As traduções são geradas por tradução automática. Em caso de conflito entre o conteúdo da tradução e da versão original em inglês, a versão em inglês prevalecerá.
Auto Scaling de clusters Valkey e Redis OSS
Pré-requisitos
ElastiCache O Auto Scaling está limitado ao seguinte:
-
Clusters Valkey ou Redis OSS (modo de cluster ativado) executando Valkey 7.2 em diante ou executando Redis OSS 6.0 em diante
-
Clusters de armazenamento de dados em camadas (modo de cluster ativado) executando Valkey 7.2 em diante ou executando Redis OSS 7.0.7 em diante
-
Tamanhos de instância - Grande XLarge, 2 XLarge
-
Famílias de tipo de instância: R7g, R6g, R6gd, R5, M7g, M6g, M5, C7gn
-
O Auto Scaling in não ElastiCache é compatível com clusters executados em datastores globais, Outposts ou Locais Zones.
Gerenciando a capacidade automaticamente com o ElastiCache Auto Scaling com Valkey ou Redis OSS
ElastiCache o escalonamento automático com Valkey ou Redis OSS é a capacidade de aumentar ou diminuir automaticamente os fragmentos ou réplicas desejados em seu serviço. ElastiCache ElastiCache aproveita o serviço Application Auto Scaling para fornecer essa funcionalidade. Para obter mais informações, consulte Application Auto Scaling. Para usar o escalonamento automático, você define e aplica uma política de escalabilidade que usa CloudWatch métricas e valores-alvo que você atribui. ElastiCache o auto scaling usa a política para aumentar ou diminuir o número de instâncias em resposta às cargas de trabalho reais.
Você pode usar o AWS Management Console para aplicar uma política de escalabilidade com base em uma métrica predefinida. Uma predefined metric é definida em uma enumeração, para que você possa especificá-la por nome no código ou usá-la no AWS Management Console. As métricas personalizadas não estão disponíveis para seleção ao usar o AWS Management Console. Como alternativa, você pode usar a API Application Auto Scaling AWS CLI ou a Application Auto Scaling para aplicar uma política de escalabilidade com base em uma métrica predefinida ou personalizada.
ElastiCache para Valkey e Redis, o OSS suporta escalabilidade para as seguintes dimensões:
-
Fragmentos: adicionar/remover fragmentos automaticamente no cluster semelhantes à refragmentação manual online. Nesse caso, o escalonamento ElastiCache automático aciona o escalonamento em seu nome.
-
Réplicas — add/remove replicas in the cluster similar to manual Increase/Decrease replica operations. ElastiCache auto scaling for Valkey and Redis OSS adds/removes replica automaticamente de maneira uniforme em todos os fragmentos do cluster.
ElastiCache para Valkey e Redis, o OSS oferece suporte aos seguintes tipos de políticas de escalabilidade automática:
-
Políticas de escalabilidade de rastreamento de destino— Aumente ou diminua o número de shards/replicas execuções do seu serviço com base em um valor alvo para uma métrica específica. Isso é semelhante à forma como o termostato mantém a temperatura da casa. Você seleciona a temperatura, e o termostato faz o resto.
-
Escalabilidade programada para seu aplicativo. — ElastiCache para Valkey e Redis, o escalonamento automático do OSS pode aumentar ou diminuir o número shards/replicas de execuções do seu serviço com base na data e hora.
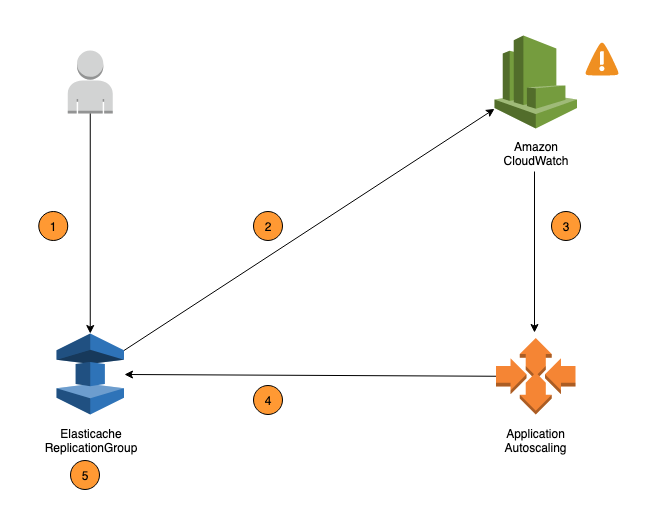
As etapas a seguir resumem o ElastiCache processo de escalonamento automático do Valkey e do Redis OSS, conforme mostrado no diagrama anterior:
-
Você cria uma política de escalabilidade ElastiCache automática para seu grupo de replicação.
