Downtime costs and the emergence of chaos engineering
The Information Technology Intelligence Consulting (ITIC)
While downtime is commonly associated with revenue-generating online systems, the negative impact extends far beyond that. All large businesses and organizations, regardless of their primary revenue model, rely critically on the availability of their internal systems, such as HR and payroll.
Downtime affecting these core internal services can inhibit a company's ability to function, leading to substantial operational disruptions and financial repercussions. The resulting problems can include the following:
-
Delays in paying employees and vendors
-
Inability to process customer orders or transactions
-
Breaches of sensitive data allowed by compromised security systems
-
Loss of productivity and revenue opportunities
-
Regulatory penalties for noncompliance
-
Damage to brand reputation
Chaos engineering intentionally introduces controlled disruptions. Using chaos engineering to understand or verify the system's response to impairments has become a critical practice for improving system resilience. Chaos engineering enables your organization to proactively uncover issues, validate resilience mechanisms, and ultimately reduce the risk of unplanned downtime and its associated costs. The benefits of chaos engineering include the following:
-
Exposing technical debt
-
Exercising operational muscles
-
Building confidence in systems
-
Identifying failure points
-
Improving monitoring and observability
-
Supporting experiment-based learning
-
Delivering improved resilience to reduce downtime
As systems become more complex and customer expectations increase, chaos engineering is
rising in importance. Gartner recommends chaos engineering
The adoption challenges of chaos engineering
Although chaos engineering is an increasingly important practice for improving system resilience, its adoption can face the following obstacles:
-
Misperceptions about risk ‒ A common misperception is that chaos engineering is conducted only in production environments, which leads to concerns about excessive risk. This perception stems from a lack of understanding about the systematic and controlled nature of chaos engineering practices. As noted in the AWS Well-Architected Framework, conduct fault simulation first in a non-production environment.
-
Longer term to business value ‒ Chaos engineering's benefits accrue gradually, making it difficult to quantify the business value and justify the initial investment. The slower ROI makes it hard for organizations to prioritize and stick with chaos engineering.
-
Skill and expertise gaps ‒ Chaos engineering requires a unique set of skills and expertise that might not be readily available within your organization. Building or acquiring this expertise can be a significant barrier, especially for organizations that are new to the practice and those with limited resources.
The rest of this strategy document will focus mostly on the second challenge, which is to demonstrate the business value of chaos engineering.
The accumulating effects of chaos engineering
Unlike traditional technology projects with well-defined start and end dates, chaos engineering is an ongoing practice of continuous learning and continuous improvements to system resilience. The benefits of chaos engineering compound over time.
As systems evolve and grow more complex, new failure modes emerge. More chaos experiments are needed to identify potential issues. Fixing an issue can take months, especially in large enterprises with intricate systems and processes, or when faults are owned by external service providers.
The cultural shift toward embracing failure as an opportunity for learning and improvement grows over years and becomes ingrained in the organization. Investments in automating chaos engineering experiments and developing supporting tooling continue to streamline and enhance the chaos engineering practice. Building this institutional knowledge and understanding of system resilience is a gradual process that accumulates over time. The knowledge, processes, and tools developed through chaos engineering increase in value as the practice matures alongside the continuously evolving systems.
The following diagram shows how value increases over time as chaos adoption progresses through the following stages:
-
Initial adoption
-
Learning
-
Failure-mode analysis
-
One-time experiments
-
Periodic GameDays
-
Continuous experimentation
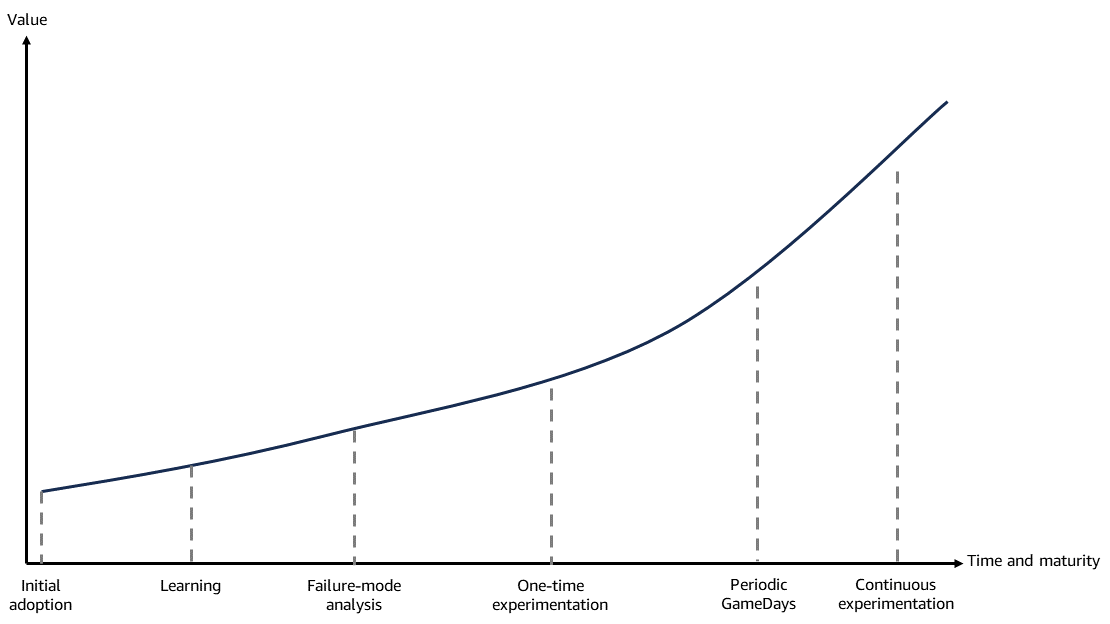
As shown in the diagram, the benefits of chaos engineering often start before any fault is injected into the system. The process of planning and designing chaos experiments itself provides immediate value. Identifying potential failure scenarios, single points of failure, and areas of uncertainty in the system leads to improvements.
For example, writing down failure scenarios and discussing the potential cascading effects, a process called failure mode and effects analysis (FMEA), helps uncover obvious weaknesses or gaps that might have been overlooked. Your organization can proactively address those issues, even before subjecting the system to any intentional disruptions. For more information, see the Resilience analysis framework.
Additionally, the increased focus on system observability and monitoring that often accompanies chaos engineering initiatives starts to deliver benefits right away. Improving the visibility into system behavior and failure modes helps the team better understand the system's normal operating conditions. Greater visibility also helps the team understand how operating conditions degrade, adapt, and fail when pushed to their limits.
Both the one-time experiment and periodic GameDay modes are more manual approaches compared to the continuous experimentation mode. They require a more hands-on and exploratory process, where engineers actively shape and refine hypotheses through their observations and experiments.
The continuous experimentation mode is, on the other hand, more automated in nature.
This mode focuses on running approved and validated hypotheses in a controlled and
iterative manner. It uses automation and integration in the development process through a
dedicated chaos pipeline
