Ajustar parâmetros de memória para o Aurora PostgreSQL
No Amazon Aurora PostgreSQL, você pode usar vários parâmetros que controlam a quantidade de memória usada para várias tarefas de processamento. Se uma tarefa consumir mais memória do que a quantidade definida para um determinado parâmetro, o Aurora PostgreSQL usa outros recursos para processamento, como gravação em disco. Isso pode fazer com que o cluster de banco de dados do Aurora PostgreSQL fique lento ou possivelmente seja interrompido, com um erro de falta de memória.
A configuração padrão para cada parâmetro de memória geralmente pode lidar com as tarefas de processamento pretendidas. No entanto, você também pode ajustar os parâmetros relacionados à memoria no cluster de banco de dados do Aurora PostgreSQL. Você pode fazer esse ajuste para garantir que seja alocada memória suficiente seja para processar sua workload específica.
A seguir, você encontrará informações sobre parâmetros que controlam o gerenciamento da memória. Você também pode aprender a avaliar a utilização da memória.
Verificar e definir valores de parâmetros
Os parâmetros que você pode definir para gerenciar a memória e avaliar o uso de memória do cluster de banco de dados do Aurora PostgreSQL incluem o seguinte:
work_mem: especifica a quantidade de memória que o cluster de banco de dados do Aurora PostgreSQL usa para operações de classificação internas e tabelas de hash antes da gravação em arquivos temporários de disco.log_temp_files: registra em log a criação, os nomes e os tamanhos dos arquivos temporários. Quando esse parâmetro é ativado, uma entrada de registro em log é armazenada para cada arquivo temporário criado. Ative-o para ver com que frequência o cluster de banco de dados do Aurora PostgreSQL precisa gravar em disco. Desative-o novamente depois de coletar informações sobre a geração de arquivos temporários do cluster de banco de dados do Aurora PostgreSQL, para evitar registros em log excessivos.logical_decoding_work_mem: especifica a quantidade de memória (em quilobytes) a ser usada por cada buffer de reordenamento interno antes da transferência para o disco. Essa memória é usada para decodificação lógica, que é o processo usado para criar uma réplica. Isso é feito por meio da conversão de dados do arquivo de log de gravação antecipada (WAL) na saída lógica do streaming necessária para o destino.O valor desse parâmetro cria um único buffer do tamanho especificado para cada conexão de replicação. Por padrão, é 65.536 KB. Depois que esse buffer é preenchido, o excesso é gravado em disco como arquivo. Para minimizar a atividade do disco, você pode ajustar o valor desse parâmetro como um valor bem maior que
work_mem.
Como todos eles são parâmetros dinâmicos, você pode alterá-los para a sessão atual. Para fazer isso, conecte-se ao cluster de banco de dados do Aurora PostgreSQL com psql e usando a instrução SET, conforme mostrado a seguir.
SET parameter_name TO parameter_value;As configurações da sessão duram apenas na sessão. Quando a sessão termina, o parâmetro é revertido para a respectiva configuração no grupo de parâmetros do cluster de banco de dados. Antes de alterar qualquer parâmetro, primeiro verifique os valores atuais consultando a tabela pg_settings, da maneira a seguir.
SELECT unit, setting, max_val FROM pg_settings WHERE name='parameter_name';
Por exemplo, para encontrar o valor do parâmetro work_mem, conecte-se à instância do gravador do cluster de banco de dados do Aurora PostgreSQL e execute a consulta a seguir.
SELECT unit, setting, max_val, pg_size_pretty(max_val::numeric) FROM pg_settings WHERE name='work_mem';unit | setting | max_val | pg_size_pretty ------+----------+-----------+---------------- kB | 1024 | 2147483647| 2048 MB (1 row)
Alterar as configurações dos parâmetros para que persistam exige o uso de um grupo de parâmetros do cluster de banco de dados. Depois de executar seu cluster de banco de dados do Aurora PostgreSQL com valores diferentes para esses parâmetros usando a instrução SET, você pode criar um grupo personalizado de parâmetros e aplicar ao seu cluster de banco de dados do Aurora PostgreSQL. Para ter mais informações, consulte Grupos de parâmetros para Amazon Aurora.
