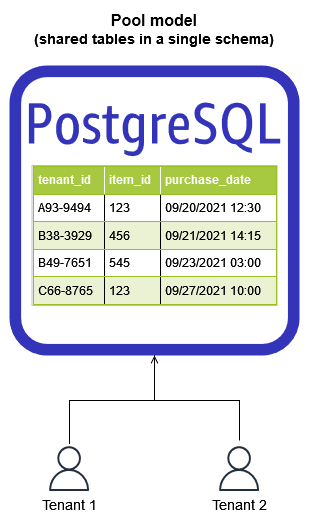
PostgreSQL pool model
The pool model is implemented by provisioning a single PostgreSQL instance (Amazon RDS or
Aurora) and using row-level
security (RLS)SELECT queries or which rows are affected by
INSERT, UPDATE, and DELETE commands. The pool model
centralizes all tenant data in a single PostgreSQL schema, so it is significantly more
cost-effective and requires less operational overhead to maintain. Monitoring this solution is
also significantly simpler due to its centralization. However, monitoring tenant-specific
impacts in the pool model usually requires some additional instrumentation in the application.
This is because PostgreSQL by default isn’t aware of which tenant is consuming resources.
Tenant onboarding is simplified because no new infrastructure is required. This agility makes
it easier to accomplish rapid and automated tenant onboarding workflows.
Although the pool model is generally more cost-effective and simpler to administer, it does have some disadvantages. The noisy neighbor phenomenon cannot be completely eliminated in a pool model. However, it can be mitigated by ensuring that appropriate resources are available on the PostgreSQL instance and by using strategies to reduce the load in PostgreSQL, such as offloading queries to read replicas or to Amazon ElastiCache. Effective monitoring also plays a role in responding to tenant performance isolation concerns, because application instrumentation can log and monitor tenant-specific activity. Lastly, some SaaS customers might not find the logical separation provided by RLS to be sufficient and might ask for additional isolation measures.
