PostgreSQL silo model
The silo model is implemented by provisioning a PostgreSQL instance for each tenant in an application. The silo model excels at tenant performance and security isolation, and completely eliminates the noisy neighbor phenomenon. The noisy neighbor phenomenon occurs when one tenant’s usage of a system affects the performance of another tenant. The silo model lets you tailor performance specifically to each tenant and potentially limit outages to a specific tenant’s silo. However, what generally drives adoption of a silo model is strict security and regulatory constraints. These constraints can be motivated by SaaS customers. For example, SaaS customers might demand that their data be isolated due to internal constraints, and SaaS providers might offer such a service for an additional fee.
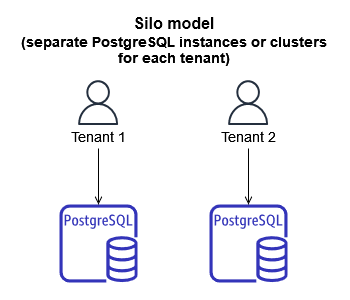
Although the silo model might be necessary in certain cases, it has many drawbacks. It is often difficult to use the silo model in a cost-effective manner, because managing resource consumption across multiple PostgreSQL instances can be complicated. Furthermore, the distributed nature of database workloads in this model makes it more difficult to maintain a centralized view of tenant activity. Managing so many independently operated workloads increases operational and administrative overhead. The silo model also makes tenant onboarding more complicated and time-consuming, because you have to provision tenant-specific resources. Furthermore, the entire SaaS system can be harder to scale, because the ever-increasing number of tenant-specific PostgreSQL instances will demand more operational time to administer. One last consideration is that an application or a data access layer will have to maintain a mapping of tenants to their associated PostgreSQL instances, which adds to the complexity of implementing this model.