Entender o parâmetro da memória de trabalho
O parâmetro da memória de trabalho (work_mem) especifica a quantidade máxima de memória que o Aurora PostgreSQL pode usar para processar consultas complexas. As consultas complexas incluem as que envolvem operações de classificação ou agrupamento, ou seja, consultas que usam as seguintes cláusulas:
ORDER BY
DISTINCT
GROUP BY
JOIN (MERGE e HASH)
O planejador de consultas afeta indiretamente a forma como seu cluster de banco de dados do Aurora PostgreSQL usa a memória de trabalho. O planejador de consultas gera planos de execução para processar instruções SQL. Um plano específico pode dividir uma consulta complexa em várias unidades de trabalho que podem ser executadas em paralelo. Quando possível, o Aurora PostgreSQL usa a quantidade de memória especificada no parâmetro work_mem referente a cada sessão antes de gravar em disco para cada processo paralelo.
Vários usuários do banco de dados que executam várias operações simultaneamente e geram várias unidades de trabalho em paralelo podem esgotar a memória de trabalho alocada do seu cluster de banco de dados do Aurora PostgreSQL. Isso pode levar à criação excessiva de arquivos temporários e à E/S de disco ou, pior ainda, a um erro de falta de memória.
Identificar o uso temporário de arquivos
Sempre que a memória necessária para processar consultas exceder o valor especificado no parâmetro work_mem, os dados de trabalho serão transferidos para o disco em um arquivo temporário. Você pode ver com que frequência isso ocorre ativando o parâmetro log_temp_files. Por padrão, o parâmetro está desativado (definido como -1). Para capturar todas as informações do arquivo temporário, defina esse parâmetro como 0. Defina log_temp_files como qualquer outro número inteiro positivo a fim de capturar informações de arquivos temporários para arquivos iguais ou maiores que essa quantidade de dados (em quilobytes). Na imagem a seguir, você pode ver um exemplo de AWS Management Console.
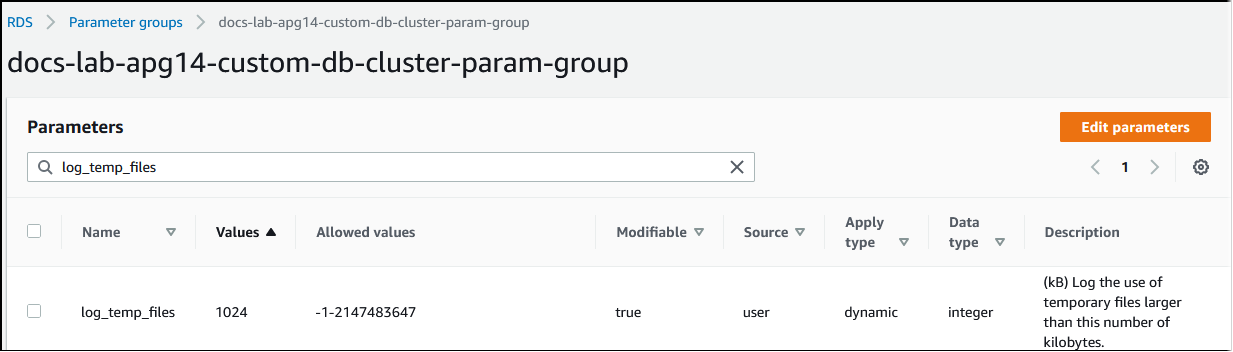
Depois de configurar o registro em log de arquivos temporários, você pode testar com sua própria workload para ver se a configuração da memória de trabalho é suficiente. Você também pode simular uma workload usando o pgbench, uma aplicação simples de comparação da comunidade do PostgreSQL.
O exemplo a seguir inicializa (-i) pgbench criando as tabelas e linhas necessárias para executar os testes. Neste exemplo, o fator de escalabilidade (-s 50) cria 50 linhas na tabela pgbench_branches, 500 linhas em pgbench_tellers e 5 milhões de linhas na tabela pgbench_accounts no banco de dados labdb.
pgbench -U postgres -h your-cluster-instance-1.111122223333.aws-regionrds.amazonaws.com -p 5432 -i -s 50 labdb
Password:
dropping old tables...
NOTICE: table "pgbench_accounts" does not exist, skipping
NOTICE: table "pgbench_branches" does not exist, skipping
NOTICE: table "pgbench_history" does not exist, skipping
NOTICE: table "pgbench_tellers" does not exist, skipping
creating tables...
generating data (client-side)...
