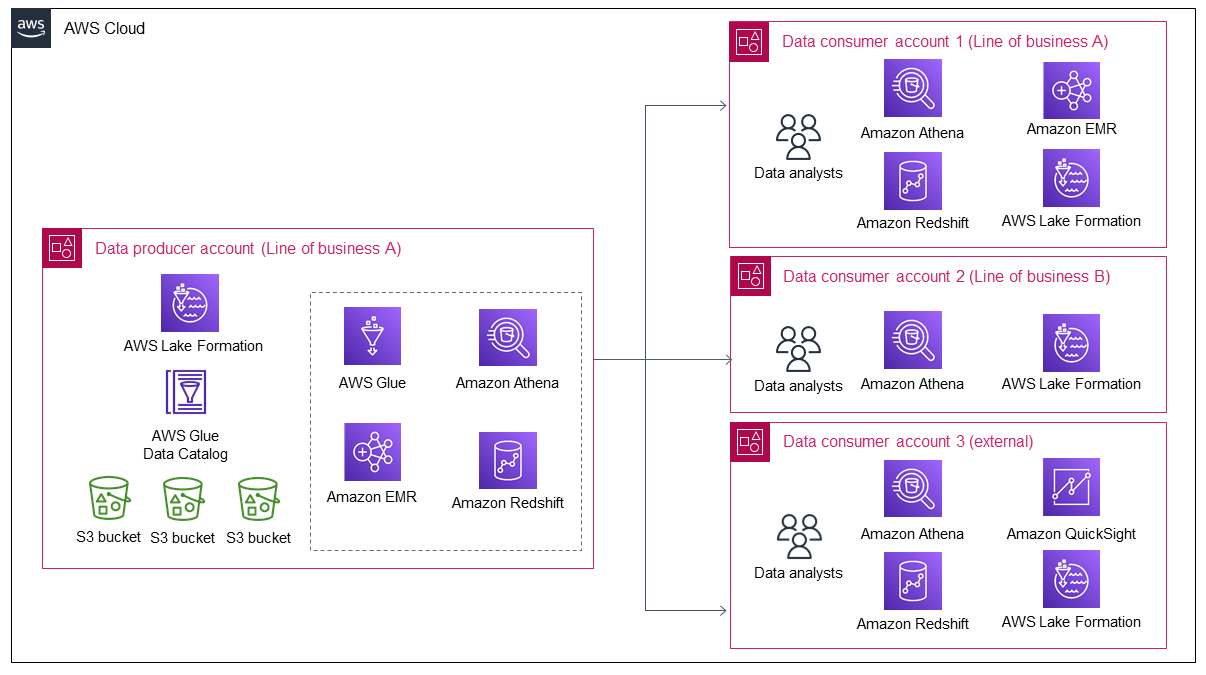
The diagram shows how an organization generates nearly continuous value from an existing data asset and that this attracts more data consumers. However, when data consumers increase, the data producer only has the following two options to accommodate this growth:
-
Manually manage data sharing and access by individual data consumers, which is not a scalable approach.
-
Develop an automated or semi-automated process for data sharing and managing data access. Although this could be a scalable option, it requires significant time and effort to design and build because internal and external data consumers have different security control requirements. In the future, additional time and effort would also be required for any solution improvements.
Data producers increase
The following diagram shows the data lake architecture when multiple lines of business join as data producers.
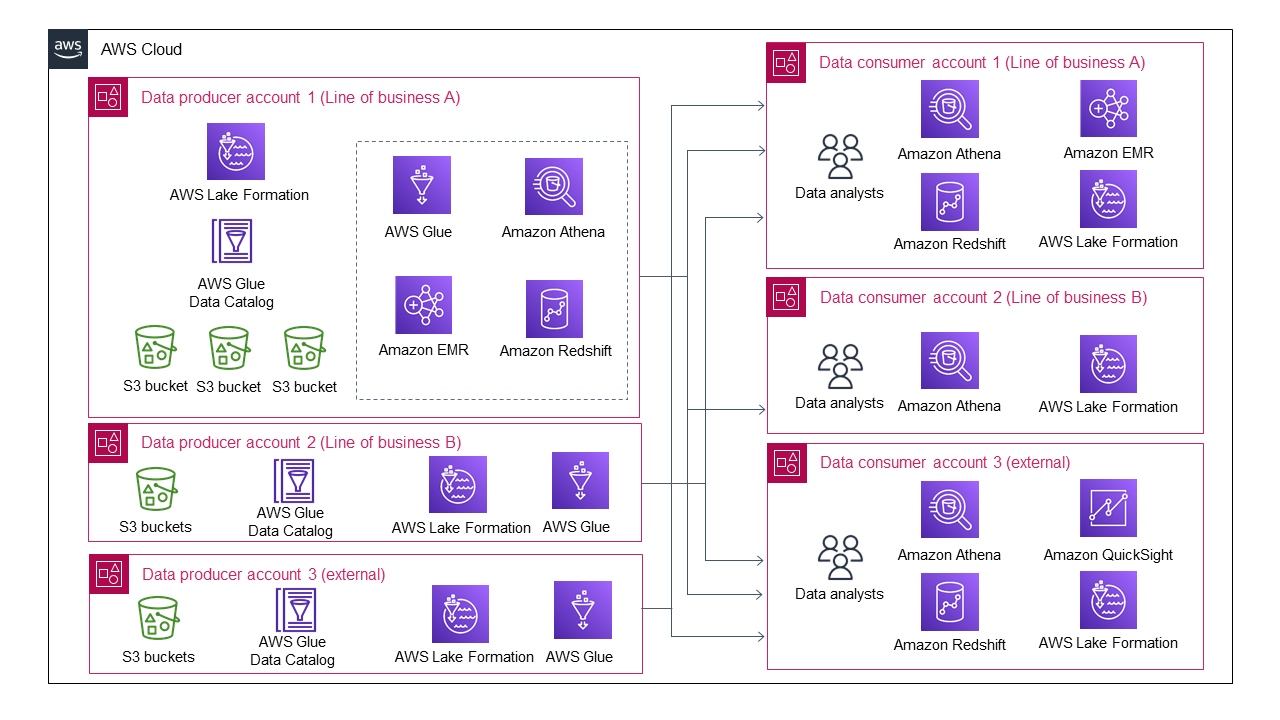
The data lake's architecture becomes increasingly complicated, even with only three data producers and three data consumers.
Each data producer needs to handle data sharing and data access management for multiple data consumers. It is unrealistic to expect all data producers to develop an automated or semi-automated process for data sharing and data access management. Some data producers might choose to not share their data and therefore avoid unaffordable management overhead. Similarly, each data consumer needs to interact with multiple data producers to understand their different data consumption processes. This means that individual data consumers face increasing management overhead for handling different data-sharing patterns.
In many organizations, this data lake causes bottlenecks and cannot grow or scale. This might mean that your organization must redesign and rebuild its data lake to remove the bottleneck, which can cost significant time, resources, and money.
