Stage 5 – Cutover
This stage discusses various approaches that you can employ to cut over from your current Elasticsearch or OpenSearch environment to the target Amazon OpenSearch Service domain. Cutover can be done in two steps:
-
Establish a data synchronization mechanism to keep the target environment synchronized with the source.
-
Perform the swap from the current environment to the target environment with or without downtime.
Data synchronization
For any system receiving continuous data, data migration might require that you stop receiving new data during the migration and run the migration in a maintenance window (with possible downtime). If you can't afford downtime, you can capture changes after you have initiated the migration. You replay the changes on the target to keep it updated and synchronized with the source until you perform the cutover. The following sections discuss various ways that you can keep the source and target synchronized.
Log analytics workloads
For log analytics workloads, you can perform an update sync in the following ways:
-
You can run two environments side by side until the retention period and run ingestion to both the current and target environments are complete. At some point in time, you decide to cut over and point your applications to the new environment. Sometimes, you can ingest new data from the log or document sources to both the existing cluster and the target OpenSearch Service environments. You can then backfill the older data in the target environment by copying it from the current environment. In all cases, you must make sure your data doesn't have any gaps that will impact your users.
-
Before the data migration, you can decide to pause your ingestion to the existing environment. However, this approach means your users might not be able to search the latest or changed data from your existing environment until your data migration is complete. After your data migration is complete, you can point your data ingestion to the target environment and switch your applications and clients over to the target environment. This means no new data will be available until migration is complete. However, the system will remain available for search. You should have the means to hold source logs and data in your source until the new environment is available.
-
You can continue to use the current log analytics engine until your first pass of data is migrated. Then you backfill the remaining data that has been produced since the first pass was initiated. Assuming that the remaining data is much smaller than the first pass, you can pause ingestion while your remaining data is synchronized, because the synchronization might take only a few minutes or a few hours. You can also perform a few passes using this approach until your synchronization window becomes small enough to pause ingestion from the source to the target environment and cut over to the target environment without impacting your users. The following diagram shows using incremental snapshot and restore to update or sync data.

Step 1
-
Data flows from the source through the data ingestion pipeline to the current Elasticsearch environment and the Amazon OpenSearch Service domain.
-
The first pass takes the longest time to move from Elasticsearch to the Amazon OpenSearch Service domain.
-
The first update or sync pass takes less time.
-
The second update or sync pass takes the least amount of time.
-
Data continues to flow from Elasticsearch to the applications.
Step 2
-
Data flows from the source through the data ingestion pipeline to the OpenSearch Service domain.
-
Ingestion to the current Elasticsearch environment is stopped.
-
The final update or sync pass takes the least amount of time.
-
Data flows from OpenSearch Service to the applications.
-
Search workloads
In the three approaches previously discussed, you must ensure that all data on your target is up to date before you perform the cutover. For search workloads, you can consider the following suggestions for updating or syncing:
-
For search workloads, typically you pause the ingestion from the source to the current environment. You copy all your data from the current environment to the target environment, and you put in place a change data capture (CDC) mechanism that can determine what data has changed since the start of the migration. You then copy the changed data to the Amazon OpenSearch environment. In most cases, the search application's data ingestion pipelines already have a CDC mechanism built in, and it usually is a matter of pointing your pipeline to the new environment after the data is migrated from the current environment. The following diagram shows building an index entirely from the source for search use cases.
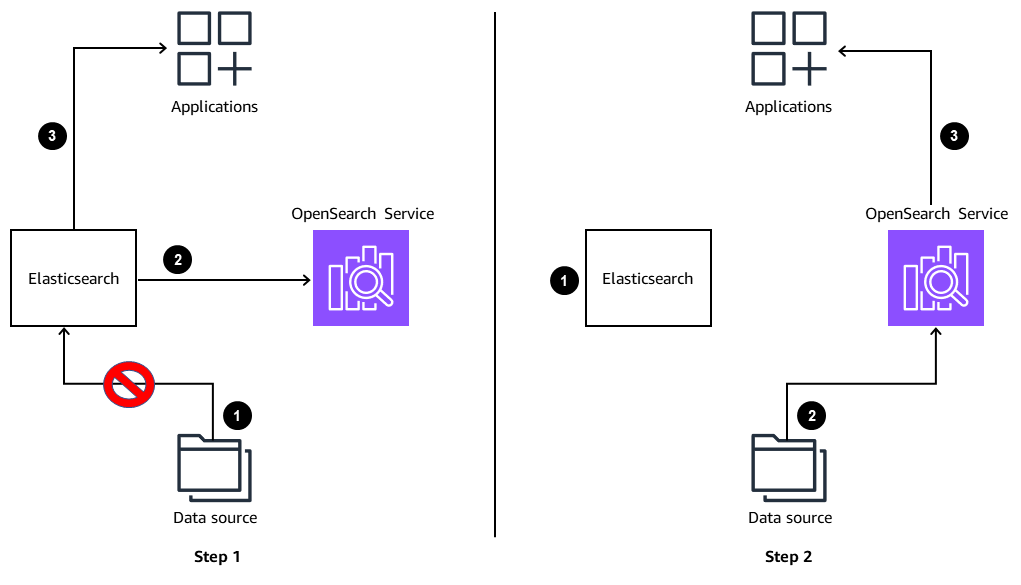
Step 1
-
Ingestion to the current Elasticsearch environment is paused.
-
Data is copied from ElasticSearch to the OpenSearch Service domain.
-
Data continues to flow from ElasticSearch to the applications.
Step 2
-
The Elasticsearch environment is no longer connected to the data source or the applications.
-
Change data capture (CDC) data is ingested in the pipeline and flows to the OpenSearch Service domain.
-
Data flows from the OpenSearch Service domain to the applications.
-
-
Some search workloads require loading only full data from the source database or data source to the new OpenSearch Service environment. After the load is complete, the client applications can cut over to the new environment. This is the simplest way to achieve migration for search workloads.
Swap or cut over
The final step in the migration journey is swapping, or cutting over, to the new environment. It is one of the critical phases. At this point, you are ready to go live. You have the data synchronized and up to date, you have monitoring and alerts configured, your runbooks are up to date, and you are ready to cut over to the new environment. You must make sure that your ingestion is flowing normally and that the metrics from your new environment are healthy. During this stage, you plan and perform the cutting over of the client connections from your existing Elasticsearch or OpenSearch cluster to the new Amazon OpenSearch Service domain. Be mindful of any client library changes that might be required. At this point, you should have tested all your client functionality with Amazon OpenSearch Service in your lower environments to verify compatibility and performance.
If you have a client application that needs to point to the new environment, update the DNS entry from the old environment to the new environment. Then closely monitor the application behavior to ensure that your users are getting the right experience.
Generally, if you have followed the guidelines in this document, you will have a safe switchover. However, we recommend that you keep your source environment up to date so that it can act as a fallback in case you encounter any problems with the new environment. Some AWS customers continue to operate both environments for a few weeks after the swap before decommissioning the older environment. We recommend that you choose a strategy that aligns with your business continuity requirements.