5000000 of 5000000 tuples (100%) done (elapsed 15.46 s, remaining 0.00 s)
vacuuming...
creating primary keys...
done in 61.13 s (drop tables 0.08 s, create tables 0.39 s, client-side generate 54.85 s, vacuum 2.30 s, primary keys 3.51 s)Depois de inicializar o ambiente, você pode executar a comparação para um período específico (-T) e o número de clientes (-c). Esse exemplo também usa a opção -d para gerar informações de depuração à medida que as transações são processadas pelo cluster de banco de dados do Aurora PostgreSQL.
pgbench -h -U postgresyour-cluster-instance-1.111122223333.aws-regionrds.amazonaws.com -p 5432 -d -T 60 -c 10labdbPassword:*******pgbench (14.3) starting vacuum...end. transaction type: <builtin: TPC-B (sort of)> scaling factor: 50 query mode: simple number of clients: 10 number of threads: 1 duration: 60 s number of transactions actually processed: 1408 latency average = 398.467 ms initial connection time = 4280.846 ms tps = 25.096201 (without initial connection time)
Para obter mais informações sobre o pg_upgrade, consulte pgbench
Você pode usar o comando de metacomando do psql (\d) para listar as relações, como tabelas, visualizações e índices criados pelo pgbench.
labdb=>\d pgbench_accountsTable "public.pgbench_accounts" Column | Type | Collation | Nullable | Default ----------+---------------+-----------+----------+--------- aid | integer | | not null | bid | integer | | | abalance | integer | | | filler | character(84) | | | Indexes: "pgbench_accounts_pkey" PRIMARY KEY, btree (aid)
Conforme mostrado na saída, a tabela pgbench_accounts está indexada na coluna aid. Para garantir que a próxima consulta use a memória de trabalho, consulte qualquer coluna não indexada, como a mostrada no exemplo a seguir.
postgres=>SELECT * FROM pgbench_accounts ORDER BY bid;
Verifique se há arquivos temporários no log. Para fazer isso, abra o AWS Management Console, escolha a instância do cluster de banco de dados do Aurora PostgreSQL e selecione a guia Logs & Events (Registros em log e eventos). Visualize os logs no console ou baixe-os para análise posterior. Conforme mostrado na imagem a seguir, o tamanho dos arquivos temporários necessários para processar a consulta indica que você deve considerar aumentar a quantidade especificada para o parâmetro work_mem.

Você pode configurar esse parâmetro de forma diferente para indivíduos e grupos, com base em suas necessidades operacionais. Por exemplo, você pode ajustar o parâmetro work_mem como 8 GB para a função chamada dev_team.
postgres=>ALTER ROLEdev_teamSET work_mem=‘8GB';
Com essa definição para work_mem, são alocados até 8 GB de memória de trabalho a qualquer função membro da função dev_team.
Usar índices para um tempo de resposta mais rápido
Se suas consultas estiverem demorando muito para retornar resultados, você pode verificar se seus índices estão sendo usados conforme o esperado. Primeiro, ative \timing, o metacomando psql, da seguinte maneira.
postgres=>\timing on
Depois de ativar o tempo, use uma instrução SELECT simples.
postgres=>SELECT COUNT(*) FROM (SELECT * FROM pgbench_accounts ORDER BY bid) AS accounts;count ------- 5000000 (1 row) Time: 3119.049 ms (00:03.119)
Conforme mostrado na saída, essa consulta levou pouco mais de 3 segundos para ser concluída. Para melhorar o tempo de resposta, crie um índice em pgbench_accounts, da maneira a seguir.
postgres=>CREATE INDEX ON pgbench_accounts(bid);CREATE INDEX
Execute a consulta novamente e observe o tempo de resposta mais rápido. Neste exemplo, a consulta foi concluída cerca de cinco vezes mais rápido, em aproximadamente meio segundo.
postgres=>SELECT COUNT(*) FROM (SELECT * FROM pgbench_accounts ORDER BY bid) AS accounts;count ------- 5000000 (1 row) Time: 567.095 ms
Ajustar a memória de trabalho para decodificação lógica
A replicação lógica está disponível em todas as versões do Aurora PostgreSQL desde sua introdução no PostgreSQL versão 10. Ao configurar a replicação lógica, você também pode definir o parâmetro logical_decoding_work_mem para especificar a quantidade de memória que o processo lógico de decodificação pode usar para o processo de decodificação e streaming.
