Example implementation of a modern health-data strategy
AWS provides reference architectures that healthcare organizations can use to
understand and build data platforms that support an agile approach to data. The
following reference architecture illustrates a data mesh architecture
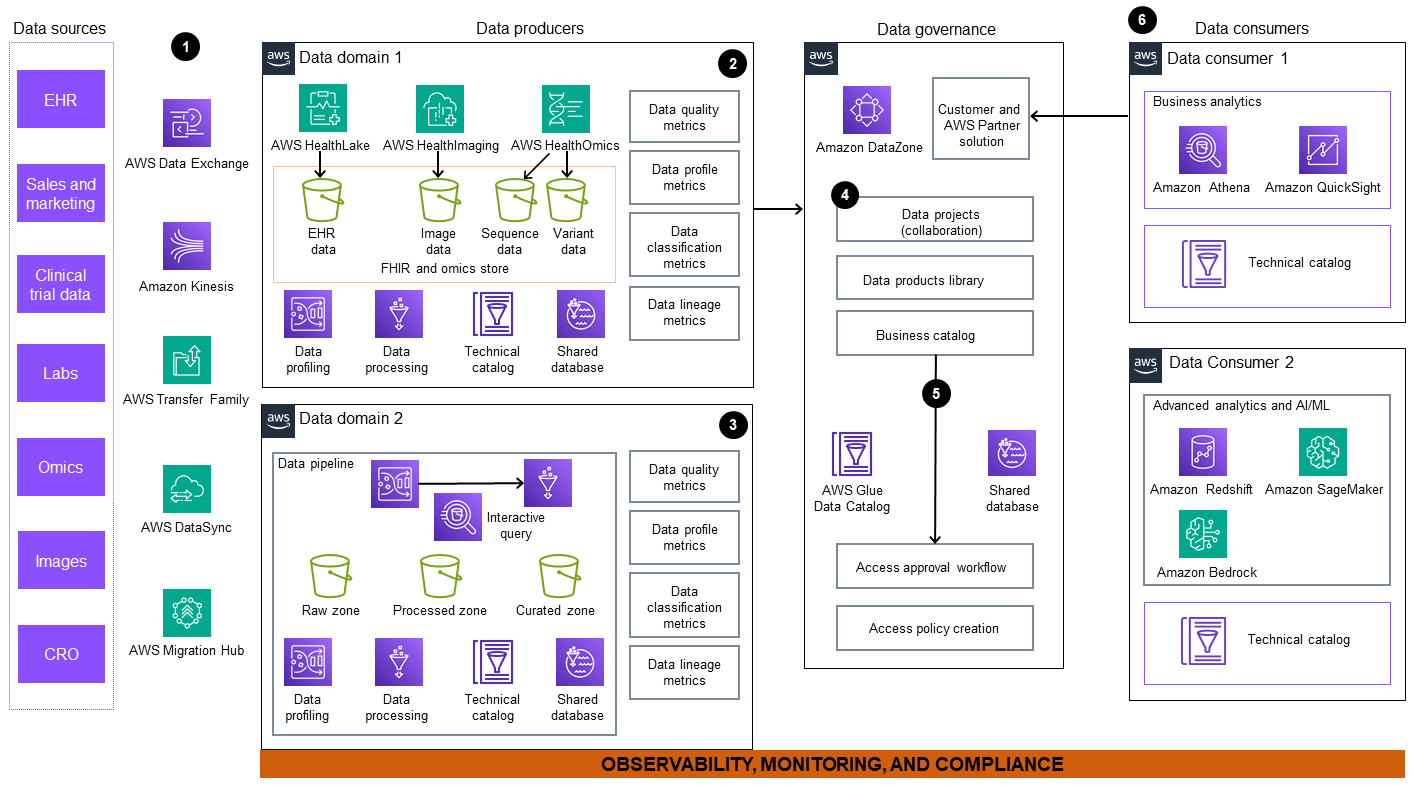
The architecture diagram includes the following components:
-
Data is ingested from external and internal data sources. These sources include, but are not limited to, Electronic Health Record (EHR) systems, labs, sequencing facilities, and imaging centers. AWS offers a suite of services such as AWS Data Exchange
, Amazon Kinesis , AWS Transfer Family , AWS DataSync , AWS Migration Hub , AWS HealthLake , and AWS Glue (ETL). You can use these services to help migrate your internal dataset and to subscribe to both internal and external datasets. -
Data domain 1 comprises a comprehensive workflow for processing multimodal patient-oriented data, including clinical, omics, and imaging data. EHR clinical data is ingested and stored in a HealthLake data store, a purpose-built managed service for clinical data. AWS HealthOmics
, a purpose-built service for omics data, handles sequence and variant store and workflow. Imaging data is ingested and stored in AWS HealthImaging . This data is then transformed into consumption-ready products and published in an enterprise data marketplace for broad accessibility and use. -
In data domain 2, Amazon Kinesis, AWS Glue, and AWS Data Exchange ingest raw data into a data pipeline. Sources for the data can include public registries, remote patient monitoring, and Enterprise Resource Planning (ERP) programs. The pipeline loads the raw data into Amazon Simple Storage Service (Amazon S3)
buckets. This data is cleaned, curated, transformed, and stored for publishing as a data product. Amazon Athena offers an interactive query engine that data producers can use to transform data using SQL. AWS Glue DataBrew provides visual data transformation, normalization, and profiling capabilities. -
Amazon DataZone
handles the publishing of metadata, collaborative data projects, and the data products library to the central business catalog. -
A unified data analytics portal enables collaboration around data by providing a view of data products through federated governance. Amazon DataZone enables a self-serve workflow with AWS Glue Data Catalog backed by AWS Lake Formation, so that users can share, search, discover data, and request permission for consumption.
