Data preparation and cleaning
Data preparation and cleaning is one of the most important yet most time-consuming stages of the data lifecycle. The following diagram shows how the data preparation and cleaning stage fits into the data engineering automation and access control lifecycle.

Here are some examples of data preparation or cleaning:
-
Mapping text columns to codes
-
Ignoring empty columns
-
Filling empty data fields with
0,None, or'' -
Anonymizing or masking personally identifiable information (PII)
If you have a large workload that has a variety of data, then we recommend that you
use Amazon EMRDataFrame or
DynamicFrame to work with horizontal processing. Moreover, you can use
AWS Glue
DataBrew
For smaller workloads that don't require distributed processing and can be completed
in under 15 minutes, we recommend that you use AWS Lambda
It's essential to choose the right AWS service for data preparation and cleaning and to understand the tradeoffs involved with your choice. For example, consider a scenario where you're choosing from AWS Glue, DataBrew, and Amazon EMR. AWS Glue is ideal if the ETL job is infrequent. An infrequent job takes place once a day, once a week, or once a month. You can further assume that your data engineers are proficient in writing Spark code (for big data use cases) or scripting in general. If the job is more frequent, running AWS Glue constantly can get expensive. In this case, Amazon EMR provides distributed processing capabilities and offers both a serverless and server-based version. If your data engineers don't have the right skillset or if you must deliver results fast, then DataBrew is a good option. DataBrew can reduce the effort to develop code and speed up the data preparation and cleaning process.
After the processing is completed, the data from the ETL process is stored on AWS. The choice of storage depends on what type of data you're dealing with. For example, you could be working with non-relational data like graph data, key-value pair data, images, text files, or relational structured data.
As shown in the following diagram, you can use the following AWS services for data storage:
-
Amazon S3
stores unstructured data or semi-structured data (for example, Apache Parquet files, images, and videos). -
Amazon Neptune
stores graph datasets that you can query by using SPARQL or GREMLIN. -
Amazon Keyspaces (for Apache Cassandra)
stores datasets that are compatible with Apache Cassandra. -
Amazon Aurora
stores relational datasets. -
Amazon DynamoDB
stores key-value or document data in a NoSQL database. -
Amazon Redshift
stores workloads for structured data in a data warehouse.
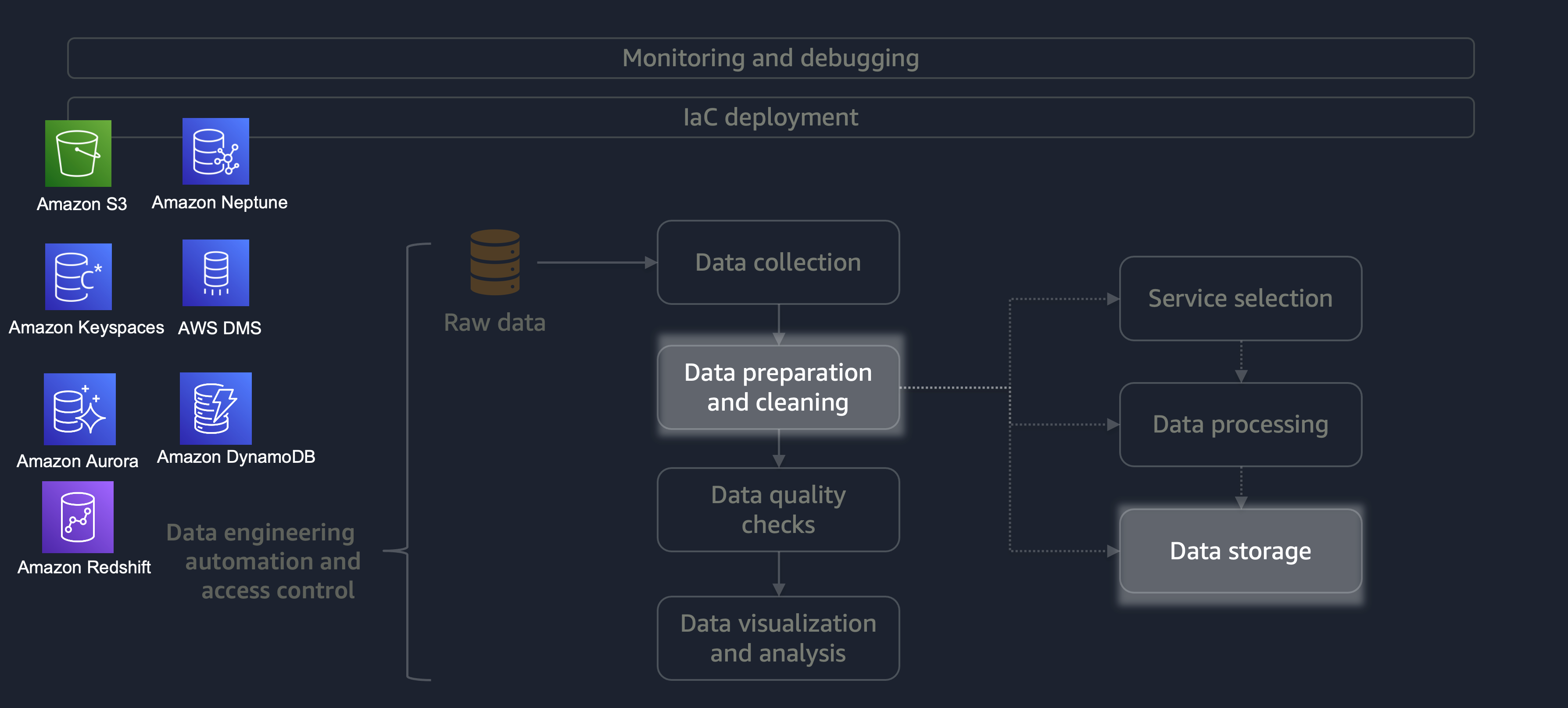
By using the right service with the correct configurations, you can store your data in the most efficient and effective way. This minimizes the effort involved in data retrieval.
