Machine learning models for forecasting freight demand
The following image shows an example of the training data. The target is what you want to predict, and related time series 1 and 2 are input features that are relevant to predict the target. Historical data is used for training and validation, and you withhold a period of the historical data for model validation.
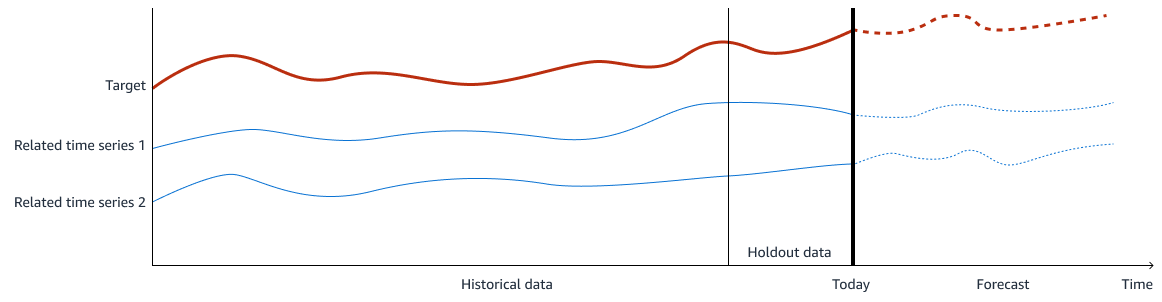
In demand forecasting, the output (or target) is the demand volume that you want to predict. The input features are time series data related to the output. To train an ML model to make an accurate forecast of demand volume, two machine learning models are needed in the solution. The first model makes a time series forecast for the input features, including both internal and external data. The second model makes the final demand forecast by using all features. By using these two models together, you can effectively capture both the time series trend and the relationship between the target and the inputs.
ML model for the input feature forecast
Input features include both internal and external historical time series data. To make
forecasts for each feature, you can use a one-dimensional (1D) time series model. There
are various algorithms available. For example, Prophet
ML model for the target variable forecast
The ML model for the output, or the demand volume, is built to capture the relationship between all of the features and the output. You can use various supervised regression models, such as lasso, ridge regression, random forest, and XGBoost. When building the model and finding the best parameters and hyperparameters, you can use holdout data. Holdout data is a portion of historical, labeled data that is withheld from the dataset that is used to train a machine learning model. You can use holdout data to evaluate the model performance by comparing the predictions against the holdout data.
