Clonar um volume para um cluster de banco de dados do Amazon Aurora
Com a clonagem do Aurora, você pode criar um cluster que, inicialmente, compartilhe as mesmas páginas de dados do original mas seja um volume separado e independente. O processo foi projetado para ser rápido e econômico. O novo cluster e seu volume de dados associado é chamado de clone.. Criar um clone é mais rápido e eficiente em termos de espaço do que copiar fisicamente os dados usando outras técnicas, como restauração ou captura de tela.
Tópicos
Visão geral da clonagem do Aurora
O Aurora usa um protocolo copy-on-write para criar um clone. Esse mecanismo usa um espaço adicional mínimo para criar um clone inicial. Quando o clone é criado pela primeira vez, o Aurora mantém uma única cópia dos dados usados pelo cluster de banco de dados do Aurora de origem e pelo novo cluster de banco de dados do Aurora (clonado). O armazenamento adicional é alocado somente quando as alterações são feitas nos dados (no volume de armazenamento do Aurora) pelo cluster de banco de dados do Aurora original ou pelo clone do cluster de banco de dados do Aurora. Para saber mais sobre o protocolo copy-on-write, consulte Como a clonagem do Aurora funciona.
A clonagem do Aurora serve principalmente para configurar rapidamente ambientes de teste usando seus dados de produção, sem arriscar corromper dados. É possível utilizar clones para vários tipos de aplicações, como:
-
Experimente possíveis alterações (de esquema e de grupos de parâmetros, por exemplo) para avaliar todos os impactos.
-
Execute operações com workloads intensivas, como exportar dados ou executar consultas analíticas no clone.
-
Crie uma cópia do cluster de banco de dados de produção para desenvolvimento, teste ou outras finalidades.
É possível criar mais de um clone do mesmo cluster de banco de dados do Aurora. Também é possível criar vários clones a partir de outro clone.
Após criar um clone do Aurora, você pode configurar as instâncias de banco de dados do Aurora de forma diferente do cluster de banco de dados do Aurora de origem. Por exemplo, talvez você não precise de um clone para fins de desenvolvimento para atender aos mesmos requisitos de alta disponibilidade que o cluster de banco de dados de produção do Aurora de origem. Nesse caso, é possível configurar o clone com uma única instância de banco de dados Aurora em vez das várias instâncias de banco de dados usadas pelo cluster de banco de dados do Aurora.
Quando você cria um clone usando uma configuração de implantação diferente da origem, o clone é criado com a versão secundária mais recente do mecanismo de banco de dados do Aurora da origem.
Quando você cria clones a partir de seus clusters de banco de dados do Aurora, os clones são criados em sua conta da AWS, a mesma conta que contém o cluster do banco de dados do Aurora de origem. No entanto, também é possível compartilhar clusters e clones de banco de dados do Aurora Serverless v2 e provisionados do Aurora com outras contas da AWS. Para ter mais informações, consulte Clonar entre contas com o AWS RAM e Amazon Aurora.
Ao concluir o uso do clone para testes, desenvolvimento ou outras finalidades, você poderá excluí-lo.
Limitações da clonagem do Aurora
Atualmente, a clonagem do Aurora tem as seguintes limitações:
-
Você pode criar quantos clones quiser, até o número máximo de clusters de banco de dados permitido na Região da AWS.
Você pode criar os clones usando o protocolo copy-on-write ou o protocolo full-copy. O protocolo full-copy funciona como uma recuperação para um ponto no tempo.
-
Não é possível criar um clone em uma região da AWS diferente da região de origem do cluster de banco de dados do Aurora.
-
Não é possível criar o clone de um cluster de banco de dados do Aurora sem o recurso de consulta paralela para um cluster que usa consulta paralela. Para levar dados a um cluster que usa a consulta paralela, crie um snapshot do cluster original e restaure-o para um cluster que está usando o recurso de consulta paralela.
-
Não é possível criar um clone a partir de um cluster de banco de dados do Aurora que não tenha instâncias de banco de dados. Só é possível clonar clusters de banco de dados do Aurora com pelo menos uma instância de banco de dados.
-
É possível criar um clone em uma virtual private cloud (VPC) diferente da do cluster de banco de dados do Aurora. Nesse caso, as sub-redes dessas VPCs devem ser mapeadas mas mesmas zonas de disponibilidade.
-
É possível criar um clone provisionado do Aurora a partir de um cluster de banco de dados provisionado do Aurora.
