Exemplo: usar o Application Signals para resolver um problema de integridade operacional
O cenário a seguir fornece um exemplo de como o Application Signals pode ser usado para monitorar serviços e identificar problemas de qualidade de serviços. Faça uma pesquisa profunda para identificar as possíveis causas raiz e tomar medidas para resolver o problema. Este exemplo se concentra em uma aplicação de uma clínica para animais de estimação, composta de vários microsserviços que chamam Serviços da AWS como o DynamoDB.
Jane faz parte de uma equipe de DevOps que supervisiona a integridade operacional de uma aplicação de uma clínica para animais de estimação. A equipe de Jane está comprometida em garantir que a aplicação seja altamente disponível e responsiva. Os membros da equipe usam objetivos de nível de serviço (SLOs) para medir a performance da aplicação em relação a esses compromissos e negócios. Ela recebe um alerta sobre vários indicadores de nível de serviço (SLIs) não íntegros. Ela abre o console do CloudWatch e navega até a página Serviços e observa vários serviços em um estado não íntegro.
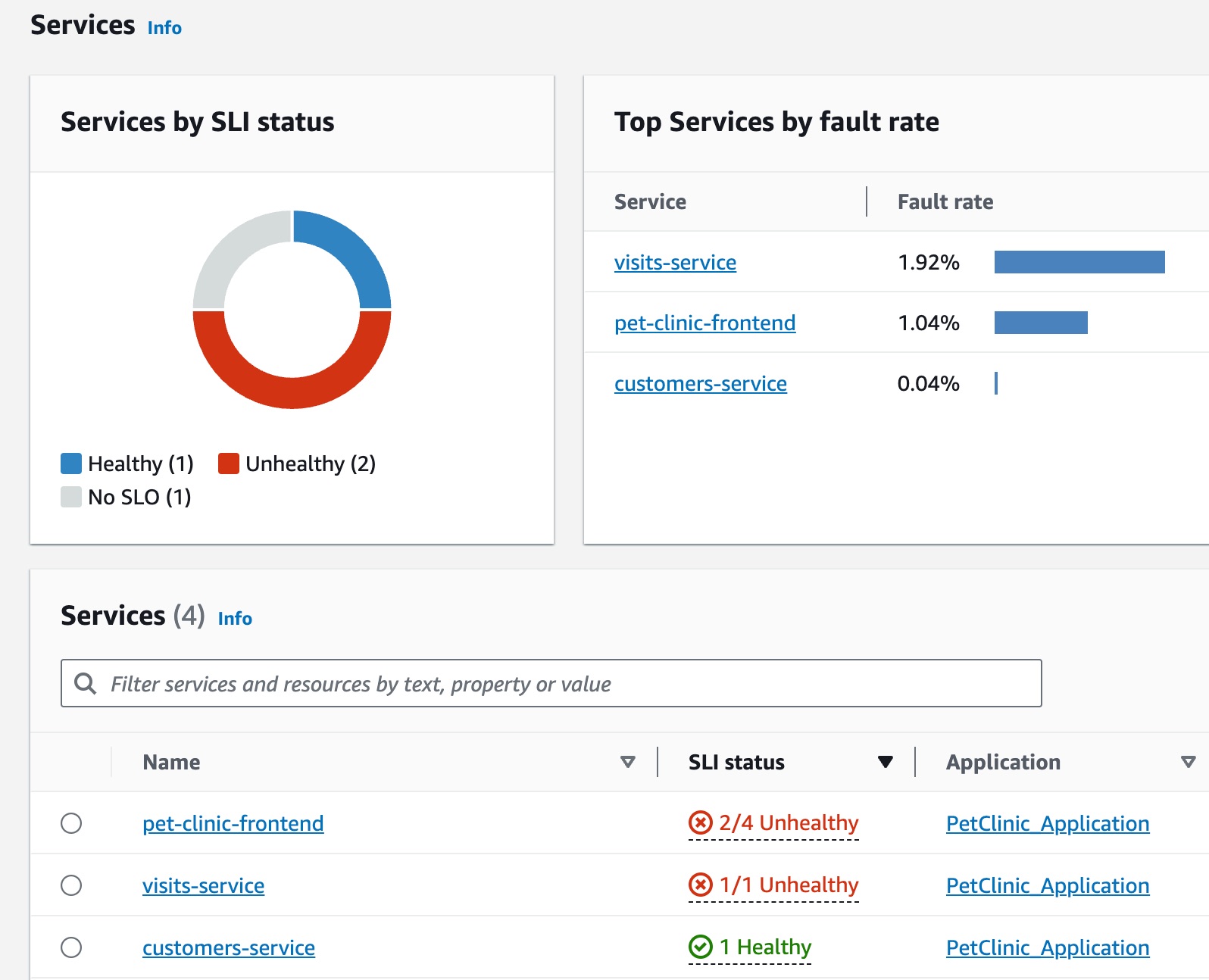
Na parte superior da página, Jane vê que visits-service é o melhor serviço por taxa de falhas. Ela seleciona o link no gráfico, que abre a página Detalhes do serviço para o serviço. Ela vê que há uma operação não íntegra na tabela Operações de serviço. Ela seleciona essa operação e vê no gráfico Volume e Disponibilidade que há picos periódicos no volume de chamadas que parecem estar correlacionados a quedas na disponibilidade.
