Application portfolio assessment guide for AWS Cloud migration
German Goncalves and Mark Berner, Amazon Web Services (AWS)
May 2024 (document history)
This Amazon Web Services (AWS) Prescriptive Guidance document dives deep into implementing the application portfolio assessment strategy. You can use this guide to help you initiate and progress through the assessment of your portfolio of applications and associated infrastructure. The assessment includes discovery, analysis, and planning. Infrastructure includes compute, storage, and networks.
Overview
Long-running cloud migration programs require the coordination of several workstreams such as program governance, landing zone (an operative target environment with security controls), migration, and application portfolio. The names of these workstreams might vary depending on how you choose to organize your migration program. As a workstream, application portfolio assessment represents a foundational activity across the entire lifecycle of these programs. The understanding of the portfolio that is gained through the assessment provides a key input to other workstreams that depend on the data and analysis resulting from the continuous application portfolio assessment.
The following diagram shows how the stages of portfolio assessment correspond to the AWS phases of migration and other workstreams. The portfolio discovery and initial planning stage begins in the assess phase, typically during the first five weeks. Prioritized applications assessment, in the sixth and seventh weeks, spans the assess and mobilize phases. The portfolio analysis and migration planning stage happens in weeks 8-14, in the mobilize phase. The continuous assessment and improvement stage happens in the migrate and modernize phase, from week 15 until the end of the migration program. This timeline is indicative. The actual duration of the stages will depend on the overall program organization. The portfolio assessment stages are also valid outside of this framework, and they can be incorporated into any migration program structure.

-
Discovery acceleration and initial planning focuses on the current understanding of the portfolio. It includes creating a directional business case, establishing base rationalization models for migration, and identifying initial migration candidates.
-
Prioritized applications assessment delivers faster time-to-value through a detailed assessment, initial design of the target state architecture, and identification of applications that can be moved in the short term. Moving applications quickly provides teams with migration experience and establishes cloud foundations, such as an initial landing zone and other infrastructure components.
-
Portfolio analysis and migration planning focuses on building a complete and up-to-date view of the application portfolio. The view is built by iteratively enriching the portfolio dataset, closing data gaps, evolving the business case, and creating high-confidence migration wave plans.
-
Continuous assessment and improvement supports migrations at scale by producing detailed application and technology assessments for each migration wave as a continuous activity. This stage includes iterating the migration wave plan and conducting further analysis of migrated workloads for optimization and modernization.
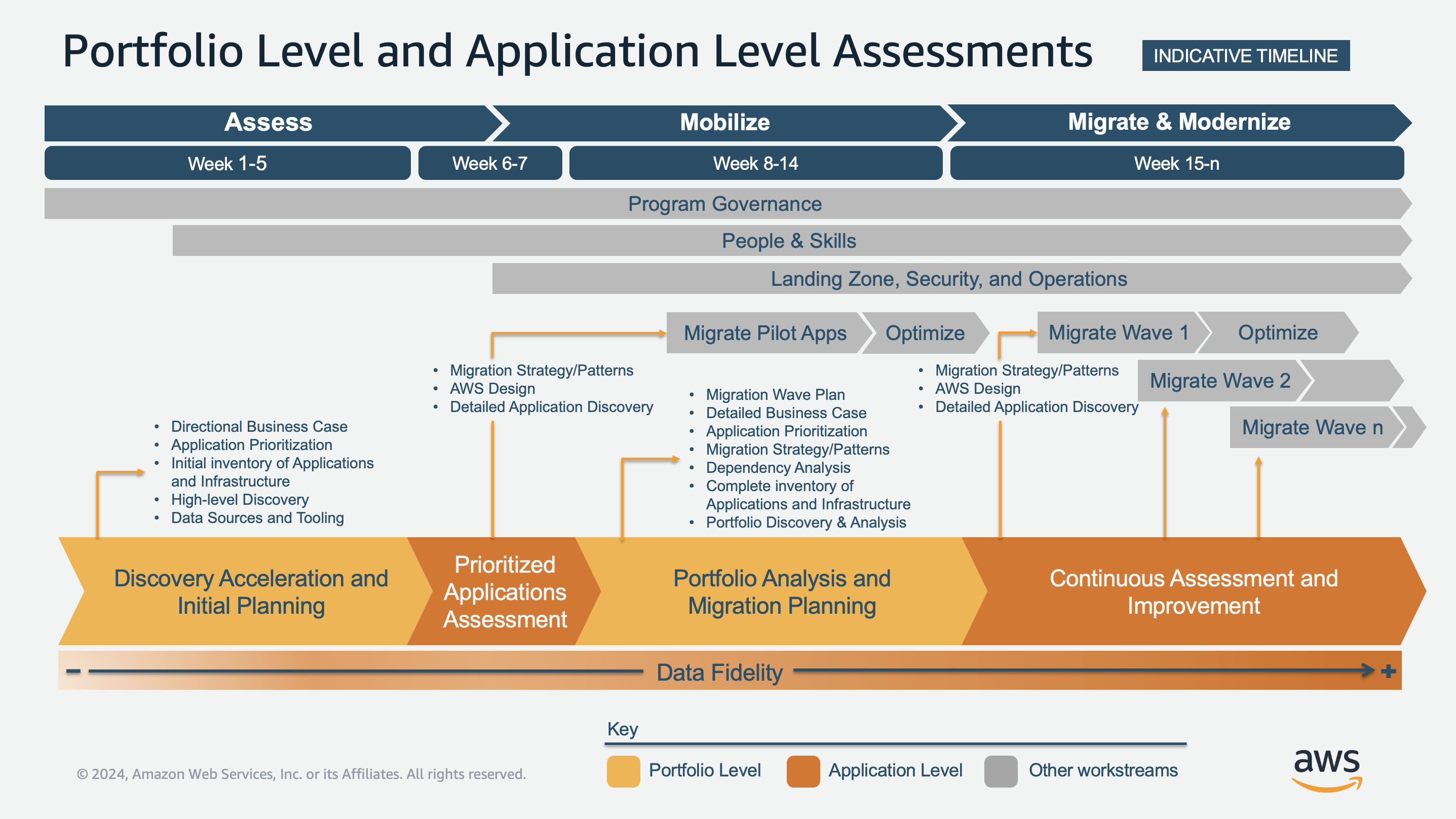
The following diagram shows the key activities for each stage of assessment and how they pivot between portfolio-level assessment and application-level assessment. Portfolio-level assessment focuses on high-level discovery and overall analysis of the portfolio. For example, sources of portfolio data, application and infrastructure inventory, prioritization, and directional business case. Application-level assessment focuses on the detailed discovery of one or more applications. For example, detailed application discovery, target AWS design, and migration strategy at the architecture and technology levels of the applications. Portfolio-level and application-level assessments represents the breadth and depth of information required.