-
Os clusters com instâncias do Aurora Serverless v2 seguem as mesmas regras que os clusters provisionados.
-
Para Aurora Serverless v1:
-
É possível criar um clone provisionado a partir de um cluster de banco de dados do Aurora Serverless v1.
-
É possível criar um clone do Aurora Serverless v1 de um cluster de banco de dados do provisionado ou do Aurora Serverless v1.
-
Não é possível criar um clone do Aurora Serverless v1 de um cluster de banco de dados provisionado do Aurora não criptografado.
-
No momento, a clonagem entre contas não é compatível com a clonagem de clusters de banco de dados do Aurora Serverless v1. Para ter mais informações, consulte Limitações da clonagem entre contas.
-
O cluster de banco de dados do Aurora Serverless v1 clonado tem o mesmo comportamento e limitações que qualquer cluster de banco de dados do Aurora Serverless v1. Para ter mais informações, consulte Usar o Amazon Aurora Serverless v1.
-
Os clusters de banco de dados do Aurora Serverless v1 são sempre criptografados Quando você clonar um banco de dados do Aurora Serverless v1 em um cluster de banco de dados provisionado do Aurora, o cluster de banco de dados do Aurora provisionado será criptografado. É possível escolher a chave de criptografia, mas não é possível desabilitar a criptografia. Para clonar de um cluster de banco de dados provisionado do Aurora para o Aurora Serverless v1, é necessário começar com um cluster de banco de dados provisionado do Aurora provisionado e criptografado.
-
Como a clonagem do Aurora funciona
A clonagem do Aurora funciona na camada de armazenamento de um cluster de banco de dados do Aurora. Utiliza um protocolo copy-on-write que é rápido e eficiente em termos de mídia durável subjacente compatível com o volume de armazenamento do Aurora. Saiba mais sobre os volumes de cluster do Aurora em Visão geral do armazenamento do Amazon Aurora.
Noções sobre o protocolo copy-on-write
Um cluster de banco de dados do Aurora armazena dados em páginas no volume de armazenamento subjacente do Aurora.
Por exemplo, no diagrama a seguir, você encontra um cluster de banco de dados do Aurora (A) que tem quatro páginas de dados: 1, 2, 3 e 4. Imagine que um clone, B é criado a partir do cluster de banco de dados do Aurora. Quando o clone é criado, nenhum dado é copiado. Em vez disso, o clone aponta para o mesmo conjunto de páginas que o cluster de banco de dados do Aurora de origem.
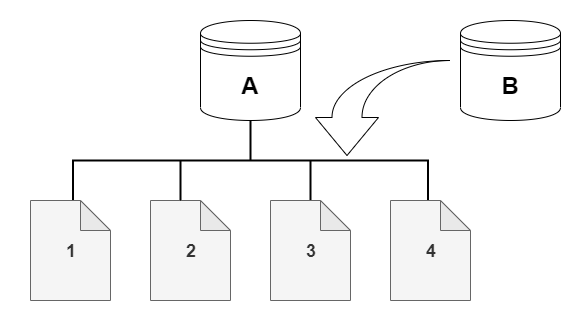
Quando o clone é criado, geralmente não é necessário armazenamento adicional. O protocolo copiar ao escrever usa o mesmo segmento na mídia de armazenamento física que no segmento de origem. O armazenamento adicional é necessário somente se a capacidade do segmento de origem não for suficiente para todo o segmento do clone. Se for esse o caso, o segmento de origem será copiado para outro dispositivo físico.
Nos diagramas a seguir, você encontra um exemplo do protocolo copy-on-write em ação usando o mesmo cluster A e seu clone (B), conforme mostrado anteriormente. Digamos que você faça uma alteração no cluster de banco de dados do Aurora (A) que resulte em uma alteração nos dados mantidos na página 1. Em vez de gravar na página original 1, o Aurora cria uma nova página 1[A]. O volume do cluster de banco de dados do Aurora para o cluster (A) agora aponta para a página 1[A], 2, 3 e 4, enquanto o clone (B) ainda faz referência às páginas originais.