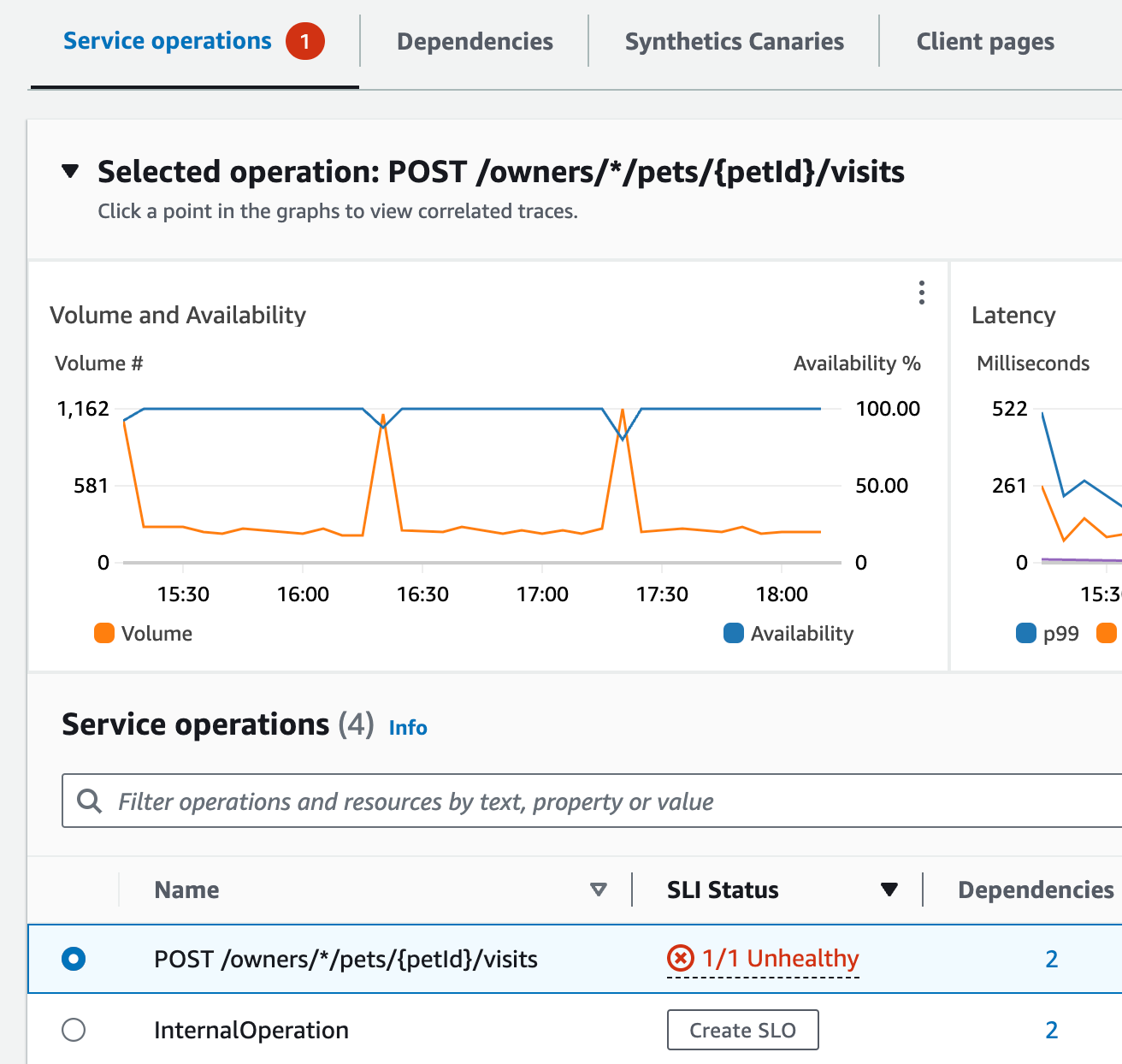
Para observar mais de perto as quedas na disponibilidade do serviço, Jane seleciona um dos pontos de dados de disponibilidade no gráfico. Uma gaveta é aberta mostrando rastreamentos do X-Ray que estão correlacionados ao ponto de dados selecionado. Ela vê que há vários rastreamentos com falhas.