-
ElastiCache o auto scaling cria um par de CloudWatch alarmes em seu nome. Cada par representa seus limites superiores e inferiores para métricas. Esses CloudWatch alarmes são acionados quando a utilização real do cluster se desvia da utilização desejada por um longo período de tempo. Agora, é possível visualizar os alarmes no console.
-
Se o valor da métrica configurada exceder sua meta de utilização (ou ficar abaixo da meta) por um período de tempo específico, CloudWatch acionará um alarme que invoca o escalonamento automático para avaliar sua política de escalabilidade.
-
ElastiCache o auto scaling emite uma solicitação de modificação para ajustar a capacidade do cluster.
-
ElastiCache processa a solicitação de modificação, aumentando (ou diminuindo) dinamicamente a Shards/Replicas capacidade do cluster para que ela se aproxime da utilização desejada.
Para entender como o ElastiCache Auto Scaling funciona, suponha que você tenha um cluster chamado. UsersCluster Ao monitorar as CloudWatch métricasUsersCluster, você determina o máximo de fragmentos que o cluster exige quando o tráfego está no pico e o mínimo de fragmentos quando o tráfego está no ponto mais baixo. Você também decide um valor-alvo para a utilização da CPU no UsersCluster cluster. ElastiCache o auto scaling usa seu algoritmo de rastreamento de metas para garantir que os fragmentos provisionados de UsersCluster sejam ajustados conforme necessário para que a utilização permaneça no valor alvo ou próximo dele.
nota
O escalonamento pode levar um tempo perceptível e exigirá recursos extras do cluster para que os fragmentos se rebalanceiem. ElastiCache O Auto Scaling modifica as configurações de recursos somente quando a carga de trabalho real permanece elevada (ou deprimida) por um período sustentado de vários minutos. O algoritmo de monitoramento do objetivo do ajuste de escala automático procura manter a utilização pretendida no valor escolhido ou próximo a ele em longo prazo.
Permissões do IAM necessárias para o Auto Scaling
ElastiCache para Valkey e Redis, o OSS Auto Scaling é possível graças a uma combinação do ElastiCache,, e do Application CloudWatch Auto Scaling. APIs Os clusters são criados e atualizados com ElastiCache, os alarmes são criados com CloudWatch e as políticas de escalabilidade são criadas com o Application Auto Scaling. Além das permissões padrão do IAM para criar e atualizar clusters, o usuário do IAM que acessa as configurações do ElastiCache Auto Scaling deve ter as permissões apropriadas para os serviços que oferecem suporte ao escalonamento dinâmico. Nessa política mais recente, adicionamos suporte ao dimensionamento vertical do Memcached, com a ação. elasticache:ModifyCacheCluster Os usuários do IAM precisam ter as permissões para usar as ações exibidas na política de exemplo a seguir:
Perfil vinculado a serviço
O serviço de escalonamento automático OSS ElastiCache para Valkey e Redis também precisa de permissão para descrever seus clusters CloudWatch e alarmes, além de permissões para modificar ElastiCache sua capacidade alvo em seu nome. Se você ativar o Auto Scaling em seu cluster, ele criará uma função vinculada ao serviço chamada AWSServiceRoleForApplicationAutoScaling_ElastiCacheRG. Essa função vinculada ao serviço concede permissão de escalonamento ElastiCache automático para descrever os alarmes de suas políticas, monitorar a capacidade atual da frota e modificar a capacidade da frota. A função vinculada ao serviço é a função padrão para o escalonamento ElastiCache automático. Para obter mais informações, consulte Funções vinculadas a serviços ElastiCache para o escalonamento automático do Redis OSS no Guia do usuário do Application Auto Scaling.
Práticas recomendadas de escalabilidade automática
Antes de se registrar no Auto Scaling, recomendamos o seguinte:
-
Use apenas uma métrica de monitoramento: identifique se o cluster tem workloads com uso intenso da CPU ou de dados e use uma métrica predefinida correspondente para definir a política de ajuste de escala.