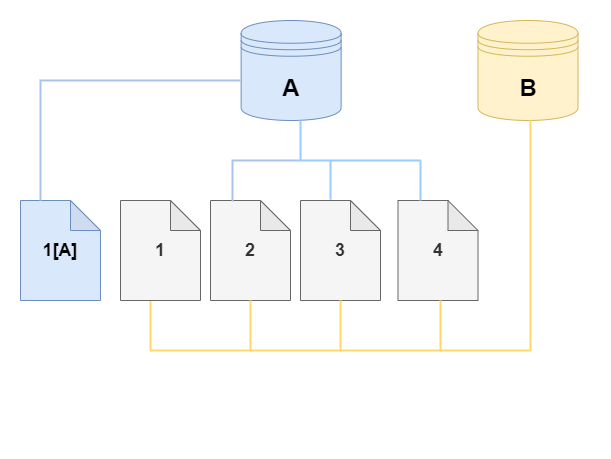
No clone, uma alteração é feita na página 4 no volume de armazenamento. Em vez de gravar na página original 4, o Aurora cria uma nova página 4[B]. O clone agora aponta para as páginas 1, 2, 3 e para a página 4[B], enquanto o cluster (A) continua apontando para 1[A], 2, 3 e 4.
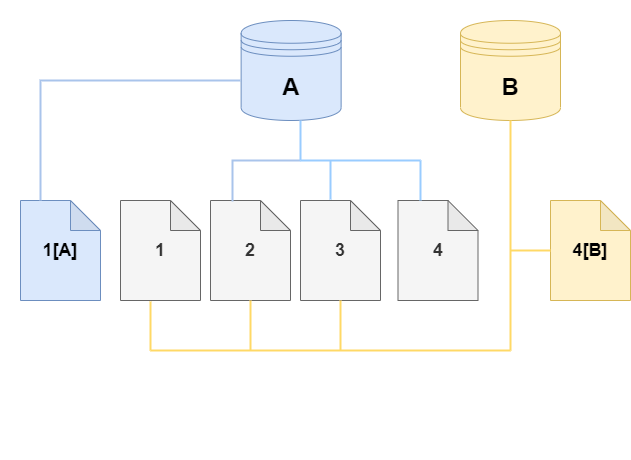
À medida que ocorrerem mais alterações ao longo do tempo no volume do cluster do Aurora original e no clone, será necessário mais armazenamento incremental para capturar e armazenar as alterações.
Excluir um volume de cluster de origem
Inicialmente, o volume do clone compartilha as mesmas páginas de dados do volume original com base no qual o clone foi criado. Enquanto o volume original existir, o volume do clone só será considerado o proprietário das páginas que o clone criou ou modificou. Assim, a métrica VolumeBytesUsed do volume do clone começa pequena e só cresce à medida que os dados divergem entre o cluster original e o clone. Em relação às páginas idênticas entre o volume de origem e o clone, as cobranças de armazenamento se aplicam somente ao cluster original. Para obter mais informações sobre métricas do VolumeBytesUsed, consulte Métricas no nível do cluster do Amazon Aurora.
Quando você exclui um volume do cluster de origem com um ou mais clones associados a ele, os dados nos volumes do cluster dos clones não são alterados. O Aurora preserva as páginas que pertenciam anteriormente ao volume do cluster de origem. O Aurora redistribui a cobrança de armazenamento das páginas que pertenciam ao cluster excluído. Por exemplo, suponha que um cluster original tenha dois clones e, depois, o cluster original seja excluído. Metade das páginas de dados pertencentes ao cluster original agora pertence a um clone. A outra metade das páginas pertence ao outro clone.
Se você excluir o cluster original, ao criar ou excluir mais clones, o Aurora continuará a redistribuir a propriedade das páginas de dados entre todos os clones que compartilham as mesmas páginas. Assim, talvez você descubra que o valor da métrica VolumeBytesUsed muda para o volume do cluster de um clone. O valor da métrica pode diminuir à medida que mais clones são criados e a propriedade das páginas é distribuída por mais clusters. O valor da métrica também pode aumentar à medida que os clones são excluídos e a propriedade das páginas é atribuída a um número menor de clusters. Para ter informações sobre como as operações de gravação afetam as páginas de dados em volumes de clones, consulte Noções sobre o protocolo copy-on-write.
Quando o cluster original e os clones pertencem à mesma conta da AWS, todas as cobranças de armazenamento desses clusters se aplicam à mesma conta da AWS. Se alguns dos clusters forem clones entre contas, a exclusão do cluster original poderá gerar cobranças adicionais de armazenamento para as contas da AWS que possuem os clones entre contas.