-
Data consumers can access data, create downstream views, and use purpose-built tools such as Amazon Athena, Amazon QuickSight
, Amazon Redshift , Amazon SageMaker AI , and Amazon Bedrock to do the following: -
Operational analytics
-
Clinical informatics
-
Research
-
Patient and clinical engagement
Data consumers can also develop innovative applications by using generative AI, and they can publish data products to the business catalog.
-
For more information about the data mesh architecture, see What is a Data Mesh?
Generative AI
Healthcare organizations are using generative AI for a range of applications, from automating medical image interpretation to generating diagnostic recommendations and treatment plans based on both image and textual data. The adoption of generative AI is accelerating innovation and enhancing efficiencies throughout the care continuum. The new focus on generative AI has forced healthcare to expand its data focus to include more forms of unstructured data, expanding the number and variety of use cases amenable to AI. In general, there are four patterns that organizations can choose from, depending on their use case, to implement generative AI solutions:
-
Prompt engineering – In prompt engineering, users supply relevant data as context, guiding the generative AI model to create content that they want. Organizations with a modern health-data strategy can ensure that the relevant data is easily discoverable, shareable, and consumable.
-
Retrieval Augmented Generation (RAG) – The RAG pattern builds on prompt engineering. Instead of a user providing relevant data, a program intercepts the user's question or input. The program searches across a data repository to retrieve content relevant to the question or input. The program feeds the data that it finds to the generative AI model to generate content. A modern healthcare-data strategy enables the curation and indexing of enterprise data. The data can then be searched and used as context for prompts or questions, assisting a large language model (LLM) in generating responses.
Your organization can use the following two patterns to focus generative AI model outputs on generating content appropriate to the context of their data.
-
Fine-tuning – Using this pattern, your organization can go a step further by customizing generative AI models. This involves fine-tuning the models on a small sample of data specific to the organization. Because the sample size is small, this pattern provides a balance of cost and customization. To avoid biases in model outputs, use a small sample dataset that is as diverse and representative of your organization's data patterns as possible. A modern health-data strategy supports efficient access to a wide variety of data to prepare the sample datasets.
-
Build your own model – If your organization needs to generate content across highly specialized, large volumes of data, and the previous three patterns aren't adequate, you can build your own models.
A modern data strategy plays a critical role in generative AI solutions by helping to ensure that the data has the following characteristics:
-
High-quality data to support accuracy
-
Real-time or near real-time data to help ensure that the model outputs are relevant
-
Multiple data modalities across a variety of data sources to provide the model with access to enriched datasets for generating content
The following diagram shows an implementation of a modern health-data strategy that uses a data mesh architecture to support generative AI solutions.

-
Data is ingested from diverse data sources in the Clinical Informatics, Clinical Research, and Revenue Management domains, and the data is made available to the healthcare organization.
-
Federated data governance helps ensure strict access control for data sharing and unified access.
-
Data consumers include the following:
-
Generative AI applications, particularly those using data to train and fine-tune LLMs. These applications use enterprise data for Q&A chatbots to enhance operational efficiency and patient and provider experiences.
-
Clinical applications equipped with tools such as EHR-integrated chatbots, productivity dashboards, and documentation aids.
-
Patient-centric applications for improving patient experiences. These applications feature chatbot interactions, clinical reports, and efficient referral and scheduling processes.
-
Clinical research, with a research project repository and applications designed for cohort analysis and regulatory reporting.
-
With this architecture, stakeholders in your organization can focus on curating
and managing the data they gather from other sources while making their own data
accessible to the rest of the organization. They can use tools that are available in
the federated data governance layer to define metadata, manage access approval
workflows, and define and enforce policies. In addition, the federated data
governance layer provides centralized access control. This creates an environment
for curating a variety of data sources and for refreshing high-quality data assets
at a specified frequency to maintain relevancy. AWS offers a comprehensive set of
capabilities to address your generative AI needs. Amazon Bedrock