Durante a decodificação lógica, os registros de log de gravação antecipada (WAL) são convertidos em instruções SQL que são então enviadas para outro destino para replicação lógica ou outra tarefa. Quando uma transação é gravada no WAL e depois convertida, toda a transação deve caber no valor especificado para logical_decoding_work_mem. Por padrão, esse parâmetro é definido como 65.536 KB. Qualquer excesso é gravado em disco. Isso significa que ele deve ser lido novamente do disco antes de ser enviado para seu destino, desacelerando assim o processo geral.
Você pode avaliar a quantidade de excesso de transações em sua workload atual em um momento específico usando a função aurora_stat_file conforme mostrado no exemplo a seguir.
SELECT split_part (filename, '/', 2) AS slot_name, count(1) AS num_spill_files, sum(used_bytes) AS slot_total_bytes, pg_size_pretty(sum(used_bytes)) AS slot_total_size FROM aurora_stat_file() WHERE filename like '%spill%' GROUP BY 1;slot_name | num_spill_files | slot_total_bytes | slot_total_size ------------+-----------------+------------------+----------------- slot_name | 590 | 411600000 | 393 MB (1 row)
Essa consulta retorna a contagem e o tamanho dos arquivos de despejo no seu cluster de banco de dados do Aurora PostgreSQL quando a consulta é invocada. Workloads de longa duração podem ainda não ter nenhum arquivo de despejo em disco. Para traçar o perfil de workloads de longa duração, recomendamos criar uma tabela para capturar as informações do arquivo de despejo à medida que a workload é executada. Você pode criar a tabela da seguinte maneira.
CREATE TABLE spill_file_tracking AS SELECT now() AS spill_time,* FROM aurora_stat_file() WHERE filename LIKE '%spill%';
Para ver como os arquivos de despejo são usados durante a replicação lógica, configure um editor e um assinante e inicie uma replicação simples. Para ter mais informações, consulte Configurar a replicação lógica para seu cluster de banco de dados do Aurora PostgreSQL. Com a replicação em andamento, você pode criar um trabalho que capture o conjunto de resultados da função de arquivo de despejo aurora_stat_file(), da maneira a seguir.
INSERT INTO spill_file_tracking SELECT now(),* FROM aurora_stat_file() WHERE filename LIKE '%spill%';
Use o comando psql a seguir para executar o trabalho uma vez por segundo.
\watch 0.5
Enquanto o trabalho estiver em execução, conecte-se à instância do gravador com base em outra sessão psql. Use a série de instruções a seguir para executar uma workload que exceda a configuração da memória e faça com que o Aurora PostgreSQL crie um arquivo de despejo.
labdb=>CREATE TABLE my_table (a int PRIMARY KEY, b int);CREATE TABLElabdb=>INSERT INTO my_table SELECT x,x FROM generate_series(0,10000000) x;INSERT 0 10000001labdb=>UPDATE my_table SET b=b+1;UPDATE 10000001
O processo pode demorar vários minutos para ser concluído. Ao terminar, pressione a tecla Ctrl e a tecla C ao mesmo tempo para interromper a função de monitoramento. Depois, use o comando a seguir para criar uma tabela a fim de armazenar as informações sobre o uso do arquivo de despejo do cluster de banco de dados do Aurora PostgreSQL.
SELECT spill_time, split_part (filename, '/', 2) AS slot_name, count(1) AS spills, sum(used_bytes) AS slot_total_bytes, pg_size_pretty(sum(used_bytes)) AS slot_total_size FROM spill_file_tracking GROUP BY 1,2 ORDER BY 1;spill_time | slot_name | spills | slot_total_bytes | slot_total_size ------------------------------+-----------------------+--------+------------------+----------------- 2022-04-15 13:42:52.528272+00 | replication_slot_name | 1 | 142352280 | 136 MB 2022-04-15 14:11:33.962216+00 | replication_slot_name | 4 | 467637996 | 446 MB 2022-04-15 14:12:00.997636+00 | replication_slot_name | 4 | 569409176 | 543 MB 2022-04-15 14:12:03.030245+00 | replication_slot_name | 4 | 569409176 | 543 MB 2022-04-15 14:12:05.059761+00 | replication_slot_name | 5 | 618410996 | 590 MB 2022-04-15 14:12:07.22905+00 | replication_slot_name | 5 | 640585316 | 611 MB (6 rows)
O resultado mostra que a execução do exemplo criou cinco arquivos de despejo que usaram 611 MB de memória. Para evitar a gravação em disco, recomendamos definir o parâmetro logical_decoding_work_mem com o maior tamanho de memória subsequente, 1.024.