Por exemplo, suponha que um volume de cluster tenha mil páginas de dados usadas antes de você criar qualquer clone. Quando você clona esse cluster, inicialmente o volume do clone tem zero páginas utilizadas. Se o clone fizer modificações em cem páginas de dados, somente essas cem páginas serão armazenadas no volume do clone e marcadas como utilizadas. As outras novecentas páginas inalteradas do volume principal serão compartilhadas pelos dois clusters. Nesse caso, o cluster principal terá cobranças de armazenamento para mil páginas e o volume do clone para cem páginas.
Se você excluir o volume de origem, as cobranças de armazenamento do clone incluirão as cem páginas alteradas, além das novecentas páginas compartilhadas do volume original, totalizando mil páginas.
Criar um clone do Amazon Aurora
Você pode criar um clone na mesma conta da AWS que o cluster de banco de dados do Aurora de origem. Para fazer isso, você pode usar o AWS Management Console ou a AWS CLI e os procedimentos a seguir.
Para permitir que outra conta da AWS crie um clone ou compartilhar um clone com outra conta da AWS, use os procedimentos contidos em Clonar entre contas com o AWS RAM e Amazon Aurora.
O procedimento a seguir descreve como clonar um cluster de banco de dados do Aurora usando o AWS Management Console.
Criar um clone usando os resultados do AWS Management Console em um cluster de banco de dados do Aurora com uma instância de banco de dados do Aurora.
Essas instruções se aplicam a clusters de banco de dados que são da mesma conta da AWS que está criando o clone. Se o cluster de banco de dados for de uma conta da AWS diferente, consulte Clonar entre contas com o AWS RAM e Amazon Aurora.
Para criar um clone de um cluster de banco de dados da sua conta da AWS usando o AWS Management Console
Faça login no AWS Management Console e abra o console do Amazon RDS em https://console.aws.amazon.com/rds/
. No painel de navegação, escolha Databases (Bancos de dados).
Escolha seu cluster de banco de dados do Aurora na lista e em Actions (Ações), escolha Create clone (Criar clone).
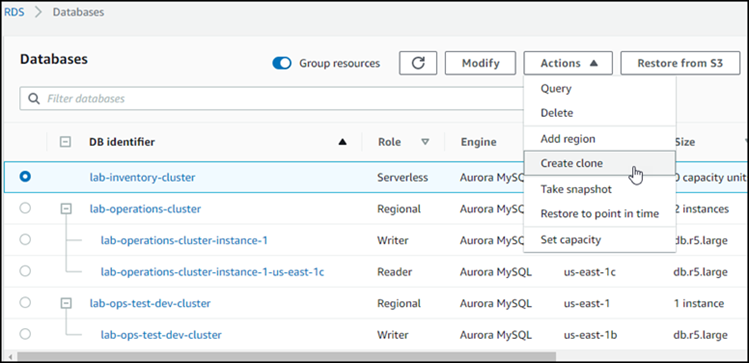
Abre-se a página Criar clone, onde é possível definir Configurações, Conectividade e outras opções para o clone de cluster de banco de dados do Aurora.
-
Em Identificador da instância de banco de dados, insira o nome que você deseja dar ao cluster de banco de dados clonado do Aurora.
Para clusters de banco de dados do Aurora Serverless v1, selecione Provisionado ou Sem servidor para Tipo de capacidade.
Só será possível escolher Serverless (Sem servidor) se o cluster de banco de dados do Aurora de origem for um cluster de banco de dados do Aurora Serverless v1 ou um cluster de banco de dados do Aurora provisionado criptografado.
-
Para clusters de banco de dados provisionados ou do Aurora Serverless v2, selecione Aurora I/O-Optimized ou Aurora Standard para Configuração do armazenamento em cluster.
Para ter mais informações, consulte Configurações de armazenamento para clusters de banco de dados do Amazon Aurora.
-
Escolha o tamanho da instância de banco de dados ou a capacidade do cluster de banco de dados:
-
Para um clone provisionado, selecione uma Classe da instância de banco de dados.
Você pode aceitar a configuração fornecida ou usar uma classe de instância de banco de dados diferente para o clone.
-
Para um clone do Aurora Serverless v1 ou do Aurora Serverless v2, selecione as Configurações de capacidade.
É possível aceitar as configurações fornecidas ou alterá-las para o clone.
-
-
Selecione outras configurações, conforme necessário, para o clone. Para saber mais sobre as configurações de cluster e instância de banco de dados do Aurora, consulte Criar um cluster de bancos de dados do Amazon Aurora.