-
CPU do mecanismo:
ElastiCachePrimaryEngineCPUUtilization(dimensão fragmentada) ouElastiCacheReplicaEngineCPUUtilization(dimensão da réplica) -
Uso do banco de dados:
ElastiCacheDatabaseCapacityUsageCountedForEvictPercentageessa política de ajuste de escala funciona melhor com maxmemory-policy definido como noeviction no cluster.
Recomendamos que você evite várias políticas por dimensão no cluster. ElastiCache para Valkey e Redis OSS, o Auto Scaling expandirá a meta escalável se alguma política de rastreamento de alvos estiver pronta para ser expandida, mas será ampliada somente se todas as políticas de rastreamento de alvos (com a parte de expansão ativada) estiverem prontas para serem ampliadas. Se várias políticas instruírem o destino escalável a aumentar ou reduzir a escala na horizontal ao mesmo tempo, ele escalará com base na política que forneça a maior capacidade tanto para reduzir quanto para aumentar a escala na horizontal.
-
-
Métricas personalizadas para monitoramento do objetivo: seja cauteloso ao usar métricas personalizadas para o monitoramento do objetivo, pois o ajuste de escala automático é mais adequado para aumentar/reduzir a escala horizontalmente de modo proporcional às alterações nas métricas escolhidas para a política. Se essas métricas não forem alteradas proporcionalmente às ações de ajuste de escala usadas para a criação de políticas, elas poderão aumentar ou reduzir a escala horizontalmente das ações de forma contínua, o que pode afetar a disponibilidade ou o custo.
Para clusters de armazenamento de dados em camadas (tipos de instância da família r6gd), evite usar métricas baseadas em memória para ajuste de escala.
-
Escalabilidade programada — Se você identificar que sua carga de trabalho é determinística (atinge high/low em um horário específico), recomendamos usar a escalabilidade programada e configurar sua capacidade alvo de acordo com a necessidade. O monitoramento do objetivo é mais adequado para workloads não determinísticas e para o cluster operar na métrica de destino necessária, aumentando a escala horizontalmente quando você precisar de mais recursos e reduzindo a escala horizontalmente quando precisar de menos recursos.
-
Desative o escalonamento — O escalonamento automático no Target Tracking é mais adequado para clusters com cargas increase/decrease de trabalho graduais, pois as métricas podem acionar oscilações consecutivas de spikes/dip escala/aumento. Para evitar tais oscilações, é possível começar com a opção de reduzir a escala horizontalmente desabilitada e, mais tarde, você pode reduzir a escala horizontalmente manualmente de acordo com sua necessidade.
-
Teste seu aplicativo — Recomendamos que você teste seu aplicativo com suas Min/Max cargas de trabalho estimadas para determinar o mínimo e o máximo absolutos shards/replicas necessários para o cluster enquanto cria políticas de escalabilidade para evitar problemas de disponibilidade. A autoescalabilidade pode aumentar a escala horizontalmente até o máximo e reduzir a escala horizontalmente até o mínimo limite configurado para o destino.
-
Definindo o valor-alvo — Você pode analisar CloudWatch as métricas correspondentes para a utilização do cluster em um período de quatro semanas para determinar o limite do valor-alvo. Se você ainda não tem certeza de qual valor escolher, recomendamos começar com o valor mínimo de métrica predefinida compatível.
-
AutoScaling on Target Tracking é mais adequado para clusters com distribuição uniforme de cargas de trabalho em todas as shards/replicas dimensões. Ter distribuição não uniforme pode levar a:
-
Dimensionamento quando não é necessário devido à carga de trabalho spike/dip em alguns fragmentos/réplicas quentes.
-
Não escalar quando necessário devido à média geral perto do destino, mesmo tendo fragmentos/réplicas quentes.
-
nota
Ao escalar seu cluster, ElastiCache replicará automaticamente as funções carregadas em um dos nós existentes (selecionados aleatoriamente) para o (s) novo (s) nó (s). Se seu cluster tiver o Valkey ou Redis OSS 7.0 ou posterior e sua aplicação usar Funções
Depois de se registrar AutoScaling, observe o seguinte:
-
Há limitações nas configurações compatíveis com a autoescalabilidade. Portanto, recomendamos que não altere a configuração de um grupo de replicação registrado para escalabilidade automática. Veja os exemplos a seguir:
-
Modificação manual do tipo de instância para tipos sem suporte.
-
Associação do grupo de replicação a um datastore global.
-
Alteração do parâmetro
ReservedMemoryPercent. -
increasing/decreasing shards/replicas beyond the Min/MaxCapacidade configurada manualmente durante a criação da política.
-