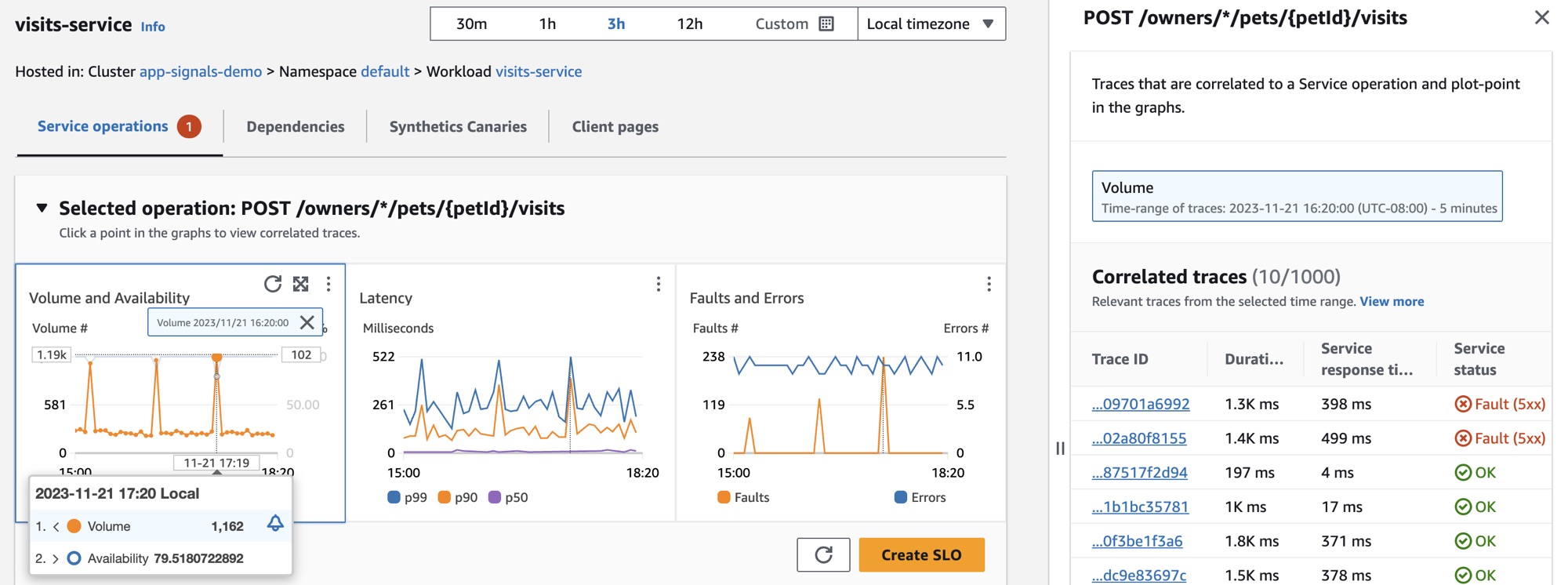
Jane seleciona um dos rastreamentos correlacionados com um status de falha, o que abre a página de detalhes de rastreamentos do X-Ray para o rastreamento selecionado. Jane desce até a seção Linha do tempo dos segmentos e segue o caminho de chamadas até ver que as chamadas para uma tabela do DynamoDB estão retornando erros. Ela seleciona o segmento do DynamoDB e navega até a guia Exceções na gaveta do lado direito.