-
Selecione Criar clone.
Ao ser criado, o clone é listado com seus outros clusters de banco de dados Aurora na seção Databases (Bancos de dados) do console e exibe seu estado atual. O clone está pronto para uso quando o estado é Available (Disponível).
Usar a AWS CLI para clonar o cluster de banco de dados do Aurora envolve etapas separadas para criar o cluster clonado e adicionar uma ou mais instâncias de banco de dados a ele.
O comando restore-db-cluster-to-point-in-time da AWS CLI utilizado gera um cluster de banco de dados do Aurora com os mesmos dados de armazenamento que o cluster original, mas não instâncias de banco de dados do Aurora. Será necessário criar as instâncias de banco de dados separadamente após o clone ficar disponível. É possível selecionar o número de instâncias de banco de dados e suas classes de instância para dar ao clone mais ou menos capacidade computacional do que o cluster original. As etapas do processo são as seguintes:
-
Crie o clone usando o comando restore-db-cluster-to-pontual da CLI.
-
Crie a instância de banco de dados de gravador para o clone usando o comado create-db-instance da CLI.
-
(Opcional) Execute comandos adicionais create-db-instance da CLI para adicionar uma ou mais instâncias de leitor ao cluster clonado. O uso de instâncias de leitor ajuda a melhorar os aspectos de alta disponibilidade e escalabilidade de leitura do clone. É possível ignorar essa etapa caso você pretenda usar o clone apenas para desenvolvimento e teste.
Tópicos
Criar o clone
Use o comando restore-db-cluster-to-point-in-time da CLI para criar o cluster clonado inicial.
Como criar um clone do cluster de banco de dados do Aurora original
-
Use o comando de CLI de
restore-db-cluster-to-point-in-time. Especifique os valores para os parâmetros a seguir. Nesse caso típico, o clone usa o mesmo modo de mecanismo do cluster original, provisionado ou o Aurora Serverless v1.-
--db-cluster-identifier— escolha um nome significativo para o clone. Nomeie o clone ao usar o comando restore-db-cluster-to-point-in-time da CLI. Em seguida, passe o nome do clone no comando create-db-instance da CLI. -
--restore-type: usecopy-on-writepara criar um clone do cluster de banco de dados de origem Sem esse parâmetro,restore-db-cluster-to-point-in-timerestaura o cluster de banco de dados do Aurora em vez de criar um clone. -
--source-db-cluster-identifier: use o nome do cluster de banco de dados do Aurora de origem que você deseja clonar. -
--use-latest-restorable-time: esse valor aponta para dados de volume restauráveis mais recentes para o cluster de banco de dados de origem. Use-o para criar clones.
-
O exemplo a seguir mostra a criação de um clone chamado my-clone a partir de um cluster chamado my-source-cluster.
Para Linux, macOS ou Unix:
aws rds restore-db-cluster-to-point-in-time \ --source-db-cluster-identifiermy-source-cluster\ --db-cluster-identifiermy-clone\ --restore-type copy-on-write \ --use-latest-restorable-time
Para Windows:
aws rds restore-db-cluster-to-point-in-time ^ --source-db-cluster-identifiermy-source-cluster^ --db-cluster-identifiermy-clone^ --restore-type copy-on-write ^ --use-latest-restorable-time
O comando retorna o objeto JSON que contém detalhes do clone. Verifique se o cluster de banco de dados clonado está disponível antes de tentar criar a instância de banco de dados para o clone. Para ter mais informações, consulte Verificar o status e obter detalhes do clone.
Por exemplo, suponha que você tenha um cluster chamado tpch100g que deseja clonar. O exemplo do Linux a seguir cria um cluster clonado chamado tpch100g-clone, uma instância de gravador do Aurora Serverless v2 denominada tpch100g-clone-instance e uma instância de leitor provisionada denominada tpch100g-clone-instance-2 para o novo cluster.
Não é necessário fornecer alguns parâmetros, como --master-username e --master-user-password. O Aurora determina automaticamente os parâmetros do cluster original. Você precisa especificar o mecanismo de banco de dados a ser usado. Assim, o exemplo testa o novo cluster para determinar o valor certo a ser usado para o parâmetro --engine.
Esse exemplo também inclui a opção --serverless-v2-scaling-configuration ao criar o cluster clonado. Dessa forma, é possível adicionar instâncias do Aurora Serverless v2 ao clone mesmo que o cluster original não tenha usado o Aurora Serverless v2.
$aws rds restore-db-cluster-to-point-in-time \ --source-db-cluster-identifier tpch100g \ --db-cluster-identifier tpch100g-clone \ --serverless-v2-scaling-configuration MinCapacity=0.5,MaxCapacity=16\ --restore-type copy-on-write \ --use-latest-restorable-time$aws rds describe-db-clusters \ --db-cluster-identifier tpch100g-clone \ --query '*[].[Engine]' \ --output textaurora-mysql$aws rds create-db-instance \ --db-instance-identifier tpch100g-clone-instance \ --db-cluster-identifier tpch100g-clone \ --db-instance-class db.serverless \ --engine aurora-mysql$aws rds create-db-instance \ --db-instance-identifier tpch100g-clone-instance-2 \ --db-cluster-identifier tpch100g-clone \ --db-instance-class db.r6g.2xlarge \ --engine aurora-mysql
Como criar um clone com um modo de mecanismo diferente do cluster de banco de dados do Aurora original
-
Este procedimento só se aplica a versões mais antigas do mecanismo que comportam o Aurora Serverless v1. Suponha que você tenha um cluster do Aurora Serverless v1 e queira criar um clone que seja um cluster provisionado. Nesse caso, use o comando
restore-db-cluster-to-point-in-timeda CLI e especifique valores de parâmetros semelhantes aos do exemplo anterior, além destes parâmetros adicionais:-
--engine-mode: use esse parâmetro somente para criar clones de um modo de mecanismo diferente do cluster de banco de dados do Aurora de origem. Esse parâmetro só se aplica a versões mais antigas do mecanismo que comportam o Aurora Serverless v1. Escolha o valor para passar com--engine-mode, desta maneira:-
Use
--engine-mode provisionedpara criar um clone de cluster de banco de dados do Aurora provisionado a partir de um cluster de banco de dados do Aurora Serverless.nota
Se pretende usar o Aurora Serverless v2 com um cluster clonado do Aurora Serverless v1, especifique o modo de mecanismo para o clone como
provisioned. Depois, execute etapas adicionais de atualização e migração. -
Use
--engine-mode serverlesspara criar um clone do Aurora Serverless v1 de um cluster de banco de dados do Aurora provisionado. Ao especificar o modo de mecanismoserverless, você também pode escolher a--scaling-configuration.
-
-
--scaling-configuration: (opcional) use com--engine-mode serverlesspara configurar a capacidade mínima e máxima de um clone do Aurora Serverless v1. Se você não usar esse parâmetro, o Aurora criará um clone do Aurora Serverless v1 usando os valores de capacidade do Aurora Serverless v1 padrão para o mecanismo de banco de dados.
-
O exemplo a seguir cria um clone provisionado denominado my-clone, de um cluster de banco de dados do Aurora Serverless v1 chamado my-source-cluster.
Para Linux, macOS ou Unix:
aws rds restore-db-cluster-to-point-in-time \ --source-db-cluster-identifiermy-source-cluster\ --db-cluster-identifiermy-clone\ --engine-mode provisioned \ --restore-type copy-on-write \ --use-latest-restorable-time
Para Windows:
aws rds restore-db-cluster-to-point-in-time ^ --source-db-cluster-identifiermy-source-cluster^ --db-cluster-identifiermy-clone^ --engine-mode provisioned ^ --restore-type copy-on-write ^ --use-latest-restorable-time
Esses comandos retornam o objeto JSON que contém detalhes do clone necessário para criar a instância de banco de dados. Não é possível fazer isso até que o status do clone (o cluster de banco de dados do Aurora vazio) tenha o status Available (Disponível).
nota
O comando restore-db-cluster-to-point-in-time da AWS CLI restaura apenas o cluster de banco de dados, e não as instâncias de banco de dados para esse cluster de banco de dados. Execute o comando create-db-instance para criar instâncias de banco de dados para o cluster de banco de dados restaurado. Com esse comando, especifique o identificador do cluster de banco de dados restaurado como o parâmetro --db-cluster-identifier. Você pode criar instâncias de banco de dados somente após o comando restore-db-cluster-to-point-in-time tiver sido concluído e o cluster de banco de dados estiver disponível.