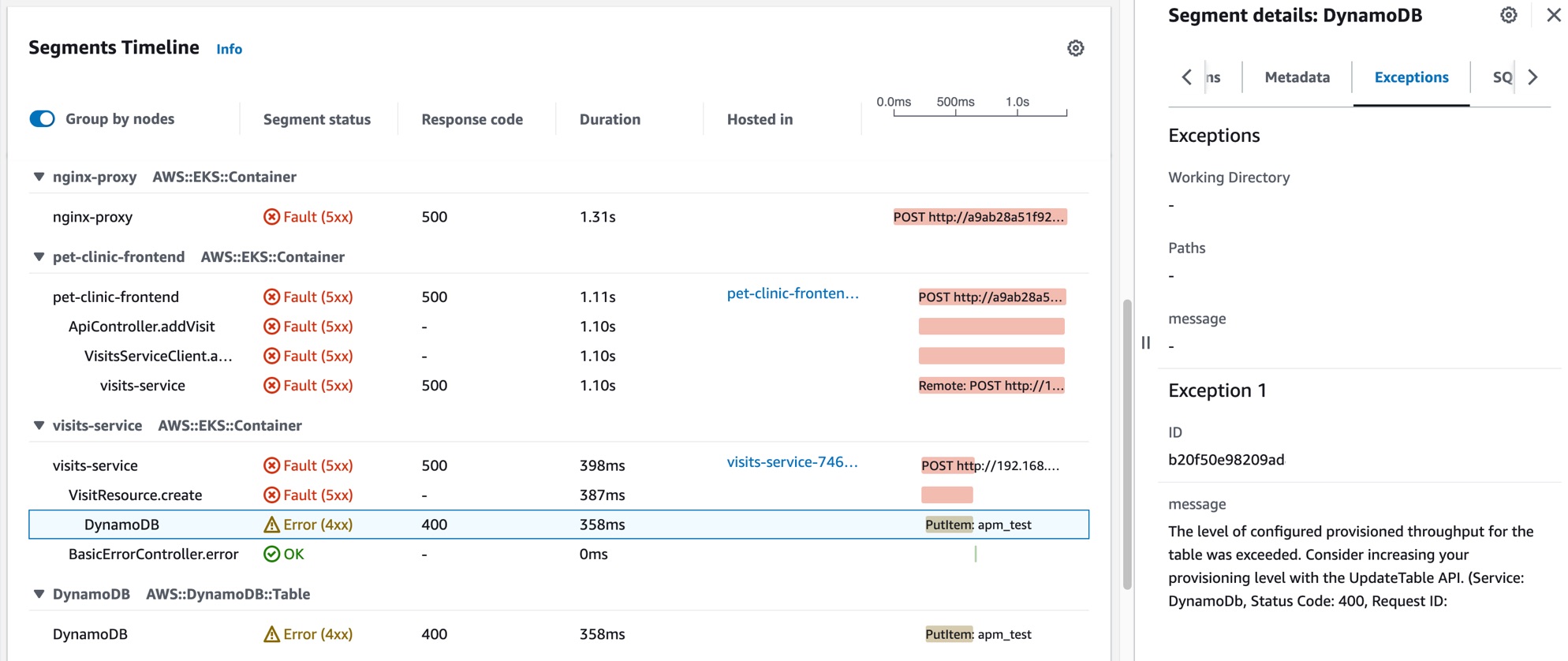
Jane percebe que um recurso do DynamoDB está configurado incorretamente, resultando em erros durante picos nas solicitações dos clientes. O nível de throughput provisionado da tabela do DynamoDB é excedido periodicamente, resultando em problemas de disponibilidade do serviço e SLIs não íntegros. Com base nessas informações, a equipe consegue configurar um nível mais alto de throughput provisionado e garantir a alta disponibilidade da aplicação.