Suponha que você comece com um cluster do Aurora Serverless v1 e pretenda migrá-lo para um cluster do Aurora Serverless v2. Crie um clone provisionado do cluster do Aurora Serverless v1 como a etapa inicial da migração. Para ver o procedimento completo, incluindo todas as atualizações de versão necessárias, consulte Atualizar a partir de um cluster do Aurora Serverless v1 para o Aurora Serverless v2.
Verificar o status e obter detalhes do clone
É possível usar o comando a seguir para conferir o status do cluster clonado recém-criado.
$aws rds describe-db-clusters --db-cluster-identifiermy-clone--query '*[].[Status]' --output text
Ou você pode obter o status e os outros valores necessários para criar a instância de banco de dados para seu clone usando a seguinte consulta da AWS CLI.
Para Linux, macOS ou Unix:
aws rds describe-db-clusters --db-cluster-identifiermy-clone\ --query '*[].{Status:Status,Engine:Engine,EngineVersion:EngineVersion,EngineMode:EngineMode}'
Para Windows:
aws rds describe-db-clusters --db-cluster-identifiermy-clone^ --query "*[].{Status:Status,Engine:Engine,EngineVersion:EngineVersion,EngineMode:EngineMode}"
Essa consulta retorna uma saída semelhante à saída abaixo.
[ { "Status": "available", "Engine": "aurora-mysql", "EngineVersion": "8.0.mysql_aurora.3.04.1", "EngineMode": "provisioned" } ]
Criar a instância de banco de dados do Aurora para seu clone
Use o comando create-db-instance da CLI para criar a instância de banco de dados para o clone do Aurora Serverless v2 ou provisionado. Não crie uma instância de banco de dados para um clone do Aurora Serverless v1.
A instância de banco de dados herda as propriedades --master-username e --master-user-password do cluster de banco de dados de origem.
O exemplo a seguir cria uma instância de banco de dados para o clone provisionado.
Para Linux, macOS ou Unix:
aws rds create-db-instance \ --db-instance-identifiermy-new-db\ --db-cluster-identifiermy-clone\ --db-instance-classdb.r6g.2xlarge\ --engine aurora-mysql
Para Windows:
aws rds create-db-instance ^ --db-instance-identifiermy-new-db^ --db-cluster-identifiermy-clone^ --db-instance-classdb.r6g.2xlarge^ --engine aurora-mysql
O exemplo a seguir cria uma instância de banco de dados do Aurora Serverless v2 para um clone que usa uma versão de mecanismo compatível com o Aurora Serverless v2.
Para Linux, macOS ou Unix:
aws rds create-db-instance \ --db-instance-identifiermy-new-db\ --db-cluster-identifiermy-clone\ --db-instance-class db.serverless \ --engine aurora-postgresql
Para Windows:
aws rds create-db-instance ^ --db-instance-identifiermy-new-db^ --db-cluster-identifiermy-clone^ --db-instance-class db.serverless ^ --engine aurora-mysql
Parâmetros a serem usados para clonagem
A tabela a seguir resume os vários parâmetros usados com restore-db-cluster-to-point-in-timepara clonar clusters de banco de dados do Aurora.
| Parâmetro | Descrição |
|---|---|
|
|
Use o nome do cluster de banco de dados do Aurora original que você deseja clonar. |
|
|
Selecione um nome significativo para o clone ao criá-lo com o comando |
|
|
Especifique |
|
|
Esse valor aponta para os dados de volume restauráveis mais recentes para o cluster de banco de dados de origem. Use-o para criar clones. |
|
|
(Versões mais recentes que comportam o Aurora Serverless v2) Use esse parâmetro para configurar a capacidade mínima e máxima de um clone do Aurora Serverless v2. Se você não especificar esse parâmetro, não poderá criar nenhuma instância do Aurora Serverless v2 no cluster do clone até modificar o cluster para adicionar esse atributo. |
|
|
(Somente versões mais antigas que comportam o Aurora Serverless v1) Use esse parâmetro para criar clones de um tipo diferente do cluster de banco de dados do Aurora de origem, com um dos seguintes valores:
|
|
|
(Somente versões mais antigas que comportam o Aurora Serverless v1) Use esse parâmetro para configurar a capacidade mínima e máxima de um clone do Aurora Serverless v1. Se você não especificar esse parâmetro, o Aurora criará o clone usando os valores de capacidade padrão para o mecanismo de banco de dados. |
Para ter informações sobre clonagem entre VPCs e entre contas, consulte as seções a seguir.